
A team of researchers from NVIDIA, MIT, and other institutions introduced LongLive — a framework for real-time long video generation that allows users to control the narrative during video creation. Unlike traditional models that require a single detailed prompt for the entire video, LongLive enables sequential text instruction input, changing the narrative direction, adding new objects, or adjusting visual style during generation. In experiments, researchers used prompt switches every 10 seconds, though the model technically supports instruction changes every 5 seconds.

The model is built on a frame-level autoregressive architecture and achieves 20.7 FPS on a single NVIDIA H100 GPU, supporting video generation up to 240 seconds long. Fine-tuning the 1.3 billion parameter model for minute-long video generation took 32 GPU-days. Researchers employed a key-value recaching mechanism (KV-recache) for smooth prompt transitions without abrupt visual jumps, streaming long tuning on long sequences, and short window attention combined with frame-level attention sink to accelerate inference. Code for training and inference, model weights, and a demo page with examples are publicly available on GitHub.
LongLive is built on the Wan2.1-T2V-1.3B model. Researchers applied fine-tuning using their own methods: key-value recaching, streaming long tuning, and short window attention with frame sink. Training requires significant computational resources — 64 H100 GPUs for 12 hours (32 GPU-days), while inference requires only one H100 GPU.
Architecture and Key Components
LongLive is built on the Wan2.1-T2V-1.3B model, which generates 5-second clips at 16 FPS with 832×480 resolution. The authors adapted the pretrained model into a frame-level autoregressive architecture with causal attention, enabling KV-caching for efficient inference.
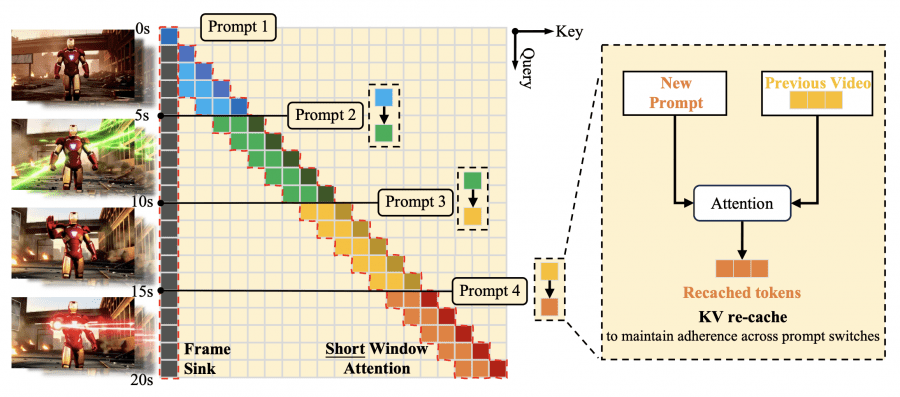
KV-recache Mechanism
When switching prompts, the model recalculates the key-value cache, combining already generated frames with new prompt embeddings through cross-attention layers. This eliminates residual semantics from the previous prompt while maintaining visual motion continuity. Experiments confirm that complete cache clearing leads to abrupt visual breaks: Background Consistency 92.75, Subject Consistency 89.59; retaining the old cache causes delays in following new prompts: CLIP Score 25.92; while KV-recache achieves optimal balance: Background Consistency 94.81, Subject Consistency 94.04, CLIP Score 27.87.

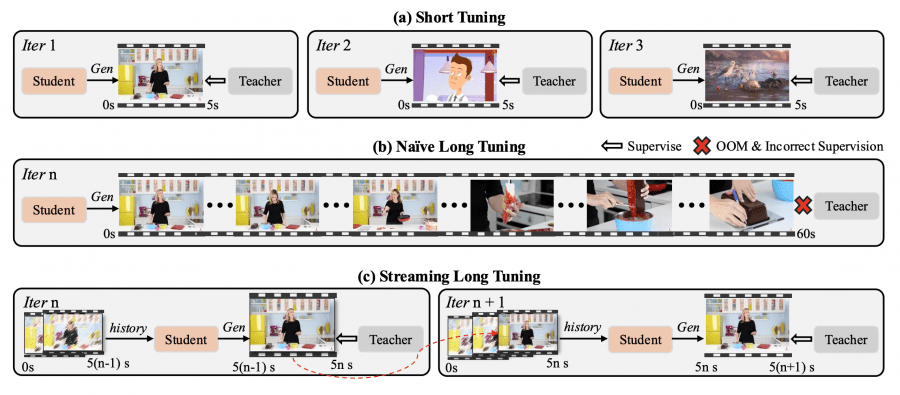
Streaming long tuning is a training strategy that eliminates the train-short–test-long mismatch. At each iteration, the model generates the next 5-second clip using the saved KV-cache from the previous iteration, applying DMD (Distribution Matching Distillation) only to the new clip. The process repeats until reaching maximum length (60 or 240 seconds). The teacher model Wan2.1-T2V-14B provides reliable supervision for the current clip, while already created frames are excluded from computations, preventing memory overflow.
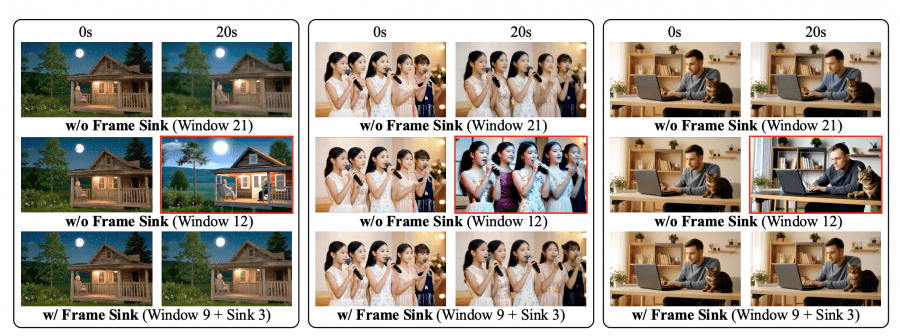
Short window attention and frame sink radically reduce computational costs. Local attention window is limited to 9 latent frames instead of the standard 21, while the first chunk of 3 latent frames is fixed as frame sink — global tokens permanently accessible for attention across all layers. Ablation on 20-second videos shows that short window without frame sink reduces Consistency Score to 90.6 with a 12-frame window, while adding frame sink restores the metric to 94.1 with an effective window of only 12 frames (9 local + 3 sink). This provides 28% faster inference time and 17% reduced peak memory consumption on a single H100 GPU.
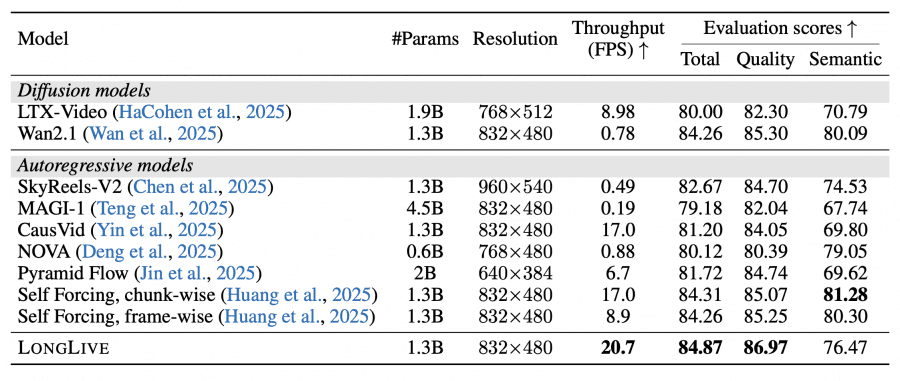
Results
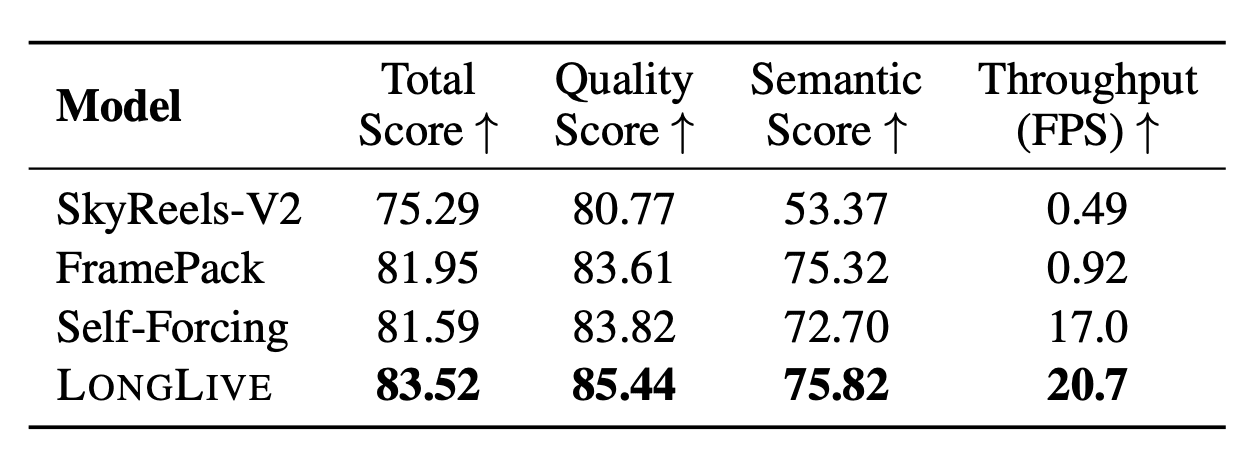
Short videos (VBench). LongLive demonstrates quality on par with the best baseline models at maximum generation speed — 20.7 FPS, which is 26× faster than the Wan2.1 diffusion model and 42× faster than SkyReels-V2.
30-second long videos (VBench-Long). LongLive leads in overall quality while maintaining high generation speed.
60-second interactive generation. To evaluate interactive mode, researchers created a dataset of 160 videos with six sequential prompt switches. LongLive shows stable instruction following throughout the video, while competitors exhibit more significant degradation. A user study with 26 participants across four criteria (overall quality, motion quality, instruction following, visual quality) confirms LongLive’s advantage.

Training Efficiency
Fine-tuning the 1.3 billion parameter model for 60-second video generation takes 12 hours on 64 H100 GPUs (32 GPU-days). Using LoRA with rank 256 makes only 27% of parameters trainable (350 million out of 1.3 billion), reducing memory requirements by 73% compared to full fine-tuning.
Quantization. INT8 quantization compresses the model from 2.7 GB to 1.4 GB and accelerates inference from 12.6 to 16.4 FPS on NVIDIA 5090 GPU with minimal quality degradation.
LongLive scales to 240-second videos on a single H100 GPU while maintaining high visual fidelity and temporal coherence.







