
Genmo AI has introduced Mochi 1, an open-source video generation model featuring Asymmetric Diffusion Transformer (AsymmDiT) architecture. With 10 billion parameters, it closes the gap between closed and open systems, providing enhanced motion quality and prompt adherence. Available under Apache 2.0 license, it can be accessed on Hugging Face, and tested at genmo.ai/play.
Introducing Mochi 1 preview. A new SOTA in open-source video generation. Apache 2.0.
magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/announce pic.twitter.com/YzmLQ9g103
— Genmo (@genmoai) October 22, 2024
Key Features
- Text-to-video only;
- Built on a 10 billion parameter diffusion model with efficient asymmetric design that allocates more capacity to visual processing. Uses a T5-XXL language model for streamlined prompt encoding.
- Compresses videos to 128x smaller using AsymmVAE for fast, high-quality outputs.
- Generates videos at 30 fps, supporting durations up to 5.4 seconds with smooth, realistic motion.
- Ensures accurate alignment with user instructions, evaluated using standardized benchmarks.
Pioneer Open-source Video Generation Model Architecture
Mochi 1 boasts a massive 10 billion parameters, built on Genmo’s AsymmDiT architecture, the largest of its kind openly released. This innovative architecture utilizes an asymmetric design where visual processing capacity is significantly higher than text processing. A single T5-XXL language model encodes user prompts, differing from other models that rely on multiple pre-trained language models. Mochi’s efficient use of QKV projections and non-square layers streamlines inference, optimizing memory usage and processing speed.
AsymmVAE Compression: Alongside Mochi 1, Genmo introduces AsymmVAE, a high-efficiency video compression model. Utilizing an asymmetric encoder-decoder, it compresses videos to a 128x smaller size, maintaining quality with an 8×8 spatial and 6x temporal compression. This integration ensures fast, high-quality video output, compatible with the demands of real-time generation.
Video Generation Performance and Evaluations
Mochi 1 generates 480p videos at 30 frames per second with high temporal coherence. Tests show smooth simulation of complex motions like fluid dynamics and realistic human gestures. Prompt adherence ensures accurate alignment with user inputs.
Genmo has updated their game, generations much better, but lack sharpness pic.twitter.com/dXnm0L5h6N
— Myron (@seirdotmk) October 23, 2024
Prompt Adherence: Outperforms major models like Luma Dream Machine, achieving a ~78% adherence rate. The visual comparison shows Mochi 1 leading in prompt accuracy.
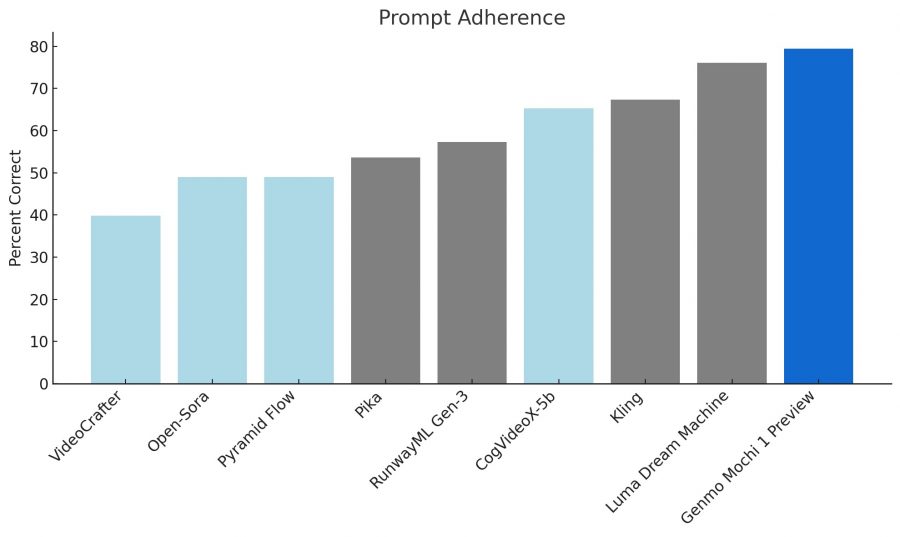
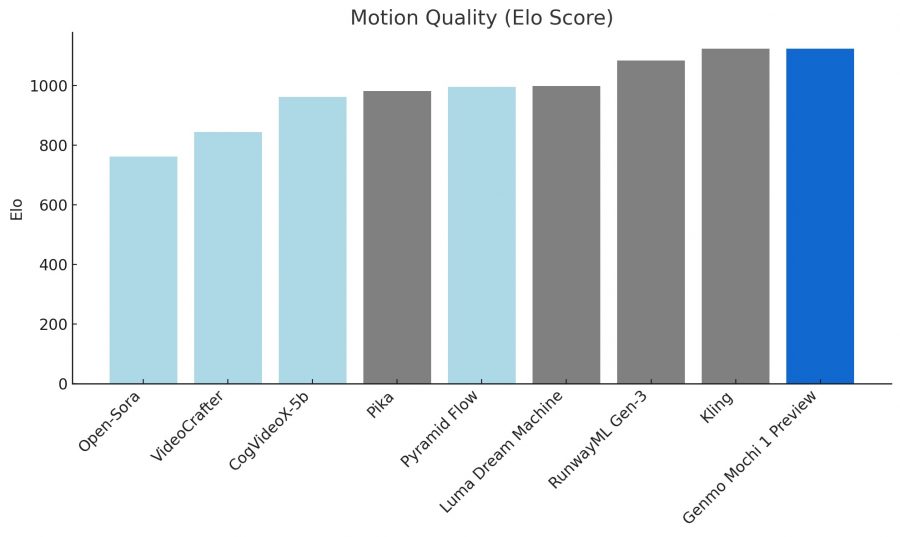
Motion Quality (Elo Score): Scored highest among models, reflecting better motion fluidity and dynamics.
Unfortunately, technical paper was not released by developers.
Hardware Requirements
The model demands at least 4 H100 GPUs to run efficiently. Efforts are ongoing to reduce these requirements for wider accessibility.
Limitations
Mochi 1 open-source video generation model is still under preview, generating videos at 480p. Some edge cases show minor warping, and it is currently best suited for photorealistic styles. Animated content support remains limited.
Safety and Future Directions in Open Source Video Generation
Genmo integrates robust moderation to ensure ethical usage. Community engagement is encouraged for further development. Future updates will include HD video and comprehensive optimization.
Conclusion
Mochi 1 marks a significant step for open-source video generation, bringing complex visual-text integration into a simple, hackable framework. With continuous improvements and community contributions, it is poised to expand the possibilities of AI-driven video generation.





