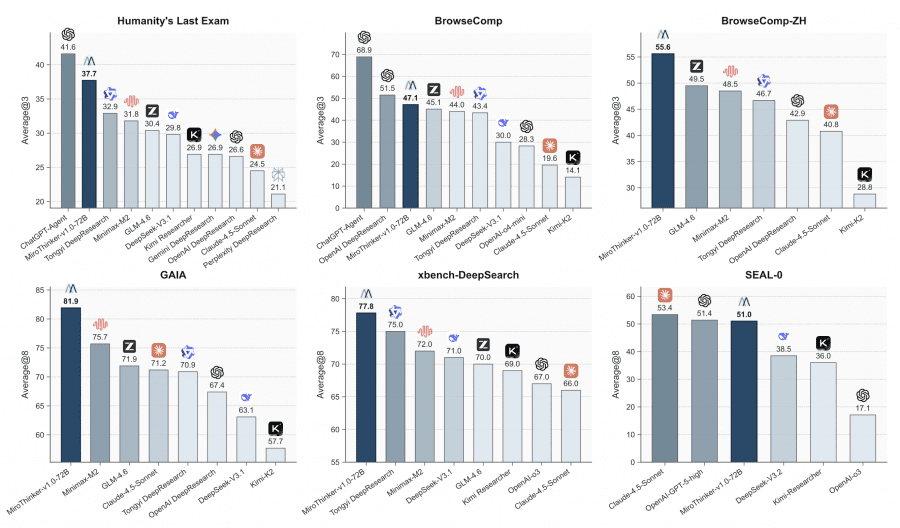
The MiroMind team introduced MiroThinker v1.0 — an AI research agent capable of performing up to 600 tool calls per task with a 256K token context window. On four key benchmarks — GAIA, HLE, BrowseComp, and BrowseComp-ZH — the 72B parameter version achieves 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing other open-source agents and approaching commercial systems like GPT-5-high. The project is fully open: code is available on Github, model weights on HuggingFace, and you can try the model through an online demo.
What is Interactive Scaling
Typically, the performance of large language models is improved in two ways: by increasing model size or expanding the context window. MiroThinker adds a third approach — interactive scaling. This means training the model to perform more and deeper interactions with external tools during task solving.
Unlike standard test-time scaling (where the model simply “thinks” longer in isolation), interactive scaling works differently: the model actively uses feedback from the environment and acquires new information from outside. This helps correct errors and adjust the solution trajectory. Through reinforcement learning, the model learned to efficiently scale interactions: with a 256K token context window, it can perform up to 600 tool calls on a single task, enabling sustained multi-turn reasoning and handling complex real-world research tasks.
Agent Architecture Design
MiroThinker operates on the ReAct paradigm — a cyclical “think–act–observe” process. At each step, the model analyzes the current situation and formulates a thought, then invokes the necessary tool, receives the result, and updates its understanding of the task. This cycle repeats until the task is solved.
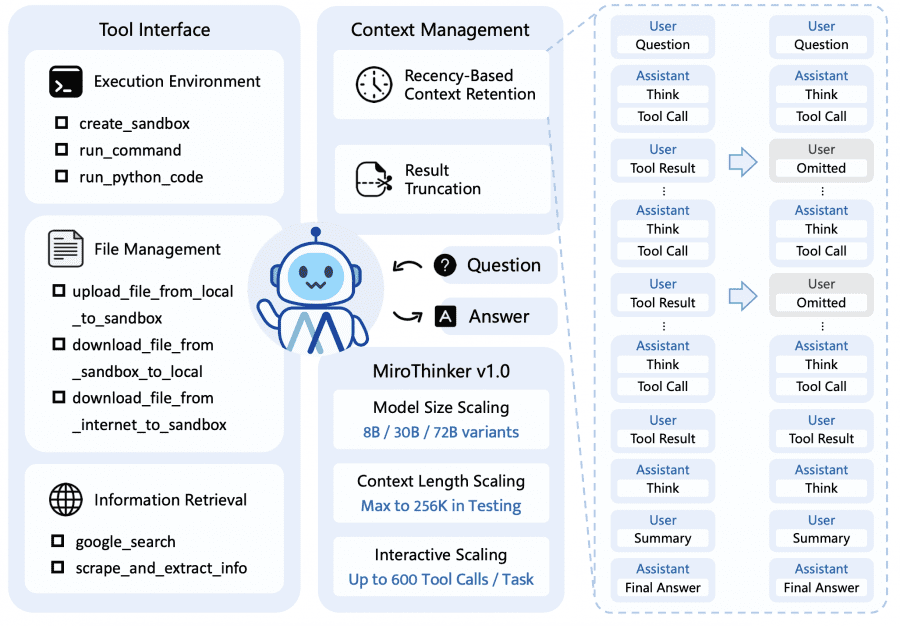
The agent has access to three categories of tools:
- Execution Environment: isolated Linux sandbox for running commands and Python code.
- File Management: uploading and downloading files between local system, sandbox, and the internet.
- Information Retrieval: web search via Google and intelligent web page parsing. The key feature of the latter is that the tool uses a lightweight language model (e.g., Qwen3-14B) to extract only relevant information from lengthy web pages at the agent’s request — an efficient form of context management.
To fit up to 600 interactions into a 256K token context window, two strategies are applied. First — retaining only recent results: all agent thoughts and actions are preserved in context, but tool results are kept only from the last K steps (typically K=5). This works because the model’s subsequent actions depend primarily on recent observations rather than distant ones. Second strategy — truncating long outputs: if a tool returns too much data, the response is truncated with a “[Result truncated]” marker.
Model Training Process
MiroThinker training proceeds in three stages, each developing different agent skills. The models are based on open-weight Qwen2.5 and Qwen3, available in three sizes: 8B, 30B, and 72B parameters.
The first stage — Supervised Fine-Tuning (SFT) — teaches the model to imitate expert task-solving trajectories. To achieve this, researchers created a large synthetic dataset with trajectories, each containing a “thought–action–observation” sequence. They discovered that even trajectories generated by the best models contain significant noise: repetitions within responses, duplicates between responses, incorrect tool invocations. Therefore, they applied strict filtering and data restoration before training.
The second stage — Direct Preference Optimization (DPO). The model learns to select better solution trajectories. For this, they collected a dataset with trajectory pairs: preferred (leading to correct answer) and dispreferred (leading to incorrect answer). Importantly, preferences are determined solely by final answer correctness, without rigid constraints on solution structure — no fixed planning length, step counts, or reasoning formats are imposed. This approach avoids systematic biases and improves scalability across different task types.

The third stage — Reinforcement Learning (RL) via the GRPO algorithm. Here the model learns to find creative solutions through direct environment interaction. Researchers built a scalable environment capable of supporting thousands of parallel agent runs with real search, web page parsing, Python code execution, and Linux VM operations. The reward function accounts for solution correctness and penalizes formatting violations. They applied strict trajectory filtering: removing successful trajectories with pathological behavior (API error sequences, redundant action repetitions) and unsuccessful trajectories with trivial failure causes (formatting issues, action loops).
Benchmark Results
MiroThinker-v1.0-72B established a new standard among open-source research agents. On the GAIA benchmark (testing multi-step reasoning and tool use capabilities), the model achieved 81.9% accuracy, surpassing the previous leader MiniMax-M2 by 6.2 percentage points. On the extremely challenging Humanity’s Last Exam, the result was 37.7%, which is 2.5 points higher than proprietary GPT-5-high using the same tools.
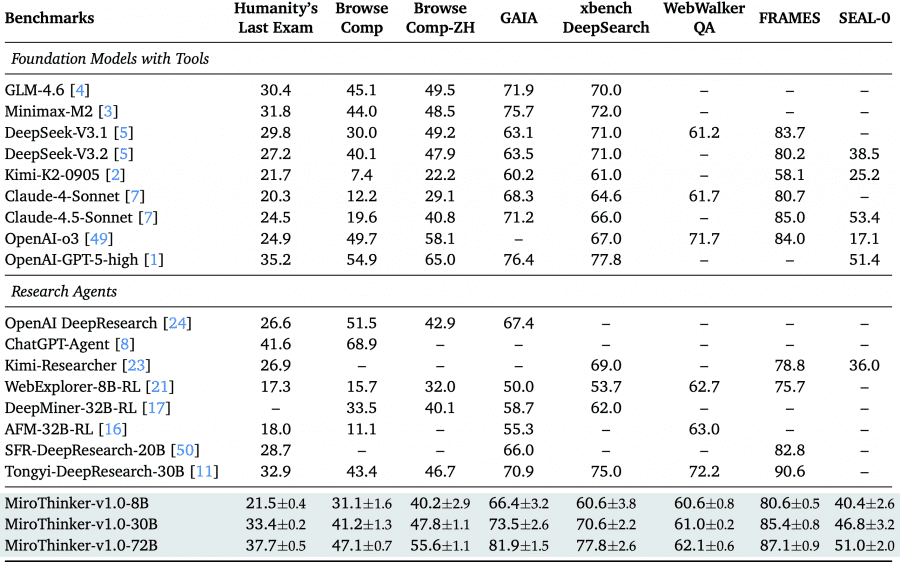
On web navigation benchmarks BrowseComp and BrowseComp-ZH (Chinese version), the model showed 47.1% and 55.6% respectively. This places it on par with advanced commercial systems like OpenAI DeepResearch, OpenAI o3, and Anthropic Claude 4.5. On the Chinese benchmark xBench-DeepSearch, it achieved 77.8%, confirming the model’s multilingual capabilities. The 8B and 30B parameter versions also show the best results in their respective size classes, providing the community with access to powerful research agents of various scales.
Analysis showed that reinforcement learning substantially changes the agent’s interaction patterns with the environment. The RL-tuned MiroThinker-v1.0-30B demonstrates significantly longer and deeper interaction trajectories compared to the SFT version across all benchmarks. Guided by verifiable rewards, the model explores more exhaustive solution paths, systematically testing multiple strategies and validating intermediate results. This directly correlates with improved accuracy — gains average 8-10 percentage points. Researchers call this consistent relationship between interaction depth and performance interactive scaling.
Known Limitations
The team identified several limitations of the current version that they plan to address in future updates.
Tool-use quality under interactive scaling: although the RL version invokes tools more frequently, a portion of these invocations provide marginal or redundant contributions to the solution. This shows that scaling improves performance, but additional optimization of efficiency and action quality is needed.
Excessively long reasoning chains: reinforcement learning encourages the model to generate longer responses to improve accuracy, leading to excessively long, repetitive, and less readable reasoning chains.
Language mixing: the model’s responses may contain multilingual elements — for example, internal reasoning for a Chinese query might include both English and Chinese fragments.
Limited sandbox capabilities: the model hasn’t fully mastered code execution and file management tools. It sometimes generates code leading to timeouts, or attempts to use the code execution tool for reading web pages instead of the specialized parser.
Whether your team is looking to integrate MiroThinker v1.0 into your workflows, or your management team is considering adopting automated AI tools into your daily productions, our recommendation is to start with Coursiv. The leading online-learning platform is dedicated ro providing users with a comprehensive picture of basic AI tools and certifiable AI skills.






