
Researchers from Show Lab at the National University of Singapore and ByteDance introduced Show-o2 — a second-generation multimodal model that demonstrates superior results in image and video understanding and generation tasks. Show-o2 uses an improved architecture with a dual-path mechanism that allows the 7B model to outperform even 14B competitors with lower computational costs. The model achieves competitive performance using 2-3 times less training data compared to state-of-the-art models. The model code is available on Github.
Architectural Innovations
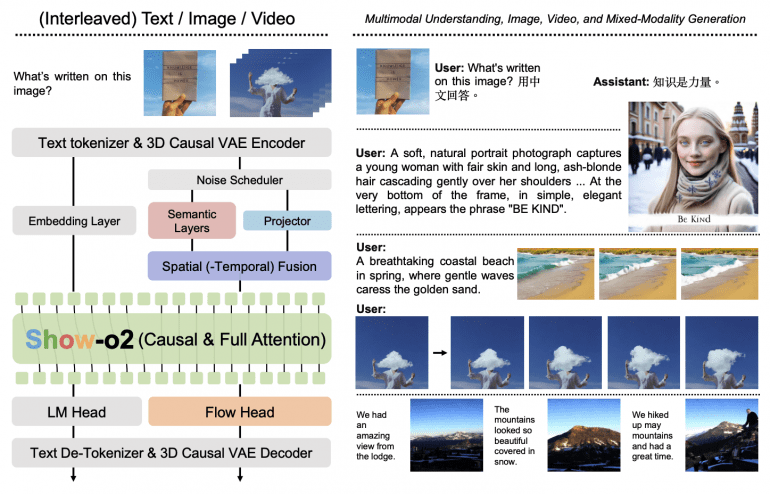
The foundation of Show-o2’s architecture lies in a fundamentally new approach to creating unified visual representations. The model uses a three-dimensional causal VAE space that scalably supports both images and videos through a dual-path spatial(-temporal) fusion mechanism.
Unified visual representations are built through a combination of semantic layers and a projector. Semantic layers, based on the SigLIP architecture with a new 2×2 patch embedding layer, extract high-level contextual representations. The projector preserves complete low-level information from visual latent representations.
The fusion process combines high-level and low-level representations through concatenation along the feature dimension with RMSNorm and two MLP layers. The spatial-temporal fusion mechanism processes both spatial and temporal information to create unified visual representations.
The Flow Head uses several transformer layers with time step modulation through adaLN-Zero blocks to predict velocity through the flow matching algorithm. During training, the model simultaneously applies next token prediction to the language head and flow matching to the flow head with loss balancing through a weighting coefficient.
Two-Stage Training Strategy
Show-o2 uses an innovative two-stage training strategy that effectively preserves language knowledge while simultaneously developing visual generation capabilities.
Stage-1 involves training only trainable components: the projector, spatial-temporal fusion, and flow head on approximately 66 million image-text pairs with progressive addition of interleaved data and video-text pairs.
Stage-2 involves fine-tuning the full model using 9 million high-quality multimodal instruction data and 16 million high-quality generative data, filtered from 66 million image-text pairs.
For scaling, researchers use a pre-trained flow head from the 1.5B model for the larger 7B model, introducing a lightweight MLP transformation to align hidden state sizes.
Experimental Results
Key achievements of Show-o2 include superiority over models of similar size: the 1.5B version shows the best results on MME-p (1450.9) and MMMU-val (37.1), while the 7B version sets new records on MME-p (1620.5), MMMU-val (48.9), and MMStar (56.6). In image generation tasks, the model demonstrates impressive results on GenEval (0.73 for 1.5B, 0.76 for 7B) and DPG-Bench (85.02 for 1.5B, 86.14 for 7B), using significantly less training data compared to competitors.
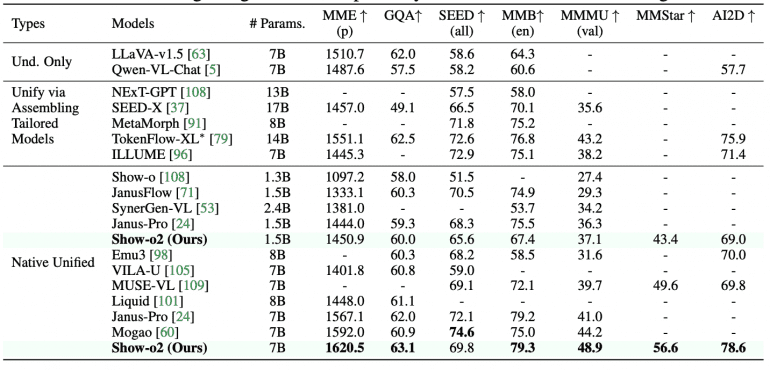
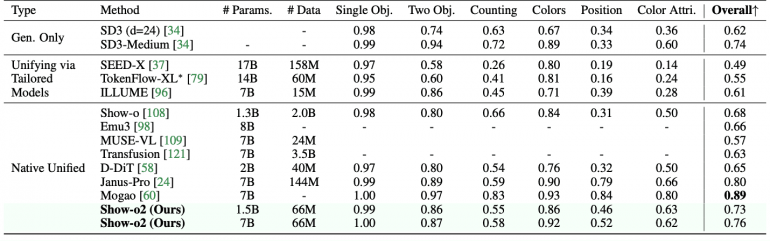
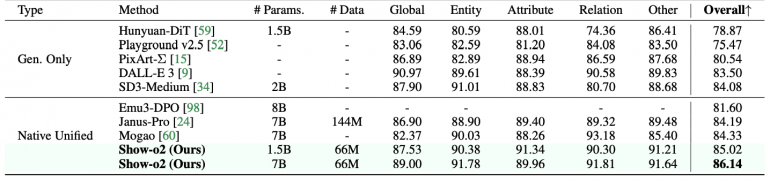
On image generation benchmarks, Show-o2 outperforms most approaches, including TokenFlow-XL, Show-o, Emu3, and Transfusion on GenEval. When compared to Janus-Pro, which was trained on a significantly larger dataset (144M image-text pairs), Show-o2 achieves competitive results using only 66M pairs.
In video generation tasks, the model with only 2B parameters outperforms models with more than 6B parameters, such as Emu3 and VILA-U. Show-o2 demonstrates competitive performance compared to CogVideoX and Step-Video-T2V on the VBench benchmark.
Practical Applications
Show-o2 demonstrates outstanding mixed-modality generation capabilities through interleaved image-text sequences. During fine-tuning, the model can predict [BOI] tokens to start image generation, upon detection of which noise is added to the sequence for gradual image generation.
The model supports:
- High-quality image generation with detailed adherence to text instructions;
- Video generation from text and images with consistent frames;
- Multimodal understanding in English and Chinese;
- Mixed-modality generation for visual storytelling.
Ablation studies confirm the effectiveness of the spatial-temporal fusion mechanism, showing improvements in both multimodal understanding (MME-p: +23.1, GQA: +1.4) and generation (FID-5K: -1.3). The second training stage is critically important, providing significant improvements on GenEval (+0.10) and DPG-Bench (+1.42).
Additional examples of text-to-video and image-to-video generation:

Technical Specifications
Show-o2 is released in two configurations based on Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct with 3D causal VAE from Wan2.1 with 8× and 4× spatial and temporal compression respectively. Training the 1.5B model takes approximately one and a half days on 64 H100 GPUs, while the 7B model requires about two and a half days on 128 H100 GPUs.
The research demonstrates the possibility of creating highly efficient unified multimodal models through comprehensive architectural optimization.







