Zyda is a 1.3 trillion-token open-source dataset designed for open language modeling. Zyda integrates a range of high-quality open datasets, including RefinedWeb, Starcoder, C4, Pile, enhancing them through comprehensive filtering and deduplication.
Objective: Zyda aims to deliver a straightforward, accessible, and high-performance dataset suitable for language modeling experiments and training at the trillion-token scale. Ablation studies indicate that Zyda surpasses all existing open datasets, including Dolma, Fineweb, Pile, RefinedWeb, and SlimPajama.
Zyda Key Features
- High Quality: Zyda is composed of 1.3T tokens, meticulously filtered and deduplicated, sourced from top-tier datasets.
- Performance: Zyda outperforms major open language modeling datasets, including Dolma, Fineweb, and RefinedWeb, and each of its component subsets individually.
- Unique Deduplication: Implements cross-dataset deduplication to eliminate duplicates across component datasets.
- Open License: Zyda is available under a permissive Apache 2.0 open license.
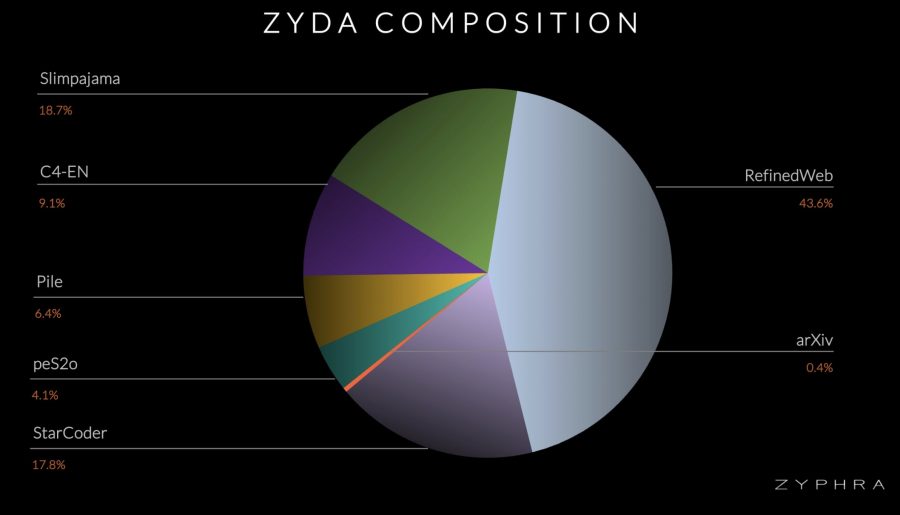
Dataset Composition
Zyda was formed by merging and meticulously processing seven respected datasets: RefinedWeb, Starcoder, C4, Pile, SlimPajama, pe2so, and arxiv. The creation process involved syntactic filtering to eliminate low-quality documents, followed by aggressive deduplication both within and between datasets. This cross-deduplication was crucial as many documents appeared in multiple datasets, likely due to common sources like Common Crawl. Approximately 40% of the initial dataset was discarded, reducing the token count from about 2T to 1.3T.
Evaluations
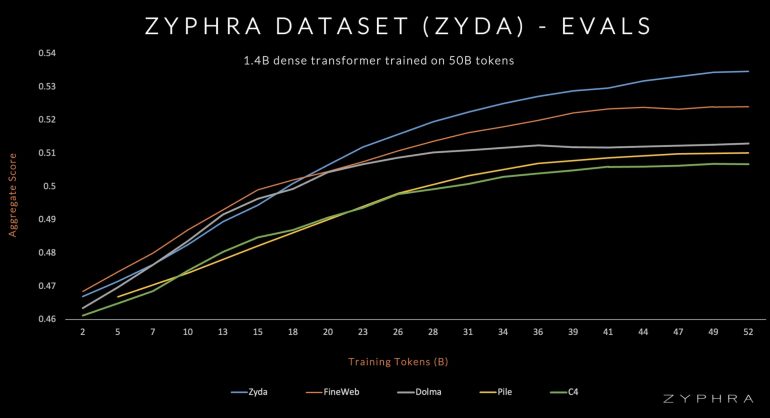
Zyda’s efficacy is demonstrated by the performance of Zamba, a model trained on Zyda, which significantly outperforms models trained on competing datasets on a per-token basis. This underscores Zyda’s robustness as a pretraining dataset.
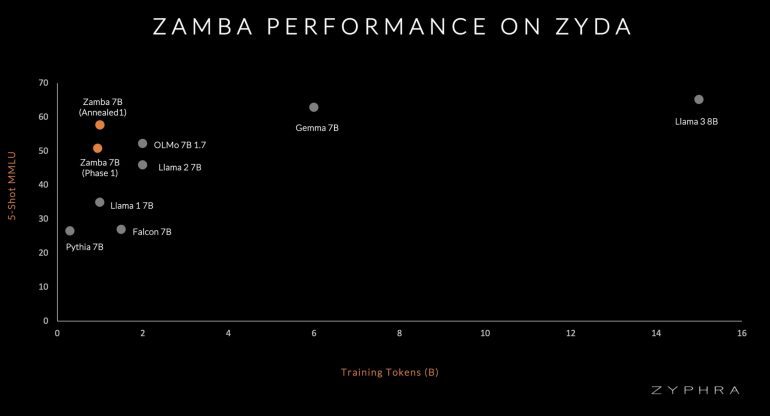
Zyda represents a significant advancement in open language modeling, offering an unparalleled resource for researchers and developers.











