
Nvidia has unveiled GANcraft, a neural network for creating photorealistic images based on 3D block worlds, similar to the worlds in Minecraft. GANcraft creates a visualization of a world, taking over its structure and adding photorealism. The framework allows you to set the trajectory of the camera and the style of the output images. The model does not require training on new input data to generate corresponding frames.
Why is it needed
“Imagine a world in which every Minecrafter is a 3D artist!” – Nvidia
GANcraft simplifies the process of 3D modeling complex landscape scenes. It has application in areas where landscape generation is needed.
The neural network accepts the following data as input:
- a world made up of blocks with labels such as mud, grass, wood, sand, or water;
- camera trajectory;
- styling image or styling options.
At the output, the neural network generates a video from the camera’s point of view.
Difference compared to previous methods
Comparing modern methods results, authors noted several problems:
- MUNIT and SPADE do not maintain viewpoint consistency (the same objects are generated differently with different viewpoints);
- wc-vid2vid creates a video with consistent viewpoints, but image quality degrades over time due to errors accumulation;
- Nvidia’s NSVF-W does the job, but the output image lacks fine details and looks boring.
In contrast, GANcraft generates detailed footage with consistent viewpoints.
How it works
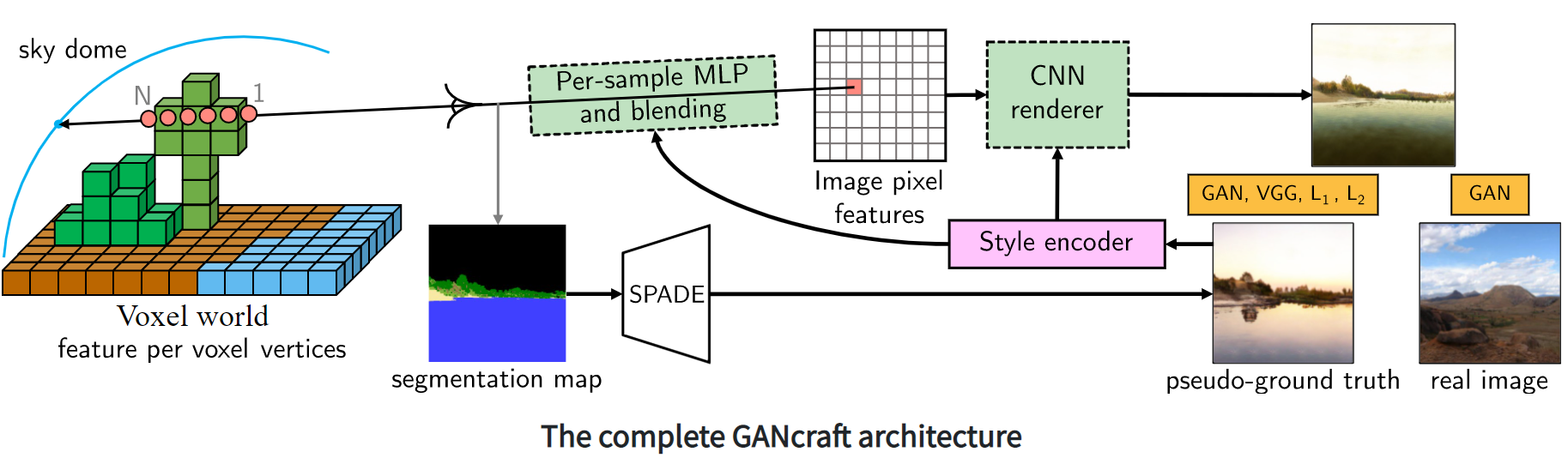
- First of all, each corner of the block is assigned a set of properties that reflect its appearance and geometry.
- For randomly selected camera viewpoints, a search is performed for intersections of view rays with a grid of blocks. Trilinear interpolation of block properties at specified intersections is performed.
- The result of interpolation proceeds to the input of the multilayer perceptron, which outputs a set of properties for the output image pixels.
- The last stage of preparing a frame is a convolutional neural network that performs rendering.
In steps 3 and 4, the output image is styled.
Besides, the SPADE tool is used for fast and stable unsupervised learning. It generates realistic images for individual frames, which are used to compute a loss function of the convolutional neural network. This achieves the closeness of a result with a consistent viewpoint to a realistic picture. It provides landscapes with suitable angles as “true” images for the neural network.








