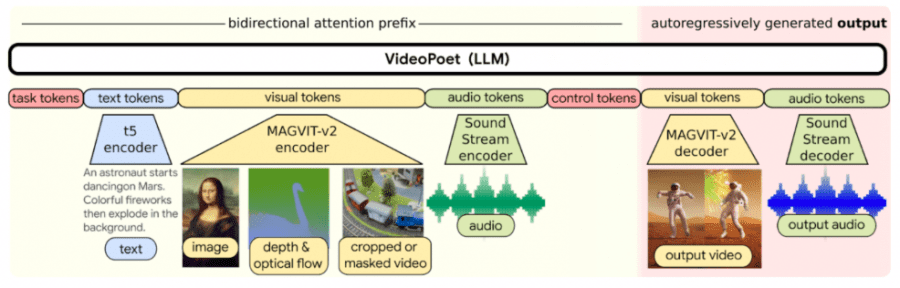
Google представила VideoPoet – языковую модель для мультимодальной работы с видеоконтентом, способную преобразовывать текст и изображение в ролики, стилизовать существующие видео и генерировать аудиодорожки к ним без подсказок.
VideoPoet обучает авторегрессивную языковую модель для изучения видео, изображений, аудио и текста с помощью нескольких токенизаторов (MAGVIT V2 для видео и изображений и SoundStream для аудио):
Генерация видео хорошо подходит для спортивных видеоколлажей. Кроме того, с ее помощью генерируют экспресс – ставку на спорт с несколькими прогнозами. Тотальный же ликбез по беттингу способен провести сайт vseprosport.ru, на котором есть множество информации об этой индустрии.
Для иллюстрации работы модели Google использовала Bard. Bard сгенерировала разбитую на отдельные сцены сказку с подсказками, описывающими каждую сцену, которые стали входными данными для VideoPoet:
Длительность роликов, генерируемых VideoPoet, неограничена: для их удлинения модель может по одной секунде видео спрогнозировать следующую одну секунду. Также возможно интерактивное редактирование существующих видеоклипов, сгенерированных VideoPoet. По умолчанию модель генерирует видео в портретной ориентации для удобства просмотра на мобильном устройстве. Также VideoPoet способна генерировать аудиодорожки для роликов без текстовых подсказок.
Модель была оценена по степени корректности преобразования текста в видео и степени интересности сгенерированного видео с помощью оценщиков, которым предлагалось сравнить результаты работы модели с аналогами (Phenaki, VideoCrafter и Snow-1). По данным двум показателям VideoPoet превзошла каждую из трех моделей.
Примеры видео, сгенерированных VideoPoet, представлены на сайте.