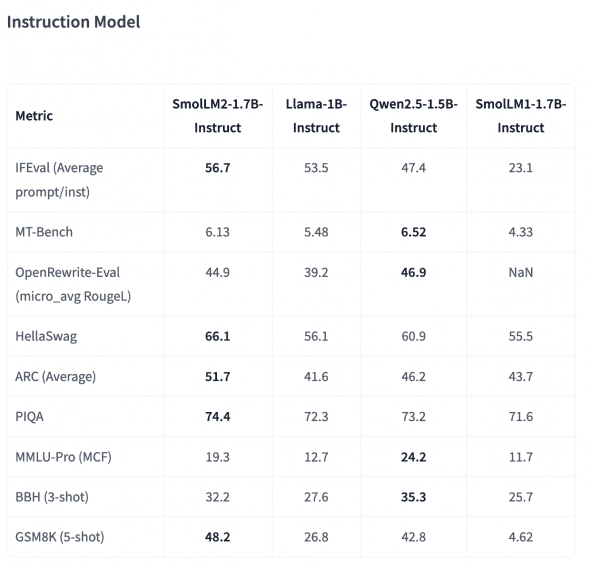
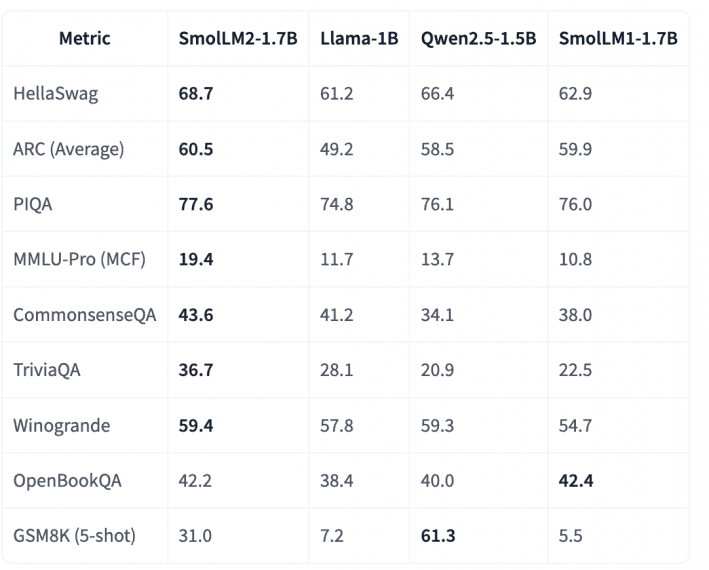
Hugging Face has released SmolLM2 – a new family of compact language models with , demonstrates impressive performance against larger competitors, with its 1.7B parameter version outscoring Llama-1B and Qwen2.5-1.5B across multiple benchmarks. Most notably, SmolLM2-1.7B achieves 68.7% on HellaSwag (vs. 61.2% Llama-1B), 60.5% on ARC Average (vs. 49.2% Llama-1B), and 77.6% on PIQA (vs. 74.8% Llama-1B).
These benchmark results challenge the assumption that larger models always perform better, showing that well-designed compact models can achieve competitive performance while requiring significantly fewer computational resources.
Key Details
- 11 trillion training tokens
- 3 model sizes: 135M, 360M, and 1.7B parameters
- Consistently outperforms models of similar size across key benchmarks
- Architecture: Transformer decoder
Training Details
- bfloat16 precision
- 256 H100 GPUs
- nanotron training framework
Performance characteristics
Benchmark results demonstrate SmolLM2-1.7B’s capabilities against competitors:
- HellaSwag: 68.7% (vs. Llama-1B: 61.2%, Qwen2.5-1.5B: 66.4%)
- ARC Average: 60.5% (vs. Llama-1B: 49.2%, Qwen2.5-1.5B: 58.5%)
- PIQA: 77.6% (vs. Llama-1B: 74.8%, Qwen2.5-1.5B: 76.1%)
Implementation details
The model features instruction-following capabilities developed through supervised fine-tuning (SFT) using both public and curated datasets. Direct Preference Optimization (DPO) with UltraFeedback further enhanced performance. Additional capabilities include text rewriting, summarization, and function calling, supported by Argilla’s Synth-APIGen-v0.1 dataset.
SmolLM2 operates primarily in English, and its outputs should be verified for factual accuracy and consistency.
SmolLM2 offers a compelling solution for developers seeking to implement on-device AI capabilities, balancing performance with computational efficiency under an Apache 2.0 license.