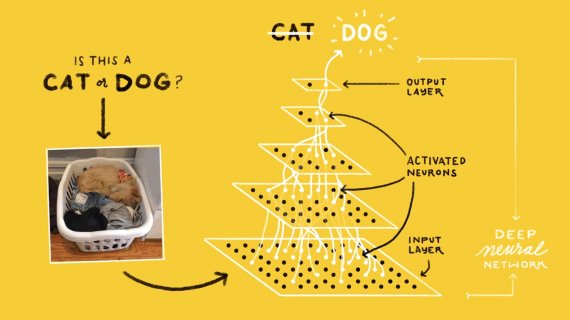
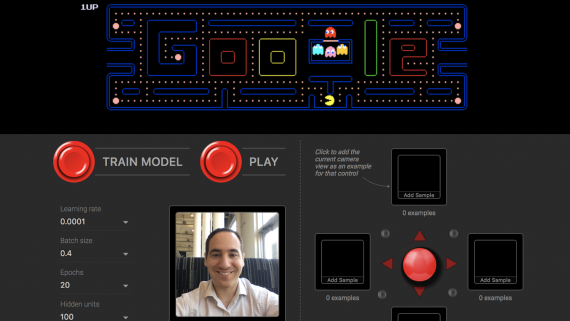
Туториал TensorFlow для мобильных устройств на Android и iOS
21 декабря 2018

Туториал TensorFlow для мобильных устройств на Android и iOS
TensorFlow обычно используется для тренировки масштабных моделей на большом наборе данных, но нельзя игнорировать развивающийся рынок смартфонов и необходимость создавать будущее, основанное на глубоком обучении. Перед вами перевод статьи TensorFlow on…