Researchers from ByteDance and the University of Hong Kong introduced Mini-o3 — a multimodal model that performs deep multi-step reasoning to solve complex visual search tasks. Mini-o3 achieves SOTA results on challenging benchmarks, outperforming all existing open-source models and the proprietary GPT-4o, generating reasoning sequences tens of steps long with gradual improvements in accuracy. Model code is published on Github and Huggingface, and the researchers also released the training datasets publicly.
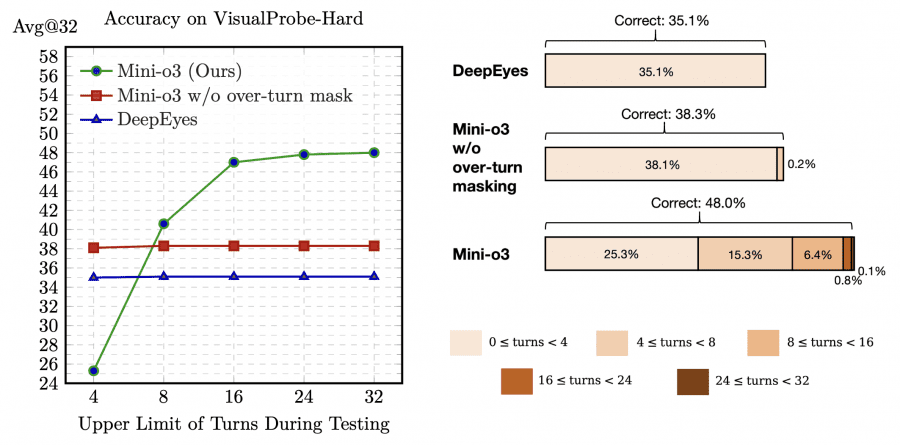
Existing open-source VLMs show weak performance on tasks that require trial-and-error learning: the leader DeepEyes reaches only 35.1% accuracy on VisualProbe-Hard. Unlike OpenAI o3, these models are unable to generate diverse reasoning strategies (depth-first search, trial-and-error exploration, self-reflection) and deep chains of reasoning.
Architecture and approach
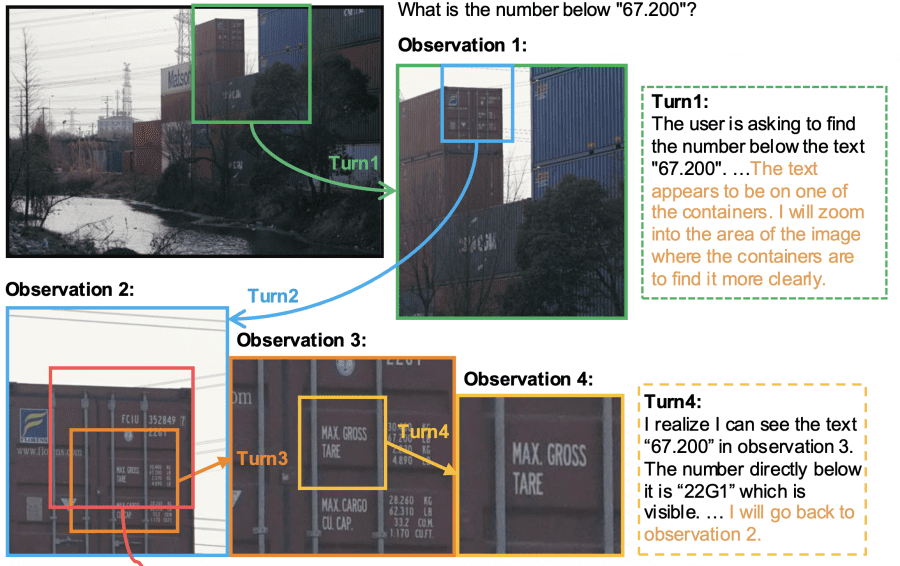
Mini-o3 is built on top of the Qwen2.5-VL-7B-Instruct. Mini-o3 operates iteratively: the policy model at each step generates two elements — a thought (thought Ti) and an action (action Ai). An action is a command for image-processing tools — for example, to zoom into a specific region of the image. After executing the action the model receives a new visual result (observation Oi) — the processed patch from the original image that becomes input for the next step. This information is appended to the accumulated context, and the model proceeds to the next analysis iteration. The process repeats cyclically (thought → action → visual result) until the model finds an answer to the posed question or reaches technical context-length limits.
Components of the architecture include:
- Thought Ti: the internal reasoning process for selecting the next action based on the interaction history
- Action Ai: the action space includes two options — localizing a region (specified by normalized bounding box coordinates in the range [0,1]² to indicate the zoom region) and producing the final answer
- Observation Oi: the image obtained after executing Ai — a cropped patch from the original image or the previous visual result

Data collection and model training
The training procedure consists of two phases. Supervised Fine-Tuning (SFT) trains the model on thousands of multi-step sequences using image-processing tools to generate correct solution paths with diverse reasoning patterns. Reinforcement Learning with Verifiable Rewards (RLVR) applies the GRPO algorithm to optimize the model’s strategy, where the correctness of answers is evaluated not by simple string comparison but by semantic matching — for this an external large language model is used as the arbiter.

To collect initial data the researchers created the Visual Probe dataset — 4,000 question-answer pairs for training and 500 for testing across three difficulty levels. The dataset is particularly challenging: the target objects occupy a small portion of the image, many similar elements can be misleading, and the large image size requires careful multi-stage analysis to find the needed information. To generate the data the researchers used an existing vision-language model capable of learning from examples in the loop. They prepared a small set of reference examples demonstrating the desired behavior and then had the model imitate this approach on new tasks, sequentially generating thoughts and actions for each solution step.
Using only 6 reference examples, the researchers were able to generate about 6,000 training sequences, each demonstrating the full solution path for a visual search task.
The process worked as follows: they created 6 manually crafted reference examples demonstrating how the model should solve visual search tasks step by step (with thoughts, zooming actions, etc.). They then used these 6 examples for few-shot prompting of the existing VLM. Following these prototypes, the model generated similar step-by-step solutions for other image-question pairs from the dataset. From all attempts only those solution sequences that led to the correct answer were selected — resulting in about 6,000 successful training sequences.
Over-turn Masking strategy
A key innovation of Mini-o3 is the technique of masking incomplete sequences (over-turn masking) to prevent penalizing answers that exceeded the step limit during training. In the standard GRPO algorithm, answers that reach the maximum number of steps or exceed the context limit receive zero reward and after normalization acquire negative advantages.
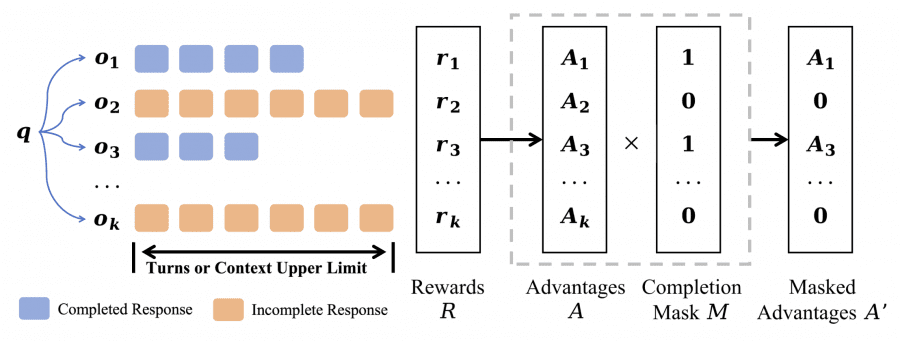
The researchers designed a mechanism that distinguishes two types of model responses: completed (when the model managed to find a solution within the allotted number of steps) and incomplete (when the step limit was exhausted but no answer was obtained). In the standard approach incomplete attempts are automatically considered failures and penalized during training, which pushes the model to answer faster even if the task requires more time for analysis.
The new approach works differently: incomplete sequences are simply excluded from the training process — they are considered neither correct nor incorrect. The model learns only from examples where the process reached the end and the correctness of the answer could be verified. When computing gradients only successfully completed attempts are taken into account, which allows the model not to be afraid of producing long reasoning chains and not to rush to premature conclusions.
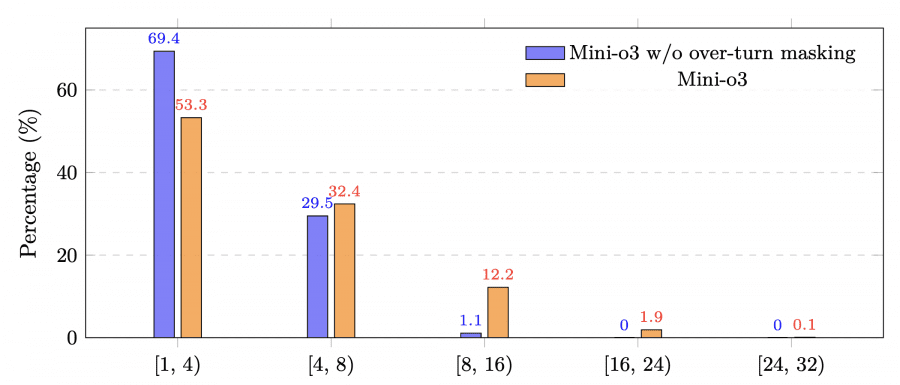
This technique is critically important for scaling the number of steps at inference: accuracy increases with longer reasoning sequences up to tens of iterations, even though the model was trained with a limit of only 6 steps. Reducing the training step budget from 16 to 6 reduces training time from about 10 days to roughly 3 days, practically without affecting final accuracy at test time.
Results and performance
Mini-o3 achieves state-of-the-art performance on all tested visual search benchmarks. On the VisualProbe-Hard benchmark the model shows 48.0% accuracy versus 35.1% for DeepEyes and 28.8% for Pixel Reasoner. On V* Bench Mini-o3 reaches 88.2% (Avg@32), outperforming Chain-of-Focus at 88.0% (Avg@1). Results on HR-Bench-4K are 77.5%, and on MME-Realworld — 65.5%.
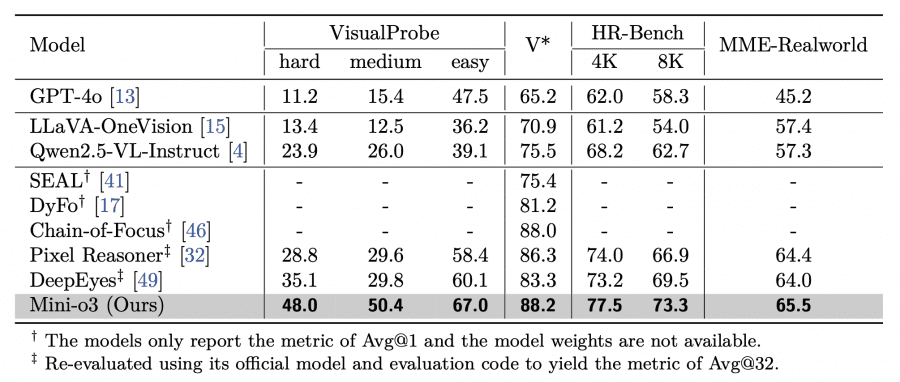
It is important to note that all competing models mentioned also have 7B parameters, which makes the comparison fair. Mini-o3’s superiority is achieved not by increasing model size but thanks to innovative training approaches and architecture.
Technical implementation details
Ablation studies confirm the importance of each component of the architecture. Removing the complex reinforcement-learning data reduces performance by roughly 8.6 percentage points on the VisualProbe-Hard dataset. Initial fine-tuning is absolutely necessary — without it the model is unable to solve the tasks at all. Masking incomplete sequences increases training stability and allows the model to adaptively increase the number of steps when tackling particularly difficult tasks during testing.
The optimal image resolution is 2 million pixels — this yields 48.0% accuracy on VisualProbe-Hard versus 36.1% at 12 million pixels. At excessively high resolution the model stops prematurely (on average performs only 1 step at 12M compared to 5.6 steps at 2M), while at too low resolution it begins to “see” non-existent details.
For initial fine-tuning Qwen2.5-VL-7B-Instruct is used with a maximum resolution of 2M pixels. Training is performed on approximately 6,000 generated examples for 3 epochs with a learning rate of 1×10⁻⁵. For reinforcement learning the GRPO algorithm is applied with a batch size of 16, clipping coefficients 0.30/0.20 and a constant learning rate of 1×10⁻⁶ without KL-divergence or entropy regularization. In addition to the Visual Probe data, 8,000 examples from DeepEyes-Datasets-47k are used to preserve performance on simpler tasks.
Mini-o3 demonstrates that it is possible to create multimodal agents with deep chains of reasoning by combining complex training data, efficient generation of initial examples, and an innovative masking strategy for incomplete sequences. At test time the model naturally scales to tens of steps of analysis, opening new possibilities for solving complex visual tasks that require iterative exploration and trial-and-error approaches.








