Researchers from Google AI have proposed a new data augmentation method for automatic speech recognition. The new method is based on a very simple idea and takes a new approach in augmenting audio data.
Deep learning based methods rely on extracting patterns from large amounts of data. In the past, due to the lack of large training datasets, data augmentation techniques were used to augment and increase the size of the available datasets. This was particularly successful in computer vision and tasks such as object detection, image classification, etc.
When it comes to audio data, traditional data augmentation techniques involved modifying the speed (slowing down or speeding up) the audio waveforms or adding some background noise. The problem with these approaches includes computational cost, the need for additional data, etc.
In a novel paper, Daniel Park et al. propose a data augmentation technique for audio data that applies an augmentation policy directly to the audio spectrogram (i.e., an image representation of the waveform).
Generally, the task of automatic speech recognition was tackled by using deep neural networks trained on audio spectrograms, which are images obtained from the audio waveform. However, in the case of data augmentation, it was generally performed on the audio waveform before converting it to a spectrogram.
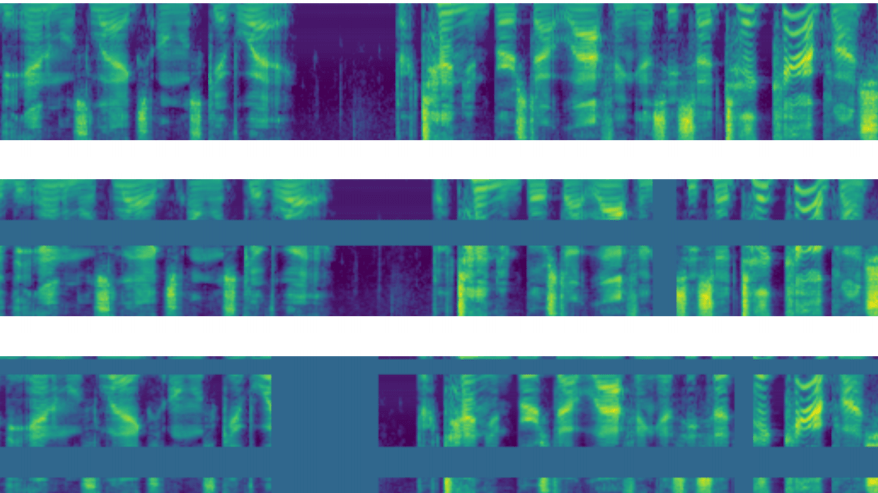
Researchers propose to augment the spectrograms instead of the raw audio waveforms in the novel data augmentation method called SpecAugment.
SpecAugment modifies the spectrogram by warping it in the time direction, masking blocks of consecutive frequency channels, and masking blocks of utterances in time. They show that this kind of data augmentation helps the network to become more robust against deformations in the time domain and loss in the frequency domain.

Researchers performed an evaluation of the proposed method by training end-to-end networks using the LibriSpeech. They used three networks of the Listen Attend and Spell (LAS) type and they compared the results with and without data augmentation.
They show that the method improves the robustness of the neural network models. Also, researchers reported that the method achieves state-of-the-art performance on the LibriSpeech 960h and Swichboard 300h tasks, outperforming all prior work.