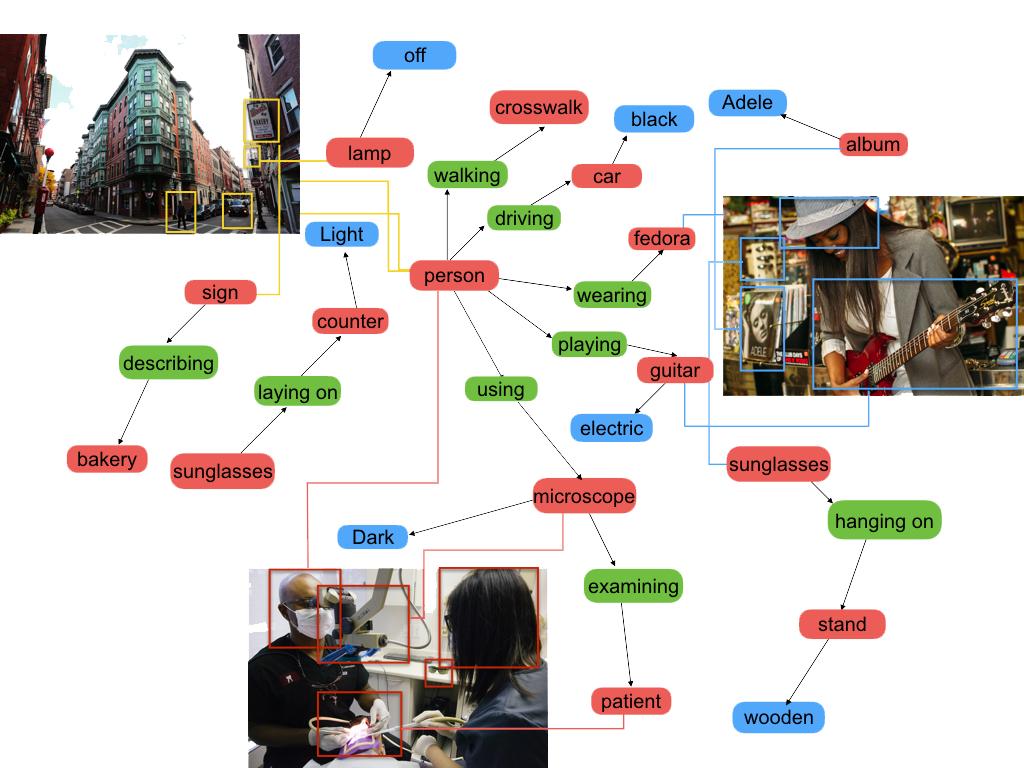
Visual Genome is a dataset with more than 100,000 images and descriptions of all objects on them. The dataset is intended for use in object search and recognition tasks.
Visual Genome is the largest dataset with descriptions of images, objects, attributes and relationships. The dataset was collected by researchers using crowdsourcing.
Visual Genome annotations are a set of rectangles bounding objects and the names of these objects. On average, 35 objects are marked on each image. In total, the dataset contains 5.4 million object descriptions, 1.7 million question-answer pairs, 2.8 million attributes and 2.3 million relationships.
The creators of Visual Genome set out to combine structured visual concepts with language. Therefore, all dataset labels are converted to synsets from WordNet.


