ClawBench — a benchmark testing whether AI agents can complete real everyday online tasks: booking a flight, applying for a job, placing an order. Results showed that even the strongest model — Claude Sonnet 4.6 — completes only 33% of tasks. This starkly contrasts with traditional benchmarks, where AI agents score 65–75%. The evaluation infrastructure, tasks, and pipeline are published on GitHub, and datasets and materials are available on the benchmark website.
The Problem with Existing Benchmarks
Most popular web agent benchmarks — WebArena, OSWorld, VisualWebArena — evaluate models in sandbox environments. This means the agent interacts not with a real website, but with a static HTML copy with a fixed DOM structure, no authentication, and no dynamic content. These conditions greatly simplify the task: on a real website, an agent encounters cookie consent banners, JavaScript rendering, CAPTCHAs, and multi-step forms.
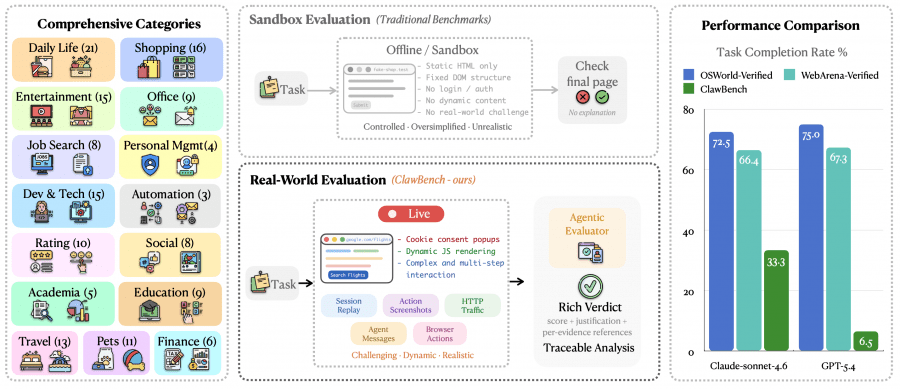
Furthermore, benchmarks that do use real websites — WebVoyager, AssistantBench — only test reading and information retrieval. Submitting forms, making purchases, writing data — none of this was systematically tested before ClawBench.
How ClawBench Works
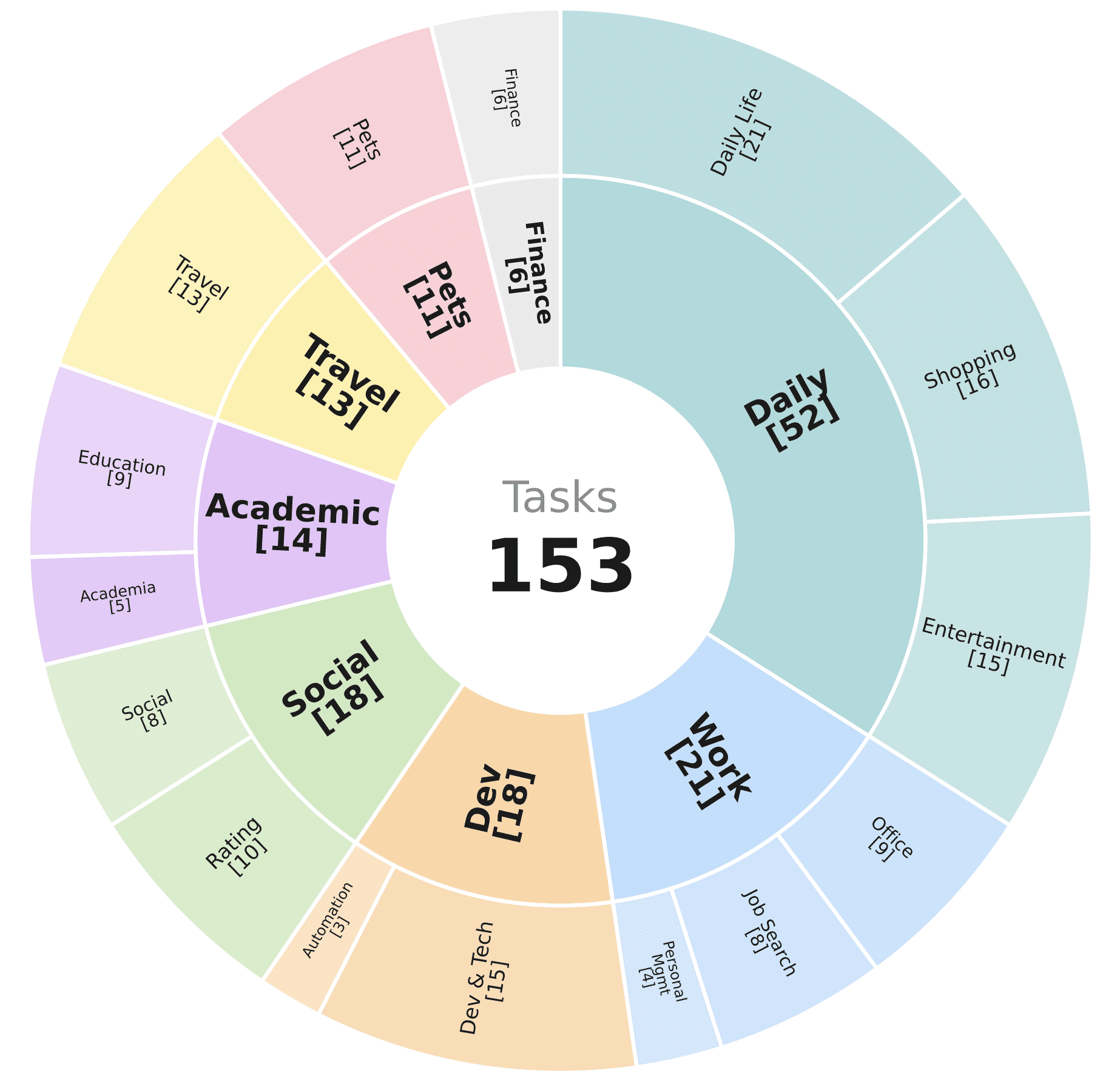
ClawBench contains 153 tasks across 144 real platforms, spanning 15 categories: daily life, shopping, entertainment, office tasks, job search, personal time management, development and technology, automation, ratings and reviews, social networks, academia, education, travel, pets, and finance.
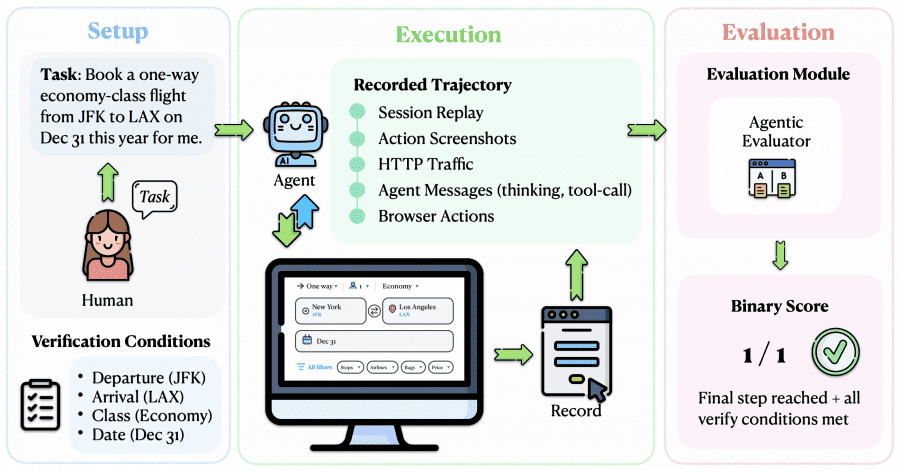
Each task consists of three elements: a natural language instruction (e.g., “book a one-way economy flight from JFK to LAX on December 31”), a starting URL, and a specific HTTP request that should conclude the task. Human annotators completed every task manually, and their actions were recorded as the reference trajectory.
A key technical feature of the benchmark is the final request interception mechanism. To prevent the agent from making real purchases or submitting actual applications, the researchers developed a lightweight Chrome extension and a CDP server (Chrome DevTools Protocol). When the agent reaches the final action — clicking “Pay” or “Submit Application” — the extension intercepts the HTTP request before it reaches the server, saves the request body, and blocks the submission. In a validation study across all 153 tasks, the mechanism correctly intercepted the final request in 100% of cases with zero false positives.
Five-Layer Behavioral Recording
Each agent run captures five types of data simultaneously:
- session recording via Xvfb + FFmpeg (full browser video);
- screenshots after each action;
- HTTP traffic via Chrome DevTools Protocol;
- agent messages — reasoning traces and tool calls in JSON;
- low-level browser actions — clicks, keystrokes, scrolls.
The same five data types are recorded in parallel for the human annotator. This allows comparison not just of the final result, but the entire path: identifying exactly which step the agent diverged from the correct trajectory.
How Evaluation Works
Evaluation is performed by an Agentic Evaluator — a Claude Code sub-agent given the task, the human reference trajectory, and the tested agent’s trajectory. The evaluator compares them step by step, checks whether form fields were filled in correctly, and produces a binary verdict: 0 or 1. A structured justification is also provided — for example, “departure = Toronto ✓, return_date = Aug 07 ✓, type = direct flight ✓”.

This approach is more reliable than simply checking the final URL or screenshot: it identifies exactly what went wrong, not just the fact of failure.
Results Across Seven Models
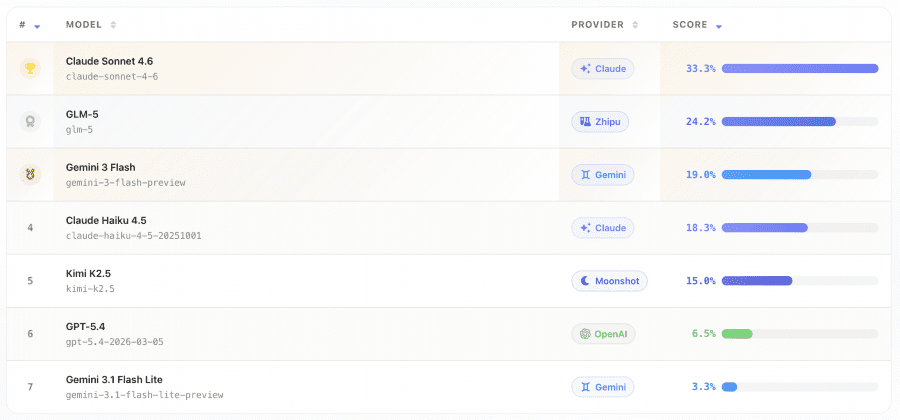
Seven models were tested: Claude Sonnet 4.6, GPT-5.4, Gemini 3 Flash, Claude Haiku 4.5, Gemini 3.1 Flash Lite, GLM-5, and Kimi K2.5.
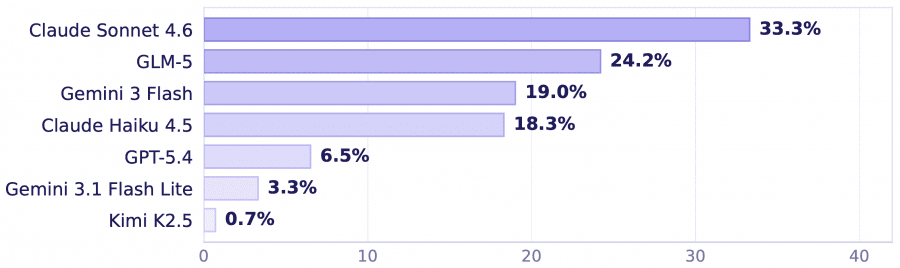
The best result belongs to Claude Sonnet 4.6 — 33.3%. GLM-5 comes second with 24.2%, Gemini 3 Flash — 19.0%, Claude Haiku 4.5 — 18.3%. GPT-5.4 completed only 6.5% of tasks, Gemini 3.1 Flash Lite — 3.3%, and Kimi K2.5 — 0.7%.
For comparison: Claude Sonnet 4.6 scores 72.5–75% on OSWorld and WebArena, GPT-5.4 — 67–72.5%. The gap clearly shows how much more demanding the real web is compared to sandbox environments.
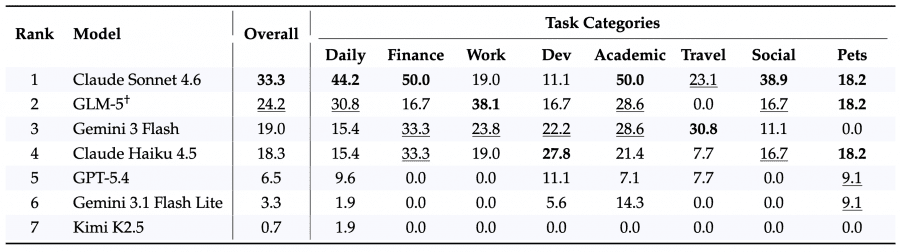
Models perform best on finance and academic tasks: getting an insurance quote on Insurify, enrolling in a Coursera course, or submitting a solution on LeetCode all involve standardized, predictable forms. Travel tasks also fare relatively well — booking FlixBus tickets, searching for flights, and renting cars.
The greatest difficulties arise with development and social tasks. Tasks on GitHub, Airtable, or Confluence involve long multi-step scenarios where a mistake at any step leads to failure. Writing reviews on Glassdoor or Tripadvisor requires precise form completion on sites with constantly changing page structures. Kimi K2.5 failed to complete a single task in almost every category.
Saturation of Existing Benchmarks
An interesting side finding is that classic benchmarks are already nearly saturated. Claude Sonnet 4.6 scores 88% on PinchBench, 77.6% on WildClawBench, 72.5% on OSWorld-Verified, and 66.4% on WebArena-Verified — but only 33.3% on ClawBench.

This means ClawBench is currently one of the few benchmarks where there remains substantial room for improvement for researchers and agent developers.
Why ClawBench Is a Step Forward
ClawBench is the only benchmark that simultaneously operates on live websites, tests data-submission tasks (not just reading), evaluates agents by comparing against a human reference trajectory, and captures a complete picture of what the agent saw, thought, and did at every step. None of its predecessors — WebArena, OSWorld, TheAgentCompany, Mind2Web — combine all of these properties.
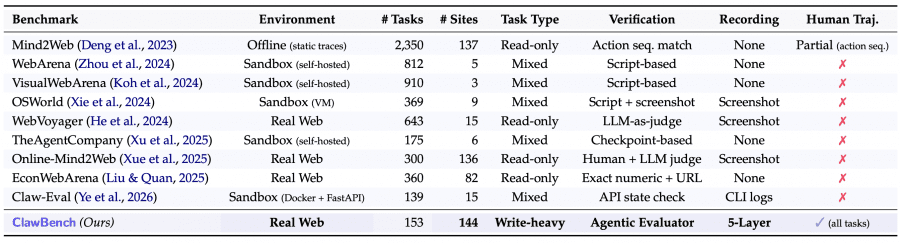
A further key distinction: most previous benchmarks examined only the action sequence or the final URL. ClawBench verifies the actual data the agent was about to send to the server — for example, whether it correctly specified the departure date, ticket class, and route when booking a flight.
Conclusion
ClawBench clearly demonstrates the gap between academic benchmark performance and real-world web interaction. Models that confidently navigate static pages struggle with tasks that are trivial for a human: booking a ticket, placing an order, submitting a job application. The benchmark infrastructure is open, and as new models are released, researchers will be able to track how this gap evolves.



