A research team from Beihang University, Shanghai Jiao Tong University, the University of Manchester, and IQuest Research has published InCoder-32B-Thinking — a language model with an extended chain-of-thought reasoning for code generation tasks in chip design, GPU optimization, embedded systems, and microcontrollers.
Across 14 general and 9 industrial benchmarks, the model achieved the best results among open-source models of comparable size: 81.3% on LiveCodeBench V5 and 84.0% compilation pass rate on CAD-Coder. The project is fully open: model weights are available on HuggingFace, and the code is on GitHub.
The Problem with Industrial Code
Most modern LLMs handle LeetCode-style tasks or web service development reasonably well, but real production environments are considerably harder. Code for chip design in Verilog/RTL, CUDA kernels for GPUs, or microcontroller firmware all require understanding hardware constraints, timing semantics, and the specifics of compilation toolchains. Publicly available training data rarely captures how an experienced engineer actually reasons through debugging such code — what steps they take, which errors they fix, and why. This “reasoning through errors” is precisely what the researchers set out to synthesize automatically.
Two Key Components: ECoT and ICWM
InCoder-32B-Thinking is built on two complementary mechanisms.
The first is ECoT (Error-driven Chain-of-Thought). Rather than training the model on correct code alone, ECoT generates multi-turn dialogues: the model writes code → the code runs on a real backend → the backend returns an error → the model analyzes the error and revises the code → repeated for up to 4 iterations. This multi-turn trajectory produces a coherent reasoning sequence where the full history of errors and corrections is explicitly captured.
The second is ICWM (Industrial Code World Model). Running a real Verilog compiler or CUDA backend on every iteration is expensive. ICWM is a language model trained to predict what a real backend would return for a given piece of code in a given execution environment. Formally: ICWM(s_env, c^(k)) → ô^(k), where s_env is the environment description (testbench, compiler scripts, memory configuration), c^(k) is the code at iteration k, and ô^(k) is the predicted execution outcome. Once trained, ICWM takes on the role of the compiler — the model no longer needs to invoke the real Verilog or CUDA backend on every iteration to get feedback.
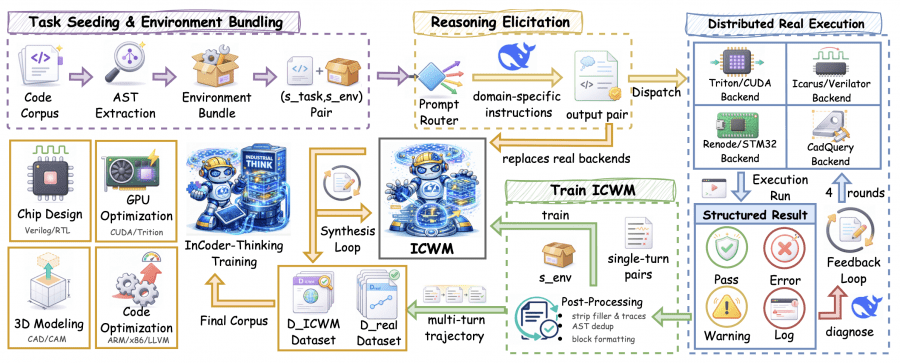
How the Data Pipeline Works
Each task is packaged with its execution environment: Verilog code ships with testbenches and compiler scripts, STM32 firmware comes with memory layout and the required headers. Before generation, a lightweight prompt router selects domain-specific instructions: GPU tasks require the model to reason about shared memory usage and warp divergence; RTL tasks require reasoning about combinational path depth and clock domain crossings. The generator (DeepSeek-V3.2) produces a (reasoning, code) pair, the code is sent to a real backend, and the structured result — a label (PASS / COMPILATION_ERROR / MEMORY_FAULT) plus a diagnostic log — is returned. Both successful and failed attempts are retained: the model needs to see both to learn effectively.
How Accurate Is ICWM?
The key question: can ICWM predictions be trusted enough to replace a real compiler? The researchers validated this on 2,000 held-out execution steps per domain.
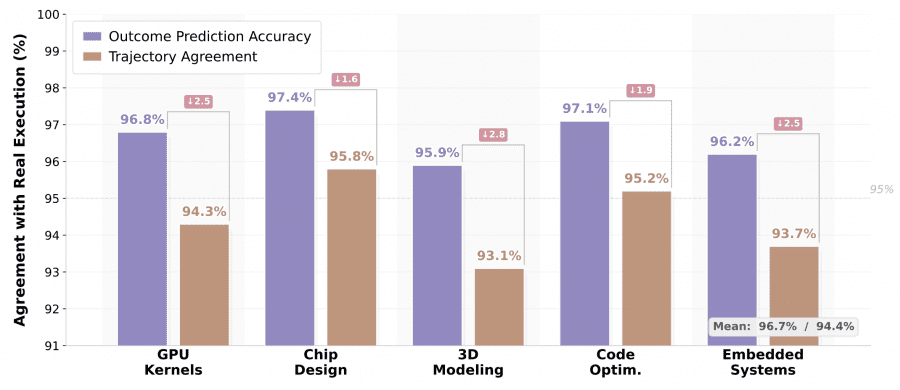
Mean outcome prediction accuracy was 96.7%, and trajectory agreement was 94.4%. Chip design achieved the highest fidelity at 97.4%/95.8%, because the Yosys and Icarus backends produce structured, predictable diagnostic messages. 3D modeling showed the largest gap at 95.9%/93.1%, since CadQuery geometry checks depend on floating-point tolerances and implicit boolean operations that are harder to predict from code text alone.
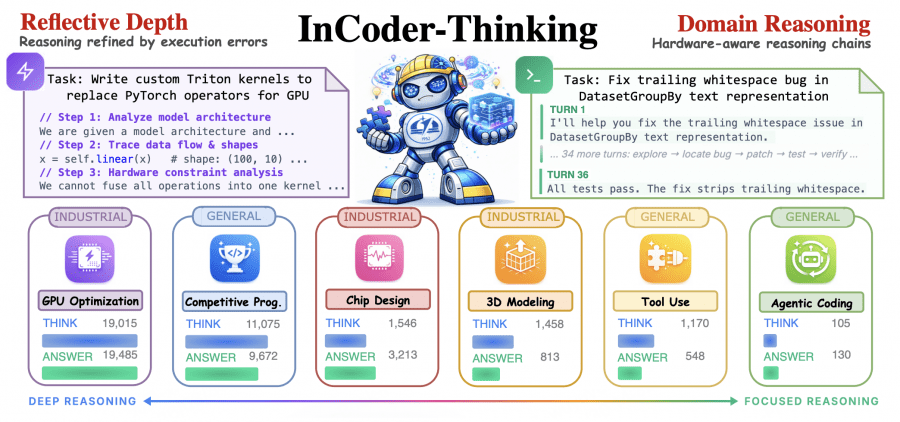
Adaptive Reasoning Depth
One of the more interesting emergent behaviors — not explicitly programmed — is that the model learns to spend exactly as many “thinking tokens” as a given task requires.
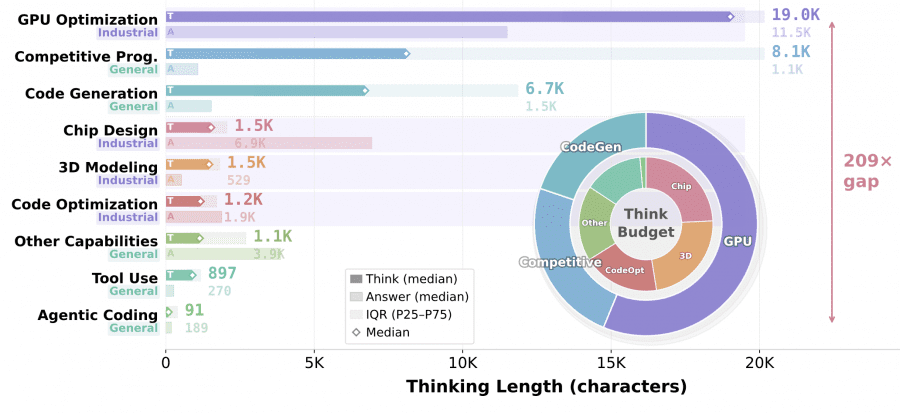
The median length of the <think> block varies by up to 209×: from 91 characters for agentic coding to 19,015 characters for GPU optimization. For agentic tasks, reasoning is distributed across dozens of dialogue turns, with each step simply selecting the next action. For GPU kernels, each correction round requires diagnosing grid/block configuration, shared memory layout, and warp-level scheduling. An interesting pattern appears in chip design: a short <think> block (1.5K characters) paired with a long RTL answer (6.9K), because the Yosys/Icarus backend returns concise structured diagnostics while the Verilog code itself is verbose.
Benchmark Results
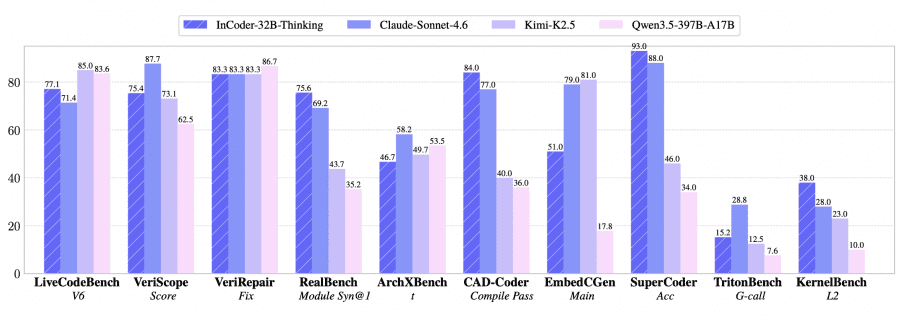
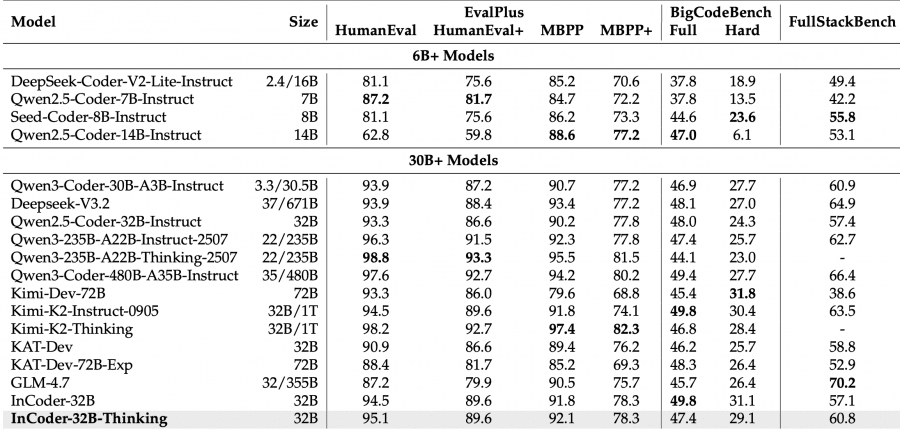
On general code generation benchmarks, the model scores 77.1% on LiveCodeBench V6 and 81.3% on V5 — the best result among open-source models of comparable size. MoE-architecture models like Kimi-K2-Thinking score slightly higher at 83.1% on V5, but with an order of magnitude more parameters (1T vs. 32B).
The industrial benchmark results are more striking. On CAD-Coder (3D modeling): 84.0% compilation pass rate, better than Claude Sonnet 4.6 (77.0%). On KernelBench L2 (GPU kernel optimization): 38.0% vs. 10.0% for Qwen3.5-397B-A17B, which has 12× more parameters. On RealBench (chip design, module level): 75.6% Syn@1, compared to 50.1% for the nearest open-source competitor, Kimi-K2-Instruct.
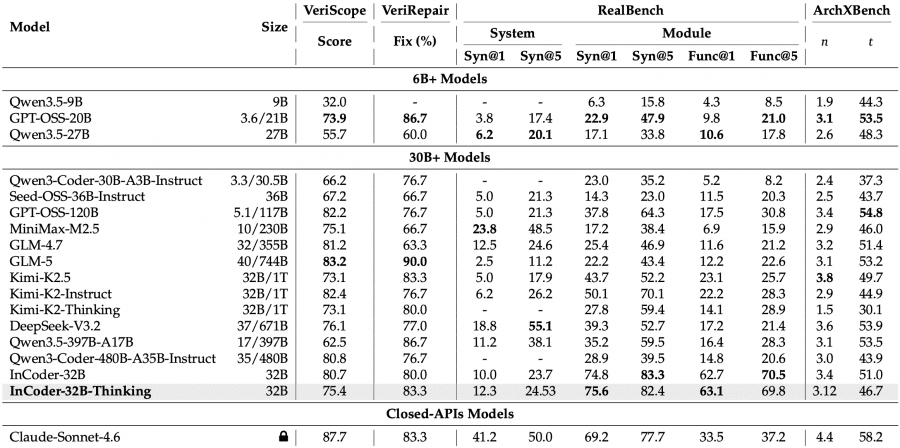
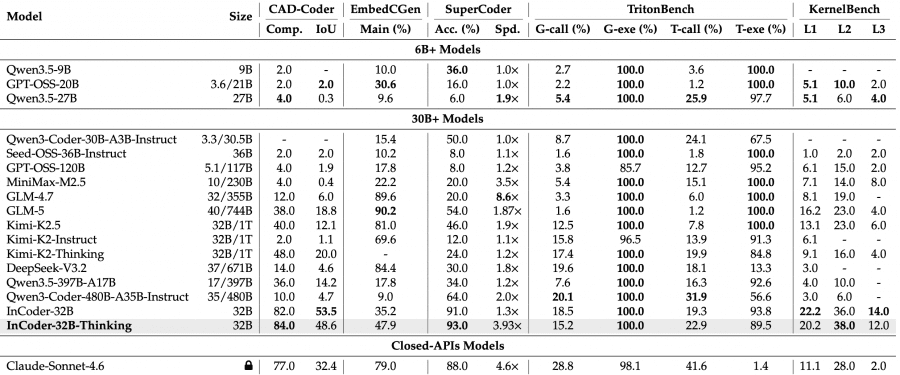
There are weaknesses too: on EmbedCGen (embedded systems), the model scores 47.9% vs. 79.0% for Claude Sonnet 4.6. Embedded C tasks require precise knowledge of HAL functions and peripheral behavior — an area where proprietary models with larger training datasets still have an edge.
Effect of Training Data Scale
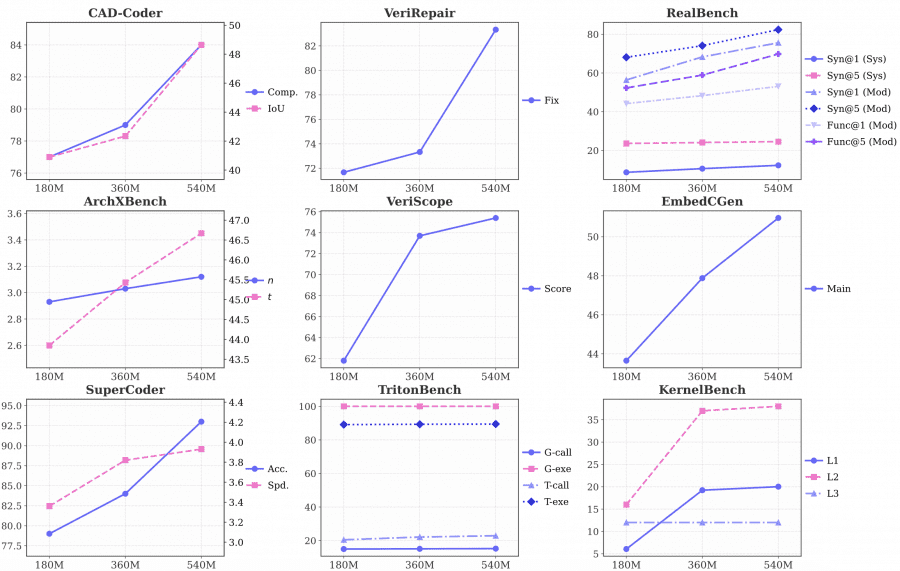
The researchers trained three checkpoints on 180M, 360M, and 540M tokens of step-by-step reasoning data. Most metrics improve monotonically: VeriScope Score rises from 61.8 to 75.4, KernelBench L2 from 16.0 to 38.0. Some metrics plateau — TritonBench execution accuracy holds at 100% across all three checkpoints, suggesting the model masters basic execution tasks early. KernelBench L3 stays at 12.0 across all data volumes, indicating that the hardest optimization problems require different approaches beyond simply adding more data.
How the Base Model InCoder-32B Was Trained
InCoder-32B-Thinking is built on top of the base InCoder-32B, which was trained from scratch using a three-stage Code-Flow pipeline. Understanding this foundation matters, because it explains why the Thinking variant works at all: you cannot teach a model to reason about hardware constraints if it does not understand industrial code in the first place.
In the first stage (pre-training + annealing), the model was trained on industrial code from open repositories, technical documentation, and domain-specific web data. The team applied multi-level deduplication — by exact hash, token-level similarity, and repository fork membership — to prevent the model from overfitting to duplicates of the same project. Training ran on 4,096 GPUs using autoregressive language modeling plus fill-in-the-middle (FIM), a standard technique that allows the model to complete code inserted into the middle of existing code.
In the second stage (mid-training), the context window was extended progressively: first from 8K to 32K tokens for file-level tasks such as RTL module completion, then to 128K for extended debugging sessions. Synthetic QA pairs covering industrial scenarios were added in parallel: task specification → code generation → verification → question-answer pair.
In the third stage (post-training), the model was fine-tuned on 2.5 million examples of real industrial tasks verified through actual execution. The key element was feedback-driven repair trajectories: compiler errors, runtime logs, waveform discrepancies, and GPU profiler bottlenecks. This dataset became the raw material for the ECoT/ICWM mechanisms described above.
How This Differs from Standard Fine-Tuning
The key difference from standard supervised fine-tuning (SFT) is worth spelling out. In conventional fine-tuning, the model learns from (task, correct answer) pairs. Here, the model sees multi-turn trajectories capturing the full process: a first (incorrect) attempt, a concrete compiler error message, a revision, another error, another fix. This mirrors how an engineer actually works with code in a real environment.
The second difference is the role of ICWM as a fast execution environment. Without it, synthesizing enough training trajectories would be prohibitively expensive — every iteration would require invoking a real Verilog compiler or CUDA simulator. ICWM lowers this barrier by replacing most real backend calls with fast language model inference, while maintaining high accuracy (>93% trajectory agreement across all domains).
What Doesn’t Work Yet
The clearest weak point is 3D modeling. ICWM fails most often here: when a CadQuery script is geometrically invalid — for example, a cylinder placed tangent to a rectangular face, creating a degenerate zero-length edge — ICWM may classify the step as PASS while real CadQuery would return GEOMETRY_ERROR. The cause is that geometry checks depend on floating-point values that are hard to predict from code text alone. The researchers address this with periodic audits: a subset of trajectories is always run through real backends, and the corrected labels are used to retrain ICWM.
Another pattern from the benchmark comparisons: models with chain-of-thought reasoning generally perform worse on tasks requiring short, concise answers — for example, Text2SQL and Mercury (code efficiency). This is expected: long step-by-step reasoning helps when a task is complex and multi-step, but extra tokens add no value when the answer is simply a short SQL query.
The main takeaway: a chain of reasoning grounded in real execution feedback — rather than abstract prompt templates — is an effective approach for industrial code. Training data with step-by-step reasoning scales well: more tokens lead to better results on hard tasks. And ICWM makes this synthesis practically feasible without unlimited access to real compilation backends.