MegatronLM — это языковая модель с 8.3 миллиардами параметров, которую в Nvidia обучили на 512 GPU. MegatronLM основывается на GPT-2. По размеру MegatronLM больше BERT в 24 раза и больше GPT-2 в 5.6 раз. На текущий момент это самая крупная обученная языковая модель.Разработчики опубликовали распараллеленную реализацию модели.
Большие языковые модели показывают лучшие результаты на таких на задачах генерации текста. Обучение большой нейросети для NLP задач показало значительное увеличение в качестве предсказаний. Две последние работы, — BERT и GPT-2, — иллюстрируют преимущества крупномасштабных нейросетей для решения NLP задач. Обучение таких моделей требует сотни эксафлопсов вычислений и осторожную работу с памятью. Несмотря на это, для моделей с более чем миллиардом параметров памяти одного GPU не хватает. Это требует распараллелить процесс обучения таких моделей, чтобы распределить вычисления на несколько GPU. Существующие подходы к параллелизации моделей сложны в использовании. В MegatronLM разработчики реализовали распараллеленную языковую модель на PyTorch. Для параллелизации была использована библиотека NCCL.
Дизайн экспериментов
Эксперименты проводились на NVIDIA’s DGX SuperPOD. Без распараллеливания модели одна модель с 1.2 миллиардами параметров вмещалась на одну V100 32GB GPU. Базовая модель тратила 39 терафлопс на обучение. После масштабирования модели до 8.3 миллиардов параметров на 512 GPU она требовала 15.1 петафлопс на обучение. Это на 76% более эффективная реализация, чем базовая модель с 1 GPU.
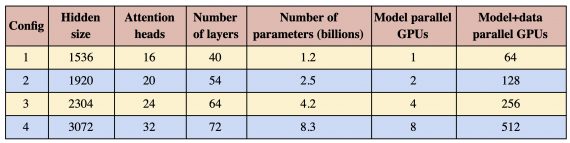
Обучение GPT-2
В качестве данных для обучения модели был собран датасет постов с Reddit. Размер датасета составил 37 гигабайт. Всего в выборке было 8.1 миллионов постов.
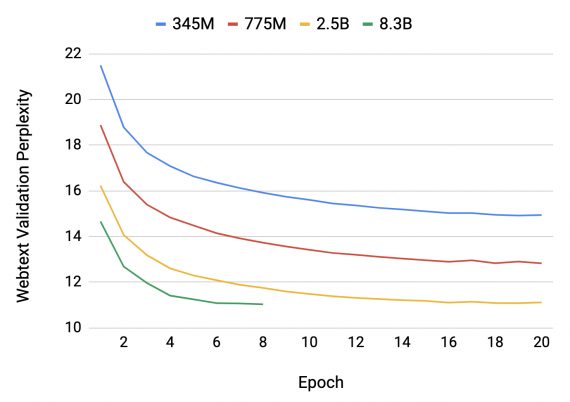
Исследователи смотрели на точность и перплексию моделей с разными параметрами. Ниже можно видеть, что модели с 2.5 и 8.3 миллиардами параметров практически не отличаются по метрикам.