Researchers from Princeton University have introduced OpenClaw-RL, a framework that allows an AI agent to improve in real time — without a separate data collection stage and without manual annotation. Most RL frameworks for language models operate in batch mode: first collect a dataset, then train. OpenClaw-RL works differently — a model deployed on the user’s own infrastructure connects through OpenClaw, and the framework trains it directly on live conversations, in the background, without interrupting the model’s operation. The training signal comes from the environment’s response to each action the agent takes.
OpenClaw implements the same request format as the OpenAI API, meaning any existing code or tools written for ChatGPT will work with OpenClaw without modification — just change the base URL. The project is fully open: the infrastructure code is published on GitHub under the Apache 2.0 license. All components are available without closed dependencies — experiments can be reproduced or adapted for your own agent.
Modern language models — including ChatGPT, Claude, and similar systems — do not learn during a conversation with a specific user. What looks like “remembering” within a session is the context window: the model sees the history of the current conversation, but the weights do not change. After the session ends, nothing is saved to the model’s parameters. Every new conversation starts from the same weights.
OpenClaw-RL does what ordinary LLMs do not: it actually updates the model’s weights via gradient descent based on live interactions — right during use, without pausing the conversation. The novelty is not in the idea of online learning itself, but in how the signal is extracted. Standard methods like RLHF or DPO require collecting an annotated dataset first, then running training separately. OpenClaw-RL removes this separation: the training signal emerges automatically from the environment’s reaction to each agent action, without annotators and without any pause in the model’s operation.
The Untapped Potential of Interaction Signals
Every agent action produces an environment response — a next-state signal: the output of a terminal command, a change in the GUI state, or a user’s reply to the assistant. Existing agent architectures use this signal exclusively as context for the next step, ignoring its training potential.
The authors identify two types of information contained in next-state signals that are systematically discarded.
Evaluative signals — an implicit assessment of the quality of the previous action. A follow-up question from the user signals dissatisfaction; a passing test confirms the code is correct; an error message indicates a failure. This assessment arises for free in every interaction and requires no separate annotation pipeline.
Directive signals — a concrete indication of how the action should have been performed differently. If a user writes “you should have checked the file first,” this is not just a negative evaluation — it is token-level information about what response should have been generated. The scalar reward (+1/−1) used in standard RLVR methods destroys this information entirely.
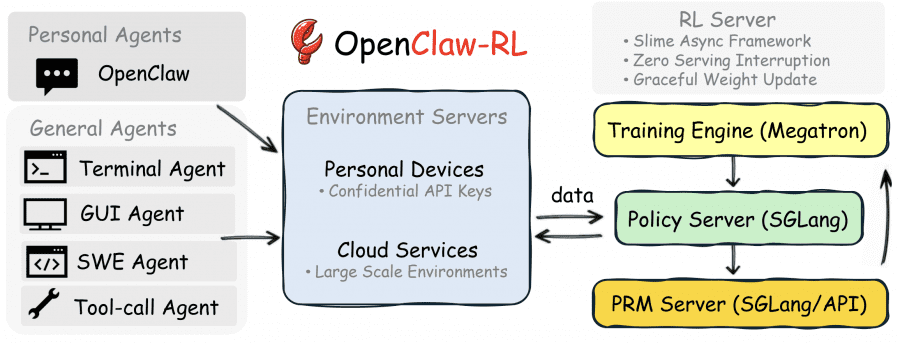
Architecture: Four Independent Components
The core principle of OpenClaw-RL is full asynchrony. Four components operate in independent loops without blocking dependencies:
- Policy Server (SGLang) handles incoming requests;
- Environment Server receives interaction results;
- PRM Server evaluates the quality of each step;
- Training Engine (Megatron) updates the policy weights.
While the training engine applies gradients, the model continues responding to new requests, and the PRM evaluates previous responses — no component waits for another to finish.
This architecture solves the practical problem of long horizons: in agentic tasks a single rollout can span dozens of steps, and waiting synchronously for it to complete would block the entire pipeline. Asynchrony allows training signals to accumulate from parallel environments without idle time.
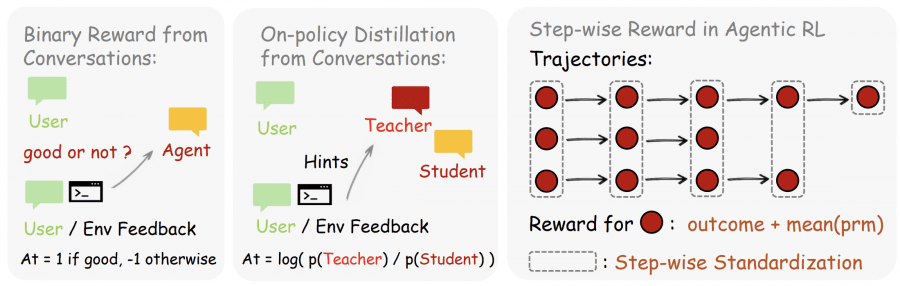
Two Methods for Extracting Training Signals
Binary RL — Evaluative Signals as a Scalar Reward
The PRM judge (Process Reward Model) receives the agent’s action and the next environment state, then outputs a score: +1 (correct), −1 (incorrect), or 0 (neutral). To improve reliability, m parallel independent judge queries are run and the result is decided by majority vote. The score is used as the advantage in standard PPO (Proximal Policy Optimization) with asymmetric clipping bounds: ε=0.2, ε_high=0.28, β_KL=0.02.
The method covers all scored turns and works with any type of signal — including implicit reactions (the user simply repeated a question) or structured environment outputs (exit codes, test verdicts). Its limitation: the entire informational richness of the next-state signal is compressed into a single number.
Hindsight-Guided OPD — Directive Signals at the Token Level
This method converts the directive part of the next-state signal into token-level guidance. If a user wrote “you should have checked the file first,” this phrase contains information not only about the response being wrong, but about which tokens should have been generated. Binary RL discards this information; OPD preserves it.
The algorithm has four steps. In the first, the judge analyzes the agent’s response and the next state, extracting a brief “hint” — 1–3 sentences about what should have been done differently. In the second, the most informative hint is selected from all obtained hints; samples without valid hints are discarded — OPD deliberately trades sample volume for signal quality. In the third, the hint is appended to the original prompt, forming an “enhanced teacher context”: the same model now sees the situation as if the user had originally given a more precise instruction. In the fourth, the difference in token log-probabilities is computed between the model’s response under the enhanced context (“teacher”) and the original response (“student”): Aₜ = log π_teacher(aₜ|s_enhanced) − log π_θ(aₜ|sₜ).
The sign of the advantage at each token level indicates the direction of correction: a positive value means the model should increase the probability of that token; a negative value means it should decrease it. Unlike a scalar advantage, different tokens within a single response can receive opposite correction directions.
Personal Agent: Learning from Conversational Signals
The authors tested OpenClaw-RL on two personalization scenarios using the OpenClaw assistant. Both scenarios are implemented as simulations: a language model plays the role of the user and interacts with the policy agent. The base model in both scenarios is Qwen3-4B; training is triggered after every 16 collected training samples.
The “Student” scenario: the agent helps solve math problems from the GSM8K dataset, while the simulated student requires that responses not look AI-generated — no structured steps with bold formatting, no “Final Answer” phrase, no characteristic technical style.
The “Teacher” scenario: the agent grades homework. The simulated teacher requires specific and friendly comments — pointing out what the student did correctly, rather than a formal statement of the result.
Examples of the agent’s responses before and after optimization in the “Student” and “Teacher” scenarios. On the left — responses with an AI-like style (bold text, template phrases); on the right — after 36 and 24 interactions respectively.

Personalization Results
The authors measured the quality of the agent’s first response to a new task — before the user had a chance to clarify anything. Evaluation was performed by the same simulator model on a 0–1 scale. The baseline score without personalization was 0.17 for the “Student” scenario and 0.22 for the “Teacher” scenario; the table below refers to the “Student” scenario.
| Method | 8 steps | 16 steps |
|---|---|---|
| Binary RL | 0.25 | 0.23 |
| OPD | 0.25 | 0.72 |
| Combined (Binary + OPD) | 0.76 | 0.81 |
Binary RL yields a noticeable improvement in the early steps but quickly plateaus: the score barely grows from step 8 to step 16. OPD shows a slow start — at 8 steps its results match Binary RL — but then accelerates sharply: by step 16 the score reaches 0.72. The delay is explained by strict filtering: only samples with extractable directive hints enter training, which reduces sample volume but increases information density per sample. The combined method performs best at both time horizons: Binary RL provides gradient coverage across all turns, while OPD adds high-precision token-level correction on the subset of samples with directive signals.
The baseline scores of 0.17 and 0.22 reflect the level of Qwen3-4B without personalization in the “Student” and “Teacher” scenarios respectively. The rise to 0.81 over 16 interactions means the agent adapted to a specific user’s preferences without any manual annotation.
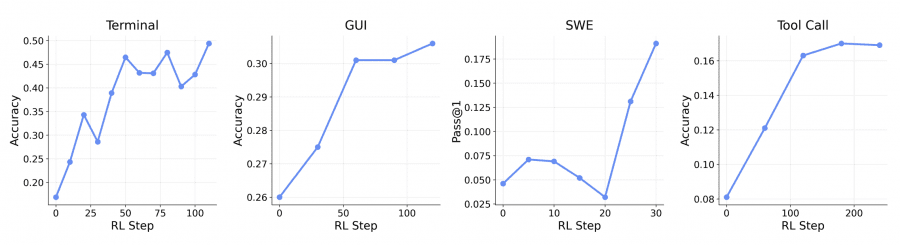
General Agents: Terminal, GUI, SWE, Tool Calls
The same infrastructure was tested on four types of agentic tasks with different models and benchmarks. The terminal agent used Qwen3-8B on the SETA RL dataset. The GUI agent used Qwen3VL-8B-Thinking on OSWorld-Verified. The SWE agent (software engineering) used Qwen3-32B on SWE-Bench-Verified. The tool-call agent used Qwen3-4B-SFT on DAPO RL data, evaluated on olympiad-level math problems from AIME 2024. Parallel environment scale: 128 for the terminal agent, 64 for GUI and SWE, 32 for tool-call.
Integrating step-wise PRM rewards with the outcome reward consistently improves results compared to training on trajectory outcomes alone.
| Agent | Integrated (PRM + outcome) | Outcome only |
|---|---|---|
| Tool-call | 0.30 | 0.17 |
| GUI | 0.33 | 0.31 |
The gain is most pronounced for the tool-call agent: accuracy rises from 0.17 to 0.30. For the GUI agent the gain is smaller (0.31 → 0.33), consistent with the shorter task horizon in that setting. The practical trade-off is that hosting a separate PRM server requires additional compute resources.
What Has Been Added Since the Paper
The repository is actively maintained: since the paper’s release on March 10, 2026, the authors have added several significant features.
LoRA. On March 12, support for LoRA training was added — a parameter-efficient method in which only low-rank adapters are updated rather than all model weights. This reduces GPU memory requirements and makes training accessible on less powerful hardware.
Tinker — training without a GPU. On March 13, support was added for the cloud service Tinker, which allows RL training to be launched without any local GPU. All three methods (Binary RL, OPD, Combined) are supported via a single command, for example: python run.py --method combine --model-name Qwen/Qwen3-8B. The authors note that Tinker supports only LoRA, which may be less effective than full fine-tuning in some cases.
Minimum requirements for local deployment. The default configuration is designed for 8 GPUs; the number is configurable via environment variables. Requirements: CUDA 12.9, Python 3.12. The specific GPU model is not stated by the authors.
All data stays local. The entire stack — policy model, PRM judge, and training engine — runs on the user’s own server. Conversation data is not transmitted to third-party services.
Comparison with Other Alignment Methods
RLHF (Reinforcement Learning from Human Feedback) requires a separate annotation pipeline with human annotators. OpenClaw-RL extracts signals from live interactions without any human involvement in labeling.
DPO (Direct Preference Optimization) requires paired examples of preferred and rejected responses, collected in advance. OpenClaw-RL requires neither pairs nor a pre-collected dataset.
GRPO (Group Relative Policy Optimization) and related RLVR methods operate in batch mode: data collection first, then training. OpenClaw-RL trains online — without separating the two phases.
Standard distillation requires a separate teacher model that outperforms the student. In Hindsight-Guided OPD, the teacher and student are the same model: the only difference is the context — with or without the hint.
Practical Implications
The main practical result of this work is that continuous online learning from live interactions becomes technically feasible without specialized data collection infrastructure. Instead of the “collect data → train → deploy → repeat” cycle, the agent improves directly in production.
For personal agents, this means that adaptation to a user’s individual preferences happens automatically during normal use — without any technical involvement from the user.
Limitations: experiments with personal agents were conducted only in simulation mode, and real user behavior may differ significantly. Not all interactions contain extractable directive signals, so OPD operates on a subset of samples. Hosting a PRM adds computational overhead, which is particularly noticeable in GUI scenarios with multimodal judges.






