MinerU2.5 is a compact vision-language model with 1.2 billion parameters for PDF parsing, introduced by the Shanghai Artificial Intelligence Laboratory team. The model achieves state-of-the-art results in PDF parsing with minimal computational costs through a two-stage processing strategy: structure analysis on downsampled images and detailed recognition of fragments at original resolution. MinerU2.5 is an open-source model. Code is available on GitHub, model weights on Hugging Face.
By the Numbers
- 1.2B parameters vs 1.7-72B in competitors;
- 2.12 PDF pages/second on A100 — 4× faster than MonkeyOCR-pro-3B;
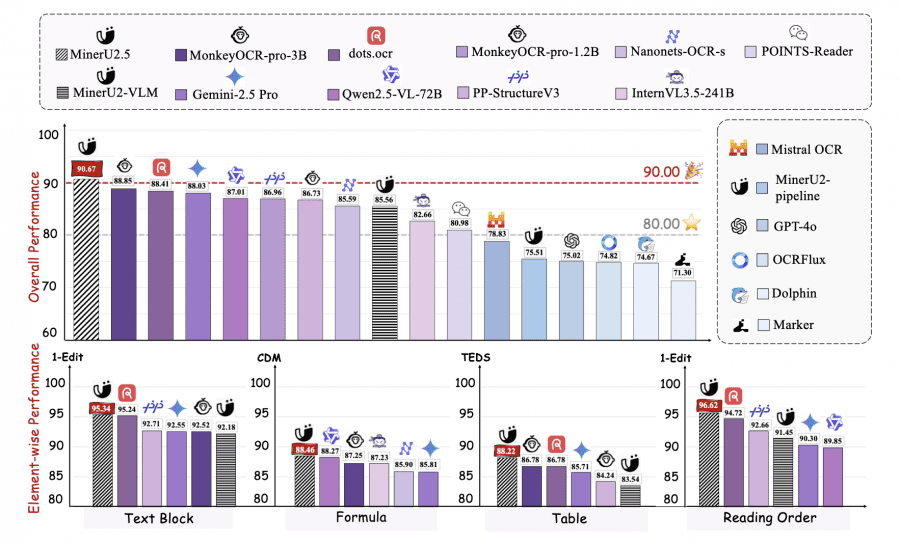
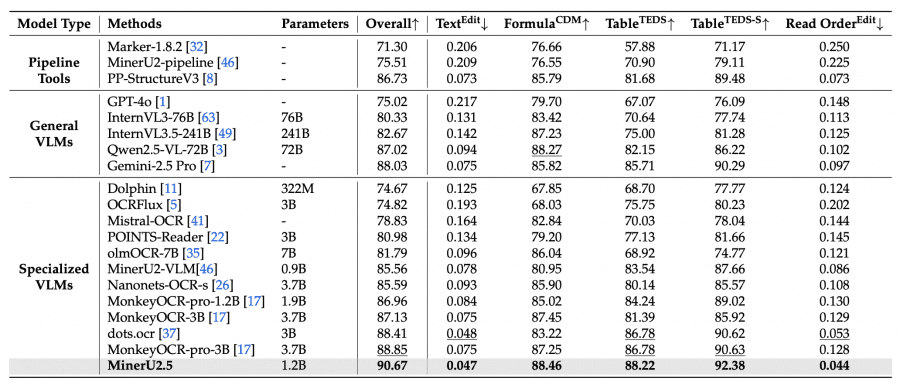
- 90.67 score on OmniDocBench, surpassing dots.ocr (88.41) and MonkeyOCR-pro-3B (88.85).
MinerU2.5 represents a fundamentally different approach to PDF parsing compared to traditional pipeline architectures. Instead of sequentially applying specialized models for each task, it uses a unified vision-language model that separates global structure analysis from local content recognition.
Model Architecture for PDF Parsing
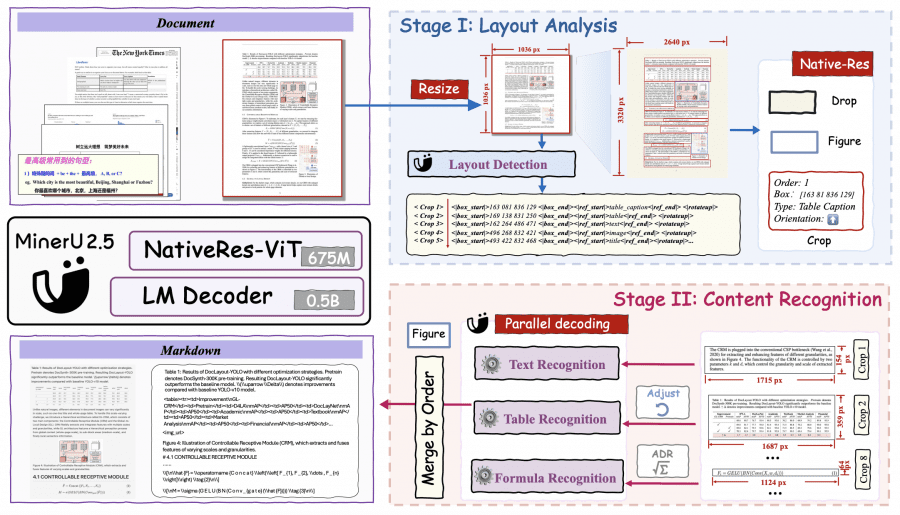
MinerU2.5 consists of three components: a NaViT image encoder with 675 million parameters (initialized from Qwen2-VL), a patch merger module, and a Qwen2-Instruct language model with 0.5 billion parameters. The visual encoder supports dynamic input image resolutions with 2D-RoPE for positional encoding, while the decoder uses M-RoPE instead of standard 1D-RoPE for improved processing of fragments with varying aspect ratios.
In the first stage of PDF parsing, the page is scaled to 1036×1036 pixels for document structure analysis. The size choice balances global structure visibility with computational efficiency — smaller sizes lead to detail loss, while larger ones trigger NaViT’s quadratic complexity. Unlike aspect-ratio-preserving approaches, the fixed thumbnail size improves bounding box localization stability.
In the second stage, the model uses detection results to crop key regions from the original image, which are processed at native resolution with a limit of 2048×28×28 pixels. This prevents detail loss from excessively small fragments and redundant computations from overly large ones.
The two-stage approach reduces computational costs by an order of magnitude compared to end-to-end methods that process entire PDF documents at high resolution with O(N²) quadratic complexity. Task separation enhances parsing interpretability, reduces hallucinations, and allows independent optimization of each stage.
Data Engine and Training
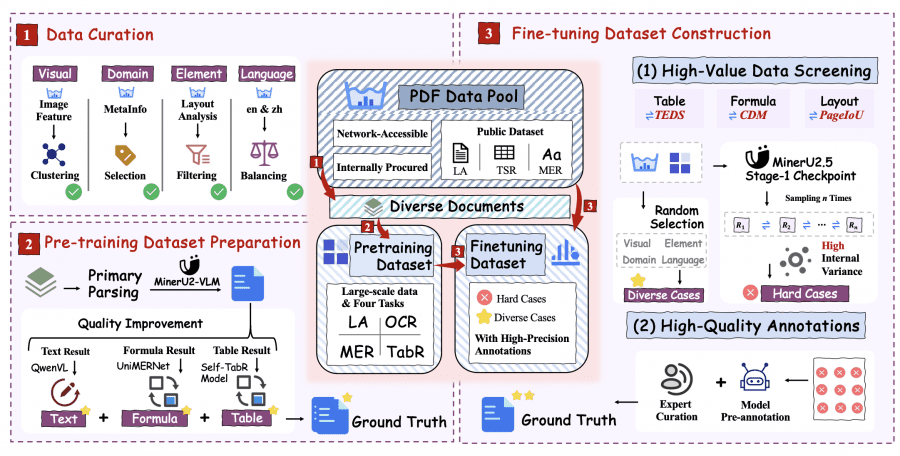
MinerU2.5 training proceeds through three stages. Stage 0 includes two sub-stages: language-image alignment, where only the patch merger module is trained on image-caption pairs from LLaVA-Pretrain, and visual instruction tuning, where all parameters are unfrozen for training on image captioning, visual alignment, and optical character recognition tasks from LLaVA-Instruct.
- Stage 1 (PDF parsing pre-training) uses 6.9 million examples over 2 epochs: 2.3 million for structure analysis, 2.4 million for text blocks, 1.1 million for formulas, and 1.1 million for tables. Documents are scaled to fixed resolution with relative coordinates for structure analysis;
- Stage 2 (PDF parsing fine-tuning) is conducted on a compact dataset of 630 thousand examples over 3 epochs. The dataset includes high-quality examples from Stage 1 and new difficult cases identified through data engineering using the Iterative Mining via Inference Consistency strategy.
This strategy performs multiple inference runs with stochastic sampling for each sample. High result consistency indicates confident prediction, while low consistency indicates a difficult example requiring manual annotation. PageIoU metric is used for structure analysis, CDM for formulas, and TEDS for tables.
For PDF structure analysis, a unified tagging system was developed that includes not only basic elements (text, title, table, formula) but also rarely considered elements (headers, footers, page numbers) and detailed categories (code, algorithm, reference, list). The PageIoU metric measures page coverage at the pixel level, which better corresponds to visual perception compared to traditional intersection-over-union metrics.
For formula recognition in PDF, decomposition into atomic formulas (indivisible semantic units) and compound formulas (ordered sets of atomic formulas) is applied. The Atomic Decomposition & Recombination framework breaks compound formulas into atomic lines through structure analysis, recognizes each line in LaTeX format, and then structurally combines results with correct formatting within alignment environments.
For tables, the Optimized Table-Structure Language is used — an intermediate representation that reduces structural tokens from 28 to 5 and decreases average sequence length by 50% compared to HTML. The processing pipeline includes four stages: table and rotation angle detection, geometry correction, recognition in OTSL format, and conversion to HTML.
PDF Parsing Results and Comparison
MinerU2.5 demonstrates the best PDF parsing results on major benchmarks: 90.67 on OmniDocBench, surpassing MonkeyOCR-pro-3B and dots.ocr across all metrics:
On the Ocean-OCR benchmark, the model achieves edit distance 0.033 and F1-score 0.945 for English text, 0.082 and 0.965 for Chinese:

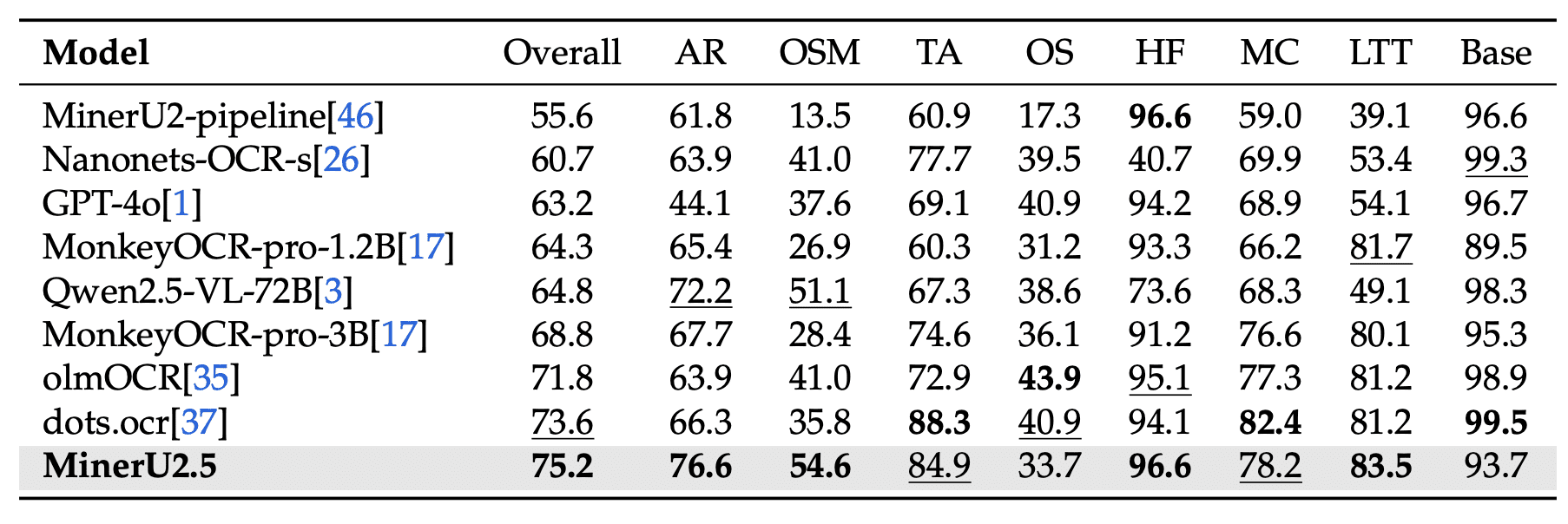
On olmOCR-bench with an overall score of 75.2, MinerU2.5 leads in arXiv Math (76.6) and Old Scans Math (54.6) categories:
PDF parsing performance reaches 2.12 pages/second on A100 80G and 2337.25 tokens/second for stage II, surpassing MonkeyOCR-Pro-3B by 4× and dots.ocr by 7×. On RTX 4090, speed is 1.70 pages/second, on H200 — 4.47 pages/second. Even without deployment optimizations, the model achieves baseline performance of 0.95 pages/second and 1045 tokens/second, surpassing other compared models in standard configurations.
MinerU2.5 demonstrates a compact and efficient architecture for PDF document parsing. The model achieves state-of-the-art results on multiple benchmarks with only 1.2 billion parameters, surpassing significantly larger models in accuracy and processing speed across various PDF document types.