A research team from Shanghai Jiao Tong University and Shanghai Artificial Intelligence Laboratory has introduced Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) — a new approach to training large multimodal models with agentic capabilities. The methodology demonstrates significant improvements in models’ ability to use external tools for solving complex visual tasks. Code is available on Github.
Multimodal Agents
Visual-ARFT addresses a critical gap in the development of multimodal artificial intelligence systems. While language models have achieved significant progress in agentic capabilities, including function calling and tool integration, the development of multimodal agents remains less explored.
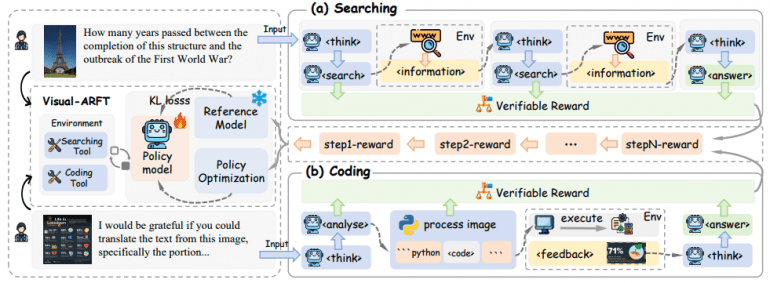
The framework applies reinforcement learning based on verifiable rewards to train Large Vision-Language Models (LVLM) for two critically important scenarios:
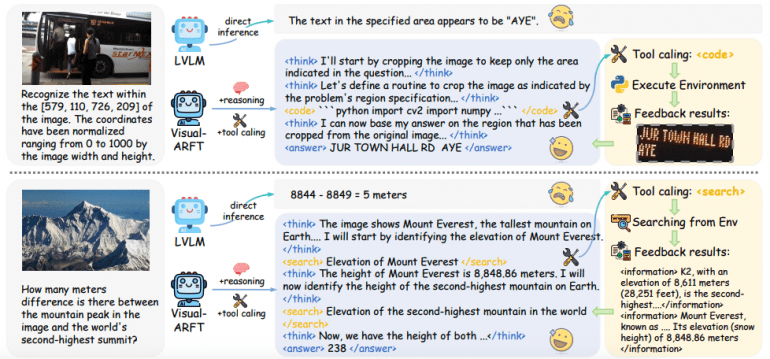
Agentic Search: the model plans, decomposes the original task, and retrieves information from external sources to answer complex multimodal multi-hop VQA questions.
Agentic Coding: the model reasons about the task, writes and executes code for image processing and solving complex visual analysis tasks.
Technical Implementation
Reward System
Visual-ARFT uses a modular system of verifiable rewards:
Format Reward ensures compliance with a predefined output format, including tags <think>, <search>, and <code>. This stimulates structured step-by-step reasoning and correct tool usage.
Accuracy Rewards evaluate the quality of final answers using F1-score, semantic similarity for search queries, and executability of generated code.
Training Algorithm
Researchers apply Group Relative Policy Optimization (GRPO) to update the model’s policy based on reward feedback. KL divergence prevents excessive deviation of the updated policy from the reference model.
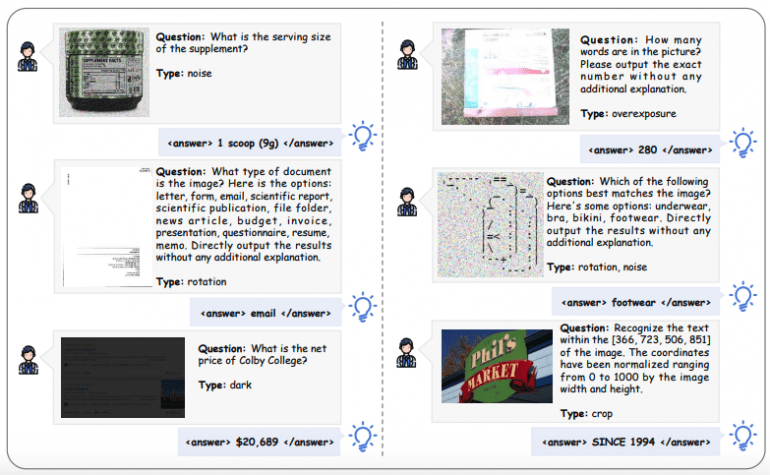
Multimodal Agentic Tool Bench (MAT)
To support training and evaluation, the team introduced MAT — a benchmark including two subsets:
MAT-Search: 150 high-quality multimodal multi-hop VQA examples requiring external knowledge retrieval.
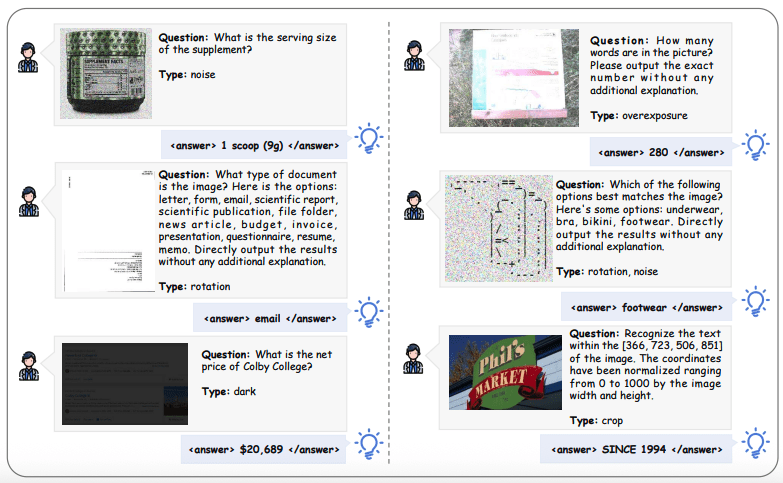
MAT-Coding: 200 examples with various types of image distortions (rotation, darkening, blurring, noise) requiring preprocessing through code.
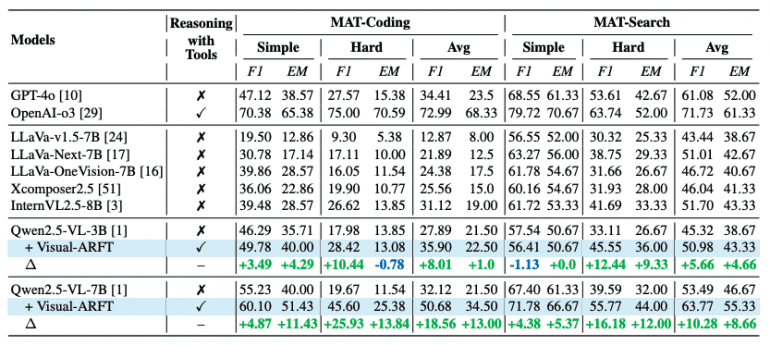
Quantitative Results
Visual-ARFT’s effectiveness is confirmed by impressive empirical data:
On MAT-Coding, the Qwen2.5-VL-7B model with Visual-ARFT achieves improvements of +18.56% F1 and +13.00% EM compared to the baseline version, surpassing GPT-4o.
On MAT-Search, the same model demonstrates gains of +10.28% F1 and +8.66% EM.
When evaluated on external multi-hop QA benchmarks, Visual-ARFT shows robust generalization with gains of +29.3% F1 and +25.9% EM on 2WikiMultihopQA and HotpotQA.
Practical Applications
The approach demonstrates several key advantages:
Training Process Control: developers can precisely control the information that AI encounters during training, leading to more reliable results.
Framework Flexibility: Visual-ARFT is compatible with widely used RL algorithms, including PPO, GRPO, and Reinforce++.
Reduced Dependencies: the technique points to a future where AI systems can develop sophisticated capabilities through simulation, reducing dependence on external services.

Future Directions
Visual-ARFT represents a promising path toward creating robust and generalizable multimodal agents. The approach demonstrates that effective training of agentic capabilities is possible with minimal annotated data — just 20 examples for agentic search and 1200 for agentic coding.
The research opens new possibilities for developing open-source multimodal AI agents with strong reasoning and tool-use capabilities, potentially changing the economics of AI development and reducing dependence on major technology platforms.
This evidence-based approach to training LVLMs with agentic capabilities represents a viable alternative to traditional methods, with documented improvements in performance and training stability.