New research from EPFL sheds light on the internal mechanisms of multilingual data processing in LLMs, which is critical for understanding how modern language models work and how to optimize them. Researchers used the Logit lens method to analyze hidden states in Llama-2 model layers to understand how inference processing occurs across different languages.
Key findings:
- Language processing in LLMs goes through three distinct states
- Middle layers show English language dominance
- Models operate using abstract concepts rather than direct translation
Model Training and Testing
Llama-2 models (7B, 13B, and 70B) were trained on a dataset where nearly 90% of the data was English text, yet even a small 0.13% share of Chinese tokens included 2.6 billion samples. All models demonstrated similar patterns in multilingual data processing.
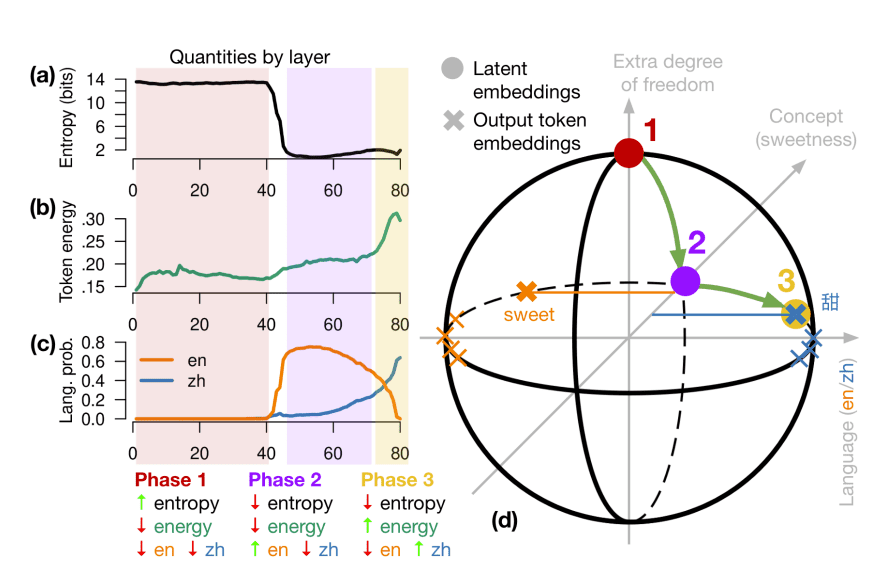
Using energy and entropy metrics, EPFL researchers conducted a detailed analysis of multilingual data processing within the transformer. They identified three distinct information processing phases:
Phase 1 – Initial representation:
- Characterized by high entropy of about 14 bits
- Low token energy indicates the model isn’t yet attempting to predict the next token
- No dominant language
- At this stage, the model forms basic representations of input tokens, maintaining maximum flexibility for further processing
Phase 2 – Conceptual processing:
- Entropy sharply drops to 1-2 bits
- Energy remains low, indicating ongoing processing
- English language begins to dominate, due to its prevalence in training data
- Abstract concepts and semantic connections are formed in this phase
Phase 3 – Target language generation:
- Token energy increases to 20-30%, indicating active preparation for response generation
- Entropy remains low, showing high certainty in next token selection
- Target language dominates
- Abstract concepts are projected into specific language constructs of the output language
These observations confirm that the process is not a simple sequential translation but rather a complex information transformation through intermediate conceptual representation.
Research Results
The EPFL study disproves the common hypothesis about sequential translation in LLMs. Previously, it was thought that models first convert input data into English, process it, and then translate back. However, analysis of Llama-2’s internal states using the Logit lens method revealed a more complex process.
Instead of direct translation, the model forms an intermediate level of abstract concepts – a kind of “language of thought.” While English language dominance is observed in the transformer’s middle layers, this is more a consequence of English prevalence in training data rather than a necessary processing stage. At this level, the model operates with abstract semantic constructs that are then projected into the target language domain.
This discovery has important practical implications for multilingual model development. First, it explains LLMs’ surprising effectiveness with languages poorly represented in training data – the model can use universal conceptual representations formed from richer language data. Second, understanding this mechanism could help develop more effective architectures for zero-shot and few-shot learning, especially for low-resource languages. Finally, this research opens new perspectives for studying language models’ “thinking” and their capacity for abstract reasoning.