Apple Research Team introduced Manzano — a unified multimodal large language model that combines visual content understanding and generation capabilities through a hybrid image tokenizer and carefully designed training strategy. The autoregressive model predicts high-level semantics in the form of text and visual tokens, while an auxiliary diffusion decoder then converts image tokens into pixels. The model achieves SOTA results among unified models and competes with specialized models, particularly on text-rich image understanding tasks.
Manzano Model Architecture
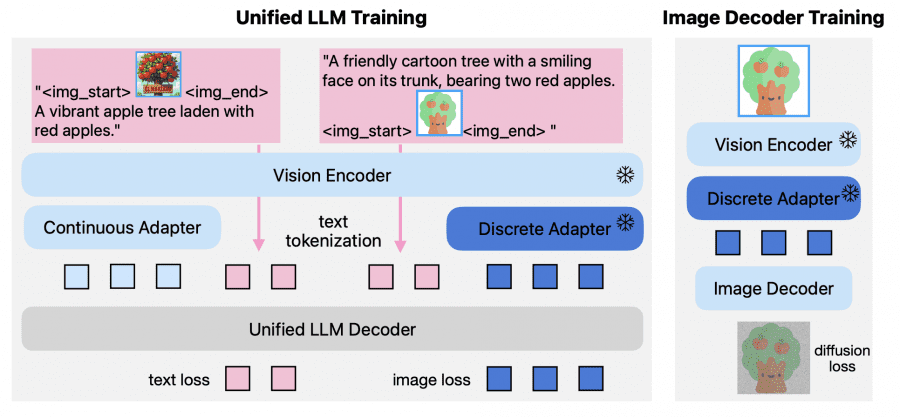
The main problem with existing unified models is the conflict between visual tokenization requirements for understanding and generation. Autoregressive generation typically works with discrete image tokens, while understanding tasks show better results with continuous representations. Manzano solves this problem through a hybrid approach.
The hybrid image tokenizer consists of three components:
- A standard Vision Transformer (ViT) as the backbone
- A continuous adapter for understanding tasks
- A discrete adapter for generation
The continuous adapter applies a 3×3 Spatial-to-Channel layer to compress spatial tokens by 9x (from 42×42×1024 to 14×14×9216), then uses a multi-layer perceptron to project into the large language model dimension. The discrete adapter also starts with compression but additionally quantizes features through Finite Scalar Quantization with a 64K codebook.
The unified LLM decoder uses pre-trained language models and extends the embedding table with 64K image tokens. For image understanding, the tokenizer extracts continuous features and feeds them to the language model with standard next-token loss on text targets. For image generation, the discrete adapter converts input images into a sequence of discrete token IDs, mapping them to image tokens through the extended embedding table.
The image decoder is built on the Diffusion Transformer (DiT-Air) architecture, which uses layer-wise parameter sharing, reducing the size of the standard Multimodal Diffusion Transformer (MMDiT) by approximately 66% while maintaining comparable performance. The decoder uses a flow-matching pipeline to transport Gaussian noise into realistic images, conditioned on discrete tokens from the large language model.
Three-Stage Training Strategy
Manzano uses a specially designed training methodology consisting of three stages with different data proportions and objectives.
Pre-training is conducted on a data mixture in the ratio 40/40/20: image understanding, image generation, and text-only. Models up to 3B parameters are trained on 1.6 trillion tokens, the 30B version on 0.8 trillion. Large-scale corpora are used: 2.3 billion image-text pairs for understanding and 1 billion pairs for generation.
Continued pre-training adds 83 billion high-quality tokens focusing on documents, charts, multilingual OCR, synthetic descriptions, and includes image splitting for better detail understanding.
Supervised fine-tuning uses instruction data in the ratio 41/45/14 for understanding, generation, and text-only respectively. For understanding, a mixture of 75% image-text and 25% text-only is applied, for generation – a combination of real and synthetic data totaling 4 million examples. Loss function weights are balanced at a 1:0.5 ratio for text to images.
Experimental Results
Manzano-3B outperforms unified models up to 7B parameters and competes with specialized models. The most impressive results are achieved on text-rich image understanding tasks: DocVQA (93.5 vs 83.3 for Phi-3-Vision-4B and 40.8 for Janus-Pro-7B), OCRBench (85.7 vs 63.7 for Phi-3-Vision-4B), and MathVista (69.8 vs 44.5 for Phi-3-Vision-4B and 42.5 for Janus-Pro-7B). When scaling to 30B parameters, the model achieves leading positions: ScienceQA (96.2), MMMU (57.8), and MathVista (73.3).
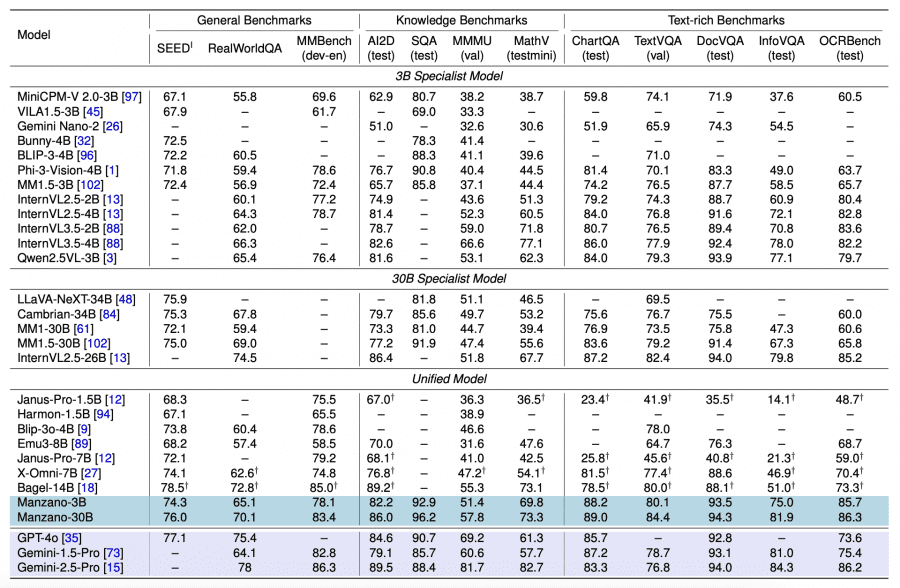
When scaling the LLM decoder from 300M to 30B parameters, consistent improvements are observed across all metrics. Manzano-3B shows gains of +14.2 (General), +18.8 (Knowledge), +10.9 (Text-rich) compared to the 300M version. Further scaling to 30B brings smaller but consistent improvements.
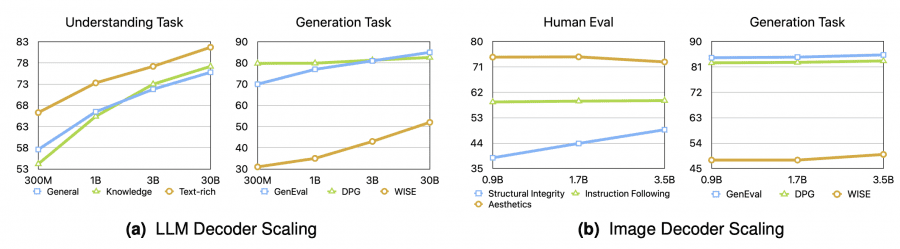
The task conflict study shows minimal degradation: the unified model shows negligible performance decrease compared to models trained only on understanding or only on generation. At 3B size, the gap is less than 1.0 point, demonstrating the success of the hybrid approach.
Image Generation
On GenEval and WISE benchmarks, the model achieves state-of-the-art results among unified MLLMs. Manzano-3B shows competitive or superior results compared to much larger unified models. Scaling to 30B provides significant gains on WISE (+13 points), confirming the architecture’s scaling capability.

Qualitative evaluation confirms quantitative results. The model handles complex instructions, including counter-intuitive requests (“bird flying below elephant”), precise text rendering, and creating images in various artistic styles.
Practical Applications
Manzano supports extended image editing capabilities through joint conditioning of the LLM and image decoder on reference images. The model performs instruction-guided editing, style transfer, inpainting, outpainting, and depth estimation while maintaining semantic coherence with precise pixel-level control.
The architecture allows independent scaling of components: the large language model decoder handles semantic understanding, while the image decoder handles detailed rendering. This creates a flexible foundation for further development of unified multimodal models.
Research results show that combining understanding and generation tasks does not entail accuracy reduction. With proper architectural design and quality visual representations, a compact and scalable model can achieve high results in both areas simultaneously.