DeepEyesV2: Multimodal Model Learns to Use Tools to Solve Complex TasksRetry
12 November 2025

DeepEyesV2: Multimodal Model Learns to Use Tools to Solve Complex TasksRetry
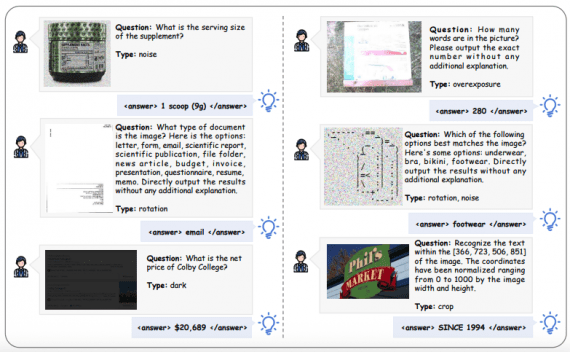
Researchers from Xiaohongshu introduced DeepEyesV2 — an agentic multimodal model based on Qwen2.5-VL-7B that can not only understand text and images but also actively use external tools: execute Python code…