
Having large enough amounts of data gives an opportunity to apply Deep Learning methods to almost any task. We have seen in the recent years, the success of deep learning methods and techniques, especially in the area of computer vision. Obtaining large amounts of image data does not represent a major problem nowadays since our cameras have advanced pretty much as well as the transmission and storage capabilities of systems. At the same time, labelling such large amounts of obtained data requires an immense human effort and, in some way, it represents a bottleneck in the whole process of tackling some specific problem.
To better understand wildlife ecosystems, it is necessary to have detailed, large-scale knowledge about the location and behaviour of an animal in the natural ecosystems. Accurate and up-to-date information about the state of the animals in the ecosystem can be crucial towards the objective of studying and conserving the wildlife ecosystems. Ecologists, biologists, and wildlife experts have been putting substantial efforts in the past few decades to save wildlife, and they were trying to raise awareness regarding the importance of wildlife and wilderness.
One common method used by ecologists and biologists for obtaining information about wildlife are camera-trap projects. Putting a large number of cameras at specific locations in the wild has enabled them to study animal population sizes and distributions. However, due to the required human effort for analyzing the images from camera-trap projects, experts are only able to extract little valuable information out of huge amounts of data that they possess.

Joint efforts from researchers from the University of Wyoming; Auburn University, Harvard University, University of Oxford, University of Minnesota, Uber AI Labs has resulted in an accurate method for automated animal identification from camera-trap images. The researchers use Deep Learning techniques, and large labeled datasets to address the problem of automated animal identification in the wild.
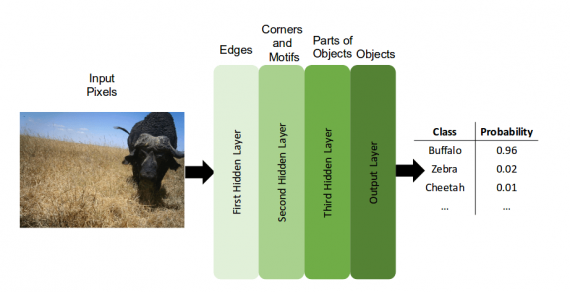
The goal of this project is to apply Deep Learning to be able to identify, count and describe the behavior of animal species. From this definition, the problem can be framed as multitask learning problem using images from camera-trap projects. Arguing that the tasks mentioned above are related and that there are features common to all tasks, the researchers tackle the problem by learning them together. They also argue that by doing so, the tasks can be solved faster, more efficient and it can be easier to store and transmit the model.
Dataset
The researchers use a large-scale labeled dataset coming from the Snapshot Serengeti Project — the world’s largest camera-trap project. This project has 225 camera traps running continuously in Serengeti National Park, Tanzania.
The public Serengeti Dataset that is used in this project contains 3.2 million images corresponding to 1.2 million capture events (note: a capture event represents a moment when the camera identified movement and a few pictures are taken). In this project, researchers focus on capture events that contain only one species, and they removed events containing more than one species from the dataset.
Since most of the time, a capture event is triggered and no animals are present most of the images do not contain any animal. From the human labeling, it turns out that 75% of the dataset is empty (doesn’t include animals). It is worth to mention that the dataset was labeled by volunteers, who in fact labeled the entire capture events (not the individual images alone!). In this approach, the authors focus on labeling and classifying individual images. To do so, they take the labels for each capture event and assign them to all the individual images.
However, taking this approach might be potentially harmful to the learning process, since the transferred labels from events to individual images might often not correspond. In the paper, they argue that adding this kind of “noise” can be overcome by the neural network.
Test set
To evaluate the models, the authors create two tests sets: an expert-labeled test set containing 3800 capture events and a volunteer-labeled test set of 17400 capture events.
Method
The researchers take this into account when tackling the problem in a two-stage manner utilizing a two-stage pipeline:
- (I) detecting presence of an animal (solving the empty vs. animal task)
- (II) identifying which species are present

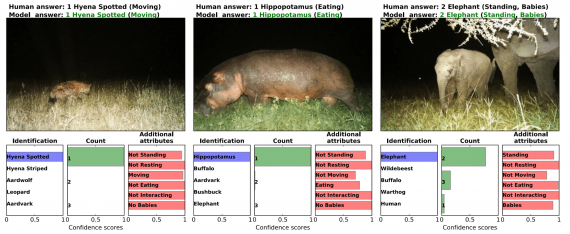
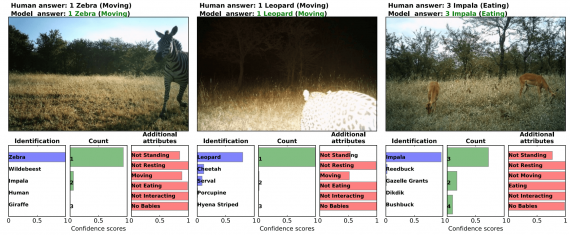
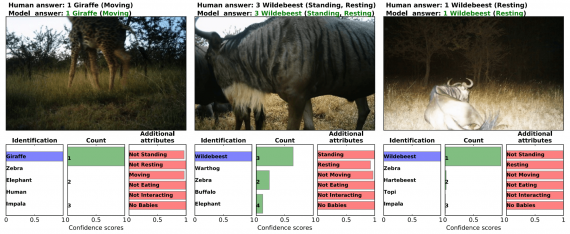
Top-1 and top-5 accuracy of different models on the task of identifying the species of animal present in the image. nt,
- (III) counting the number of animals, and
- (IV) describing additional animal attributes (their behaviour and whether young are present).
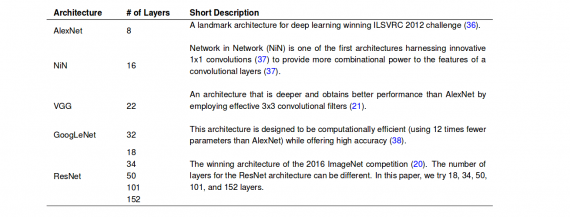
To perform the two main tasks along with the subtasks defined in the information extraction task, the researchers train one model. In fact, throughout the project they investigate different Deep Neural Network architectures, to find the most suitable one for multitask learning in the context of automated animal identification.
Task I: Detecting Images That Contain Animals
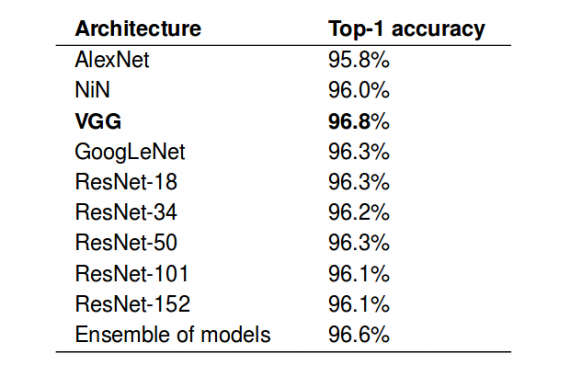
The first task is the easiest of all. It is a binary classification, and the only problem arising in this context is the notable class imbalance. To solve this, they take the 25% non-empty images, and they randomly chose the same amount of data from the rest of 75% of empty images. Doing so, they end up with 1.5 million images out of which 1.4 million for training and 100 000 for testing. As they report, all the classifiers achieve more than 95.8% accuracy on this task with VGG being the best model yielding 96.8%.
Task II: Identifying Species
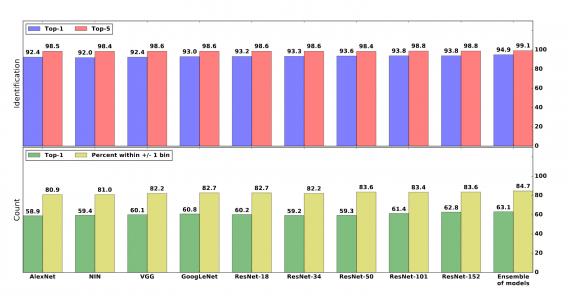
For this task, the authors report the top-1 and top-5 accuracy of the multi-label classification with 48 classes corresponding to 48 species present in the training dataset. The final model reaches 99.1% of top-5 accuracy. In fact, the approach that they use for the specific task of identifying species is ensemble learning — where the prediction is obtained by averaging all the predictions from multiple models. Evaluated on the expert-labeled test set the approach has 94.9% top-1 and 99.1% top-5 accuracy (with the best single model being ResNet-152 obtains 93.8% top-1 and 98.8% top-5 accuracy.
Task III: Counting Animals
To address this issue, the researchers divide possible answer space into 12 bins corresponding to 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11–50, or +51 individuals respectively. For this task, they obtain 63.1% top-1 accuracy and 84.7% of prediction is within +/- 1 bin by the ensemble of models on the expert-labeled test set.
Task IV: Animal Behaviour and Additional Attributes
The Serengeti Dataset contains 6 not mutually exclusive labels defining the behaviour of the animal(s) in the image: standing, resting, moving, eating, interacting, and whether young are present.
A binary classification addresses the possibility to have multiple labels due to the non-exclusivity of the classification problem for each of the labels (predicting whether that behaviour exists or not in the image). Pooled across all attributes, the ensemble of models produces 76.2% accuracy, 86.1% precision, and 81.1% recall.
Работа показала, что глубокое обучение может быть полезно таким экспертам, как биологи и экологи, в их работе по изучению и сохранению дикой природы.
Перевод — Виктор Новосад, оригинал — Dane Mitrev