
Researchers from Stepfun AI have developed Step-Video-T2V, a 30-billion-parameter text-to-video model that generates videos up to 204 frames in length, 544×992 resolution, capable of understanding both Chinese and English prompts. The model marks a measurable advance in video generation capabilities, with compression ratios and processing speeds that enable longer, higher-quality video creation from text descriptions.
The model is available through multiple channels including Hugging Face and ModelScope. The open-source release includes the core model, a Turbo version optimized for faster inference, and complete training and inference code.
Step-Video-T2V combines three technological innovations — advanced video compression, transformer architecture, and human preference optimization — to improve video generation quality and efficiency. Researchers have introduced a new compression method that exceeds standard video codec performance by 4x.
The compression system achieves:
- 16×16 spatial compression (vs. industry-standard H.264’s 2x-4x)
- 8x temporal compression (vs. typical 2x-4x)
- 860 seconds for high-resolution video processing

Model Architecture
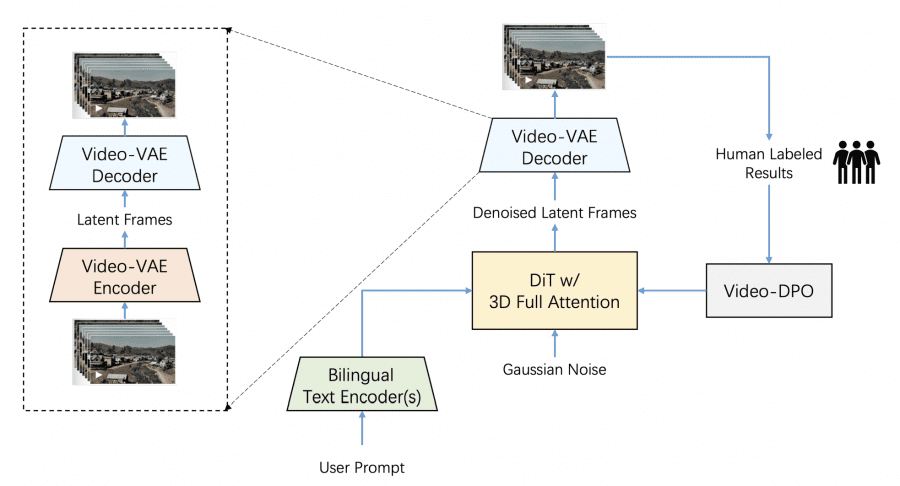
The system integrates three specialized components with the following features and specifications:
- VideoVAE for deep compression while preserving video quality
- DiT (Diffusion Transformer) with 48 layers for processing compressed data
- Dual text encoders for English and Chinese input processing
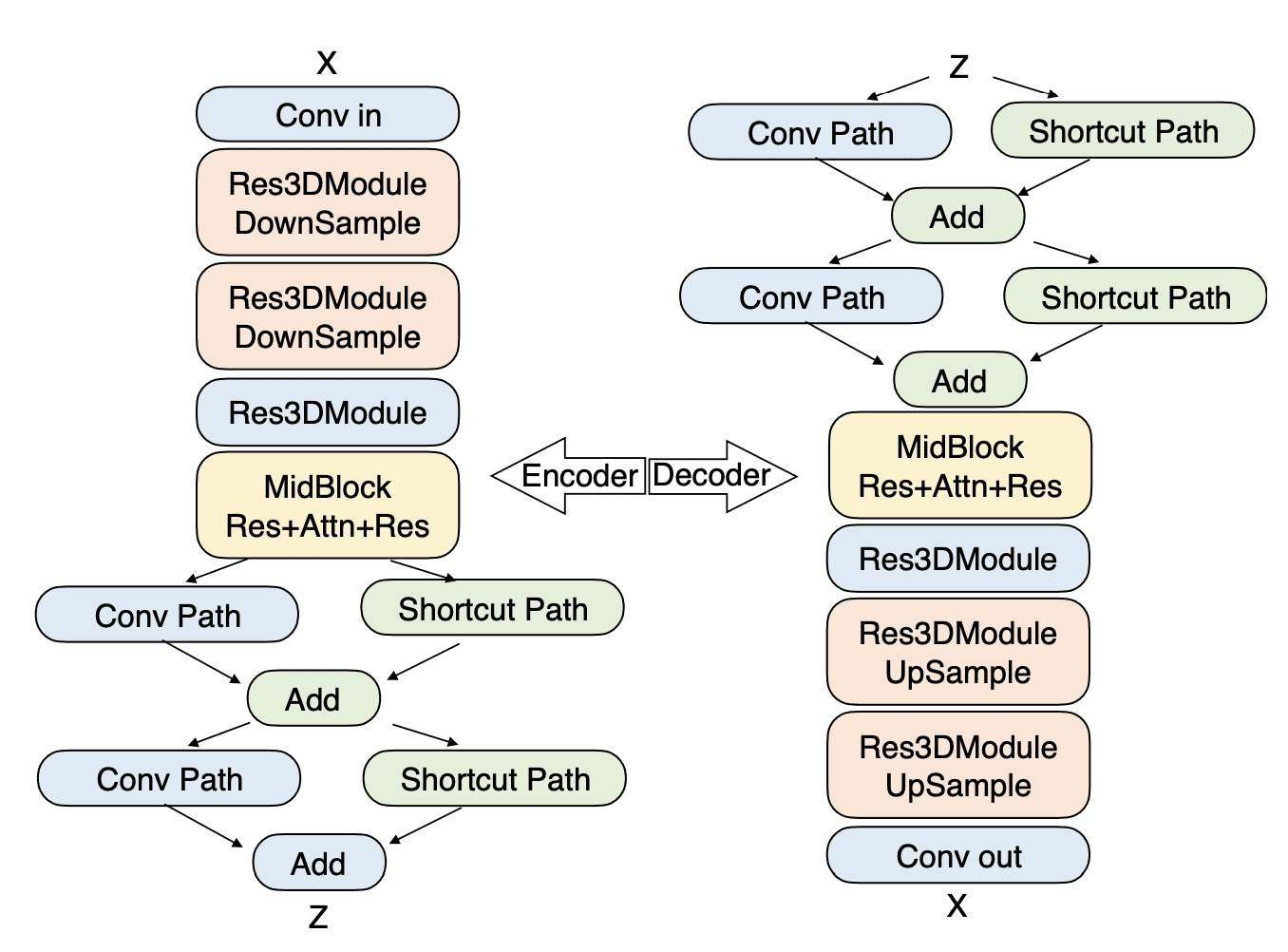
The transformer architecture employs 48 layers with 48 attention heads per layer, operating at 128 dimensions per head. The system uses Direct Preference Optimization (DPO) for quality enhancement, with standard mode using 30-50 inference steps at CFG scale 9.0, and Turbo mode using 10-15 steps at scale 5.0.
Step-Video-T2V resource requirements
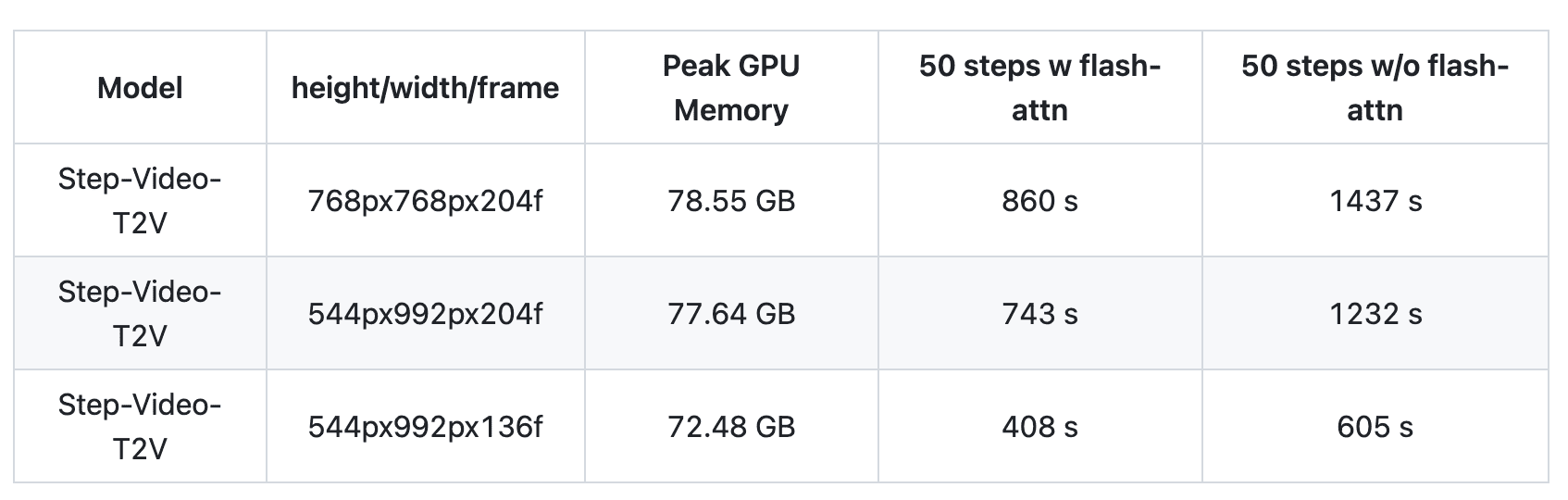
The system needs 80GB of recommended GPU memory, with peak usage at 78.55 GB for 768×768 pixel videos. Processing time ranges from 860-1437 seconds depending on optimization. Software requirements include Python 3.10.0+, PyTorch 2.3-cu121, CUDA Toolkit, FFmpeg, and Linux operating system.
Step-Video-T2V-Eval Benchmark
The Step-Video-T2V-Eval benchmark tests the system using 128 real-world Chinese prompts across 11 distinct categories. These categories span visual arts (3D animation, cinematography, artistic styles), real-world subjects (sports, food, scenery, animals, festivals), and conceptual content (surreal themes, combination concepts, people).
Model results:
Deployment options
The system supports both multi-GPU (4 or 8 GPU parallel processing) and single-GPU configurations with quantization options. Dedicated resources are required for text encoding and VAE decoding.
The open codebase enables researchers and developers to adapt the system for specialized use cases. The project’s modular architecture allows for independent optimization of components like the VAE, DiT, or text encoders. While current applications are limited by resource requirements, future optimizations could broaden accessibility. Community contributions are already focusing on reducing memory requirements and improving inference speed.
Step-Video-T2V represents a measurable advance in AI video generation, with concrete improvements in compression, processing efficiency, and output quality. Its resource requirements currently restrict it to enterprise and research applications. Development efforts focus on reducing computational requirements and expanding accessibility across different computing environments.






