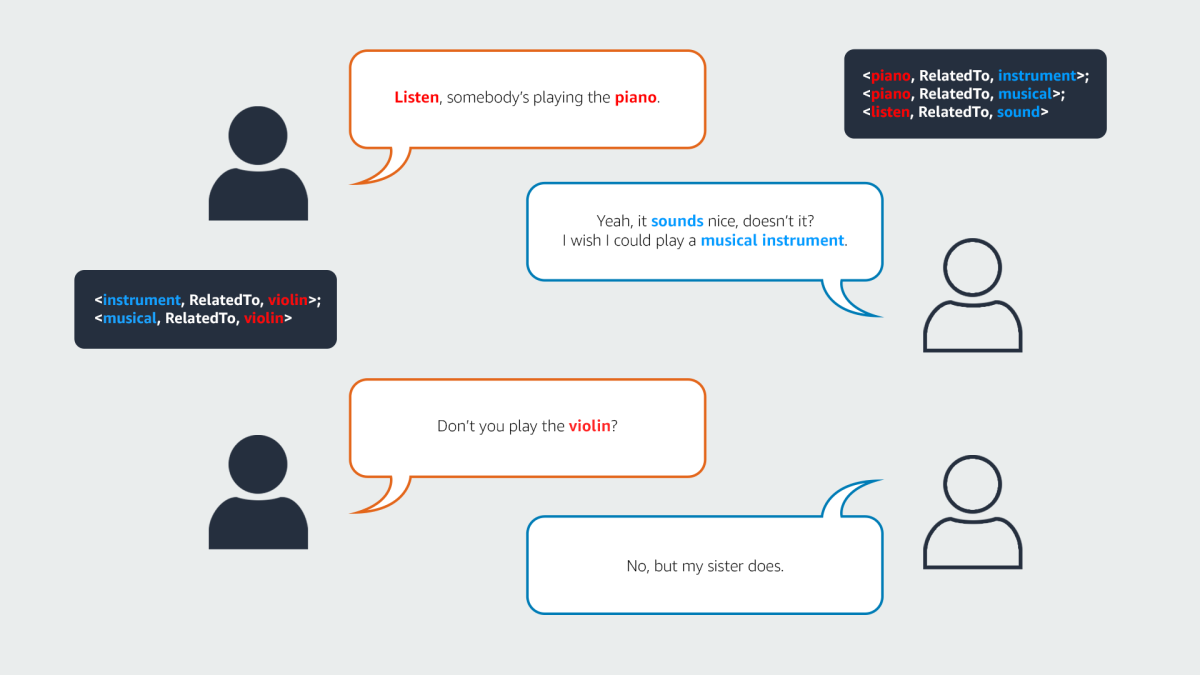
Commonsense-Dialogues is an Amazon dataset containing 11,000 dialogues from everyday life. The dataset is aimed at teaching models to understand the hidden meanings of replicas.
To date, AI assistants do a poor job of recognizing emotions and highlighting the key meaning of a replica. For example, if someone says, “Tomorrow I’m going to speak in front of a thousand people”” the listener may conclude that his interlocutor is nervous, and answer: “Relax, you’ll do great!”
In order to train assistant models to better recognize the meaning of replicas, Amazon has developed a Commonsense-Dialogues dataset of 11,000 dialogues collected using Amazon Mechanical Turk. AMT employees were given a specific topic of conversation and asked to record a dialogue on this topic.
On average, each dialog consists of 5-6 replicas. To ensure the diversity of the dataset, the topics of the dialogues were selected in accordance with SocialQA, a large-scale benchmark of various social interactions.


