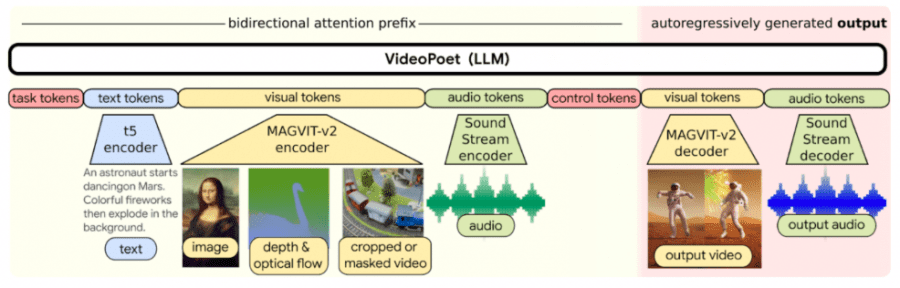
Google has unveiled VideoPoet, a language model for multimodal video content processing capable of turning text and images into clips, styling pre-existing videos, and generating soundtrack for them without any prompts. Firstly, VideoPoet leverages an autoregressive language model to study videos, images, audio, and text by utilizing various tokenizers (MAGVIT V2 for video and images and SoundStream for audio).
Furthermore, to illustrate the model’s capabilities, Google employed Bard. Bard crafted a fairy tale divided into separate scenes with prompts describing each, acting as input for VideoPoet: https://www.youtube.com/watch?v=70wZKfx6Ylk
Additionally, the duration of clips generated by VideoPoet is unlimited: the model can predict the subsequent second of video frame by frame to extend them. There is also the option for interactive editing of existing video clips created by VideoPoet. By default, the model produces videos in portrait orientation for convenient viewing on mobile devices. Moreover, VideoPoet can generate soundtracks for clips even without textual prompts.
The model has been evaluated for accuracy in text-to-video transformation and the compelling nature of the generated content by comparators who were asked to benchmark the model’s outcomes against alternatives (Phenaki, VideoCrafter, and Snow-1). According to these two metrics, VideoPoet surpassed each of the three compared models.
You can view examples of videos generated by VideoPoet on their website.