DTM: новая аппаратная архитектура снижает энергопотребление до 10000 раз по сравнению с GPU
1 ноября 2025
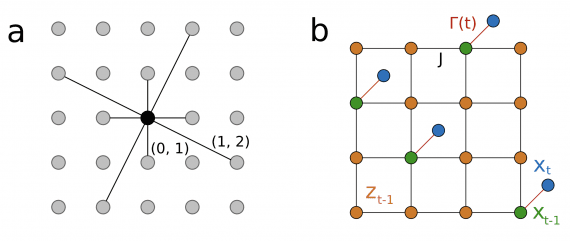
DTM: новая аппаратная архитектура снижает энергопотребление до 10000 раз по сравнению с GPU
Исследователи из Extropic Corporation представили эффективную аппаратную архитектуру для вероятностных вычислений, основанную на Denoising Thermodynamic Models (DTM). Анализ показывает, что устройства на базе этой архитектуры могут достичь паритета производительности с…