A team of more than 50 researchers from around the world — from Berkeley, Stanford, CMU, Oxford and other universities — has published Very Big Video Reasoning (VBVR), a massive dataset for training video models to reason. This is the first dataset of this scale that teaches video models not just to generate a sequence of frames, but to think — to solve problems involving space, physics, abstraction, and logic. Based on the dataset, the authors created the VBVR-Bench benchmark, which tests the reasoning capabilities of video models. An open-source Wan2.2 model fine-tuned on the VBVR dataset outperformed all closed commercial models, including Sora 2 and Veo 3.1, on reasoning tasks. The project is fully open: the dataset, fine-tuned model weights, benchmark code, and task generators are available on GitHub and Hugging Face.
Why Does This Matter?
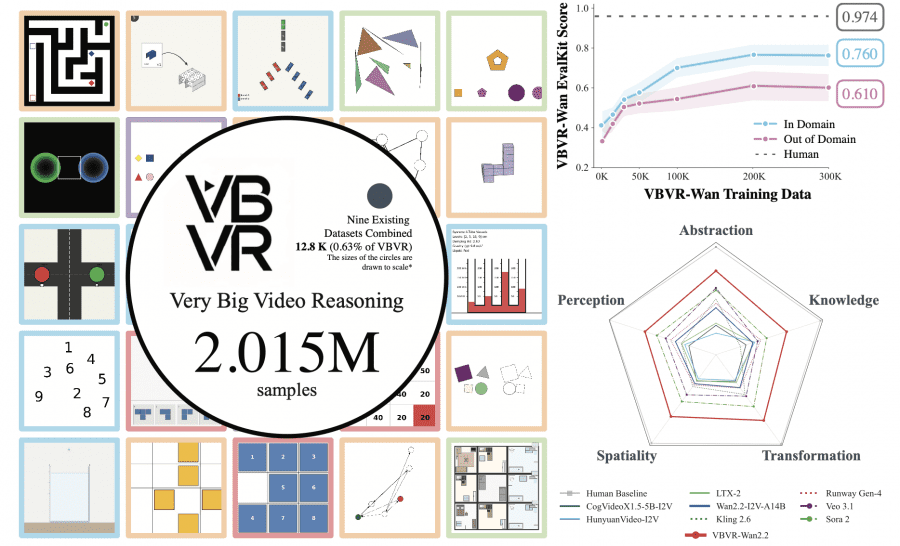
Modern video models — Sora, Veo, Kling, Wan — can produce strikingly realistic videos. But ask them to navigate a maze or simulate the physics of a bouncing ball, and they fall apart. The problem is not generation — it is reasoning. And training data for this specific skill was almost nonexistent: all existing datasets combined contained around 12,800 examples. VBVR contains 2,015,000 examples — roughly 157 times more.
How the Task Taxonomy Works
The authors did not just collect random tasks. They drew on cognitive science — from Aristotle to modern neuroscience — and identified five fundamental faculties of the human mind, which form the backbone of the dataset.
- Perception — the ability to extract structure from sensory input: identifying color, shape, finding a unique object among identical ones.
- Transformation — manipulation of mental representations: rotating objects in the mind, predicting trajectories.
- Spatiality — navigation and understanding of geometric relationships between objects.
- Abstraction — finding patterns and applying rules: Raven’s matrices and sorting tasks.
- Knowledge — applying facts about the world: laws of physics, fluid behavior, reading clocks.
150 out of 200 task types are already publicly available; the remaining 50 are held back for a fair leaderboard — so that no one can fine-tune a model specifically to game the benchmark.
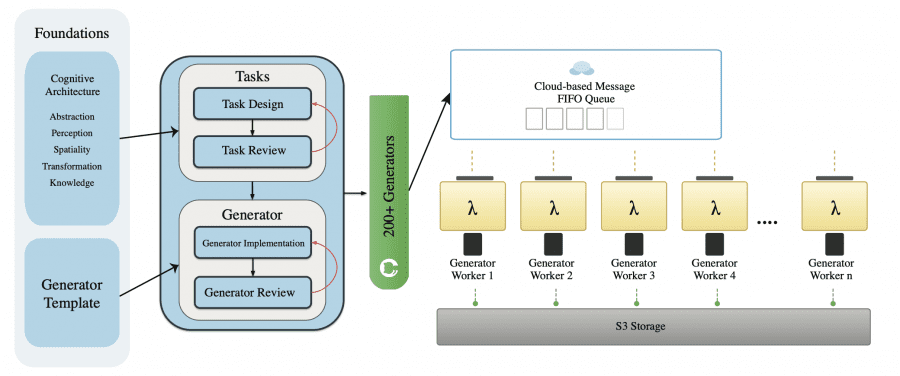
How the Data Is Generated
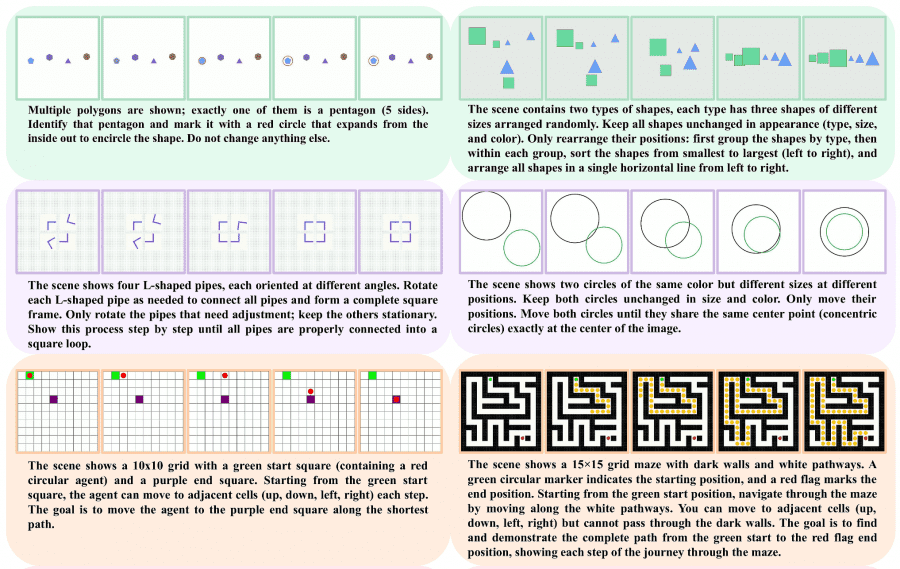
Instead of manual annotation, the authors wrote parametric generators — programs that create tasks automatically. Each generator takes a set of parameters — grid size, number of objects, obstacle placement — and outputs four components: an initial frame (first_frame.png), a text instruction (prompt.txt), a final frame (final_frame.png), and the correct solution as a video (ground_truth.mp4). The solution is computed algorithmically — for example, via breadth-first search for shortest path problems. During inference, the model only sees the first two components — the initial frame and the text instruction — and must generate a video with the solution. The final frame and the ground-truth video are hidden from the model: they are used only to check whether the model solved the task correctly.
Generation runs in parallel across 990 AWS Lambda servers simultaneously. One million examples are generated in roughly 2–4 hours at a cost of around $800–1,200 per run. Every example is automatically validated: does a solution exist, do objects overlap, is the text legible. The error rate is under 1%.
How Models Are Evaluated
VBVR-Bench is an evaluation framework with one key difference from most alternatives: no LLM judges. Evaluation is fully deterministic and rule-based. For a navigation task, it checks whether the agent reached the goal, whether it passed through walls, and how optimal the chosen path was. Each of the 100 test tasks has its own scoring module with weighted criteria.
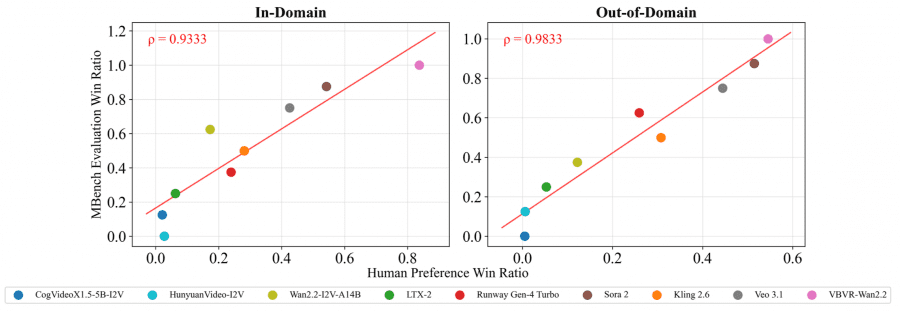
To verify that automatic scores align with human judgment, the authors ran a large-scale experiment: annotators watched videos and rated them on three criteria — whether the task was completed, whether the reasoning logic was correct, and whether the video quality was good. The Spearman correlation between automatic metrics and human ratings was ρ > 0.93 for in-domain tasks and ρ > 0.98 for out-of-domain. These are very high values.
Results
The results are discouraging for existing models, but promising for the fine-tuned version. Among open-source models, the best result belongs to Wan2.2-I2V-A14B — 0.371 out of 1.0. Among closed models, Sora 2 leads with 0.546, followed by Veo 3.1 at 0.480. The human baseline is 0.974. The gap is enormous.
But when the authors fine-tuned Wan2.2 on the VBVR dataset using a LoRA adapter with rank=32, the score rose to 0.685 — an 84.6% improvement over the base model. VBVR-Wan2.2 outperforms all other models, including closed commercial ones.
| Model | Overall | In-Domain | Out-of-Domain |
|---|---|---|---|
| Human baseline | 0.974 | 0.960 | 0.988 |
| VBVR-Wan2.2 (fine-tuned) | 0.685 | 0.760 | 0.610 |
| Sora 2 | 0.546 | 0.569 | 0.523 |
| Veo 3.1 | 0.480 | 0.531 | 0.429 |
| Runway Gen-4 | 0.403 | 0.392 | 0.414 |
| Wan2.2 (base) | 0.371 | 0.412 | 0.329 |
How Performance Scales with More Data
The authors trained the model on varying data volumes — from 0 to 500,000 examples — and tracked performance changes. From 0 to 200K examples, the gain is substantial (from 0.412 to 0.767 on in-domain tasks). After 200K, the curve plateaus and begins to fluctuate. This suggests that simply adding more data of the same type is not enough — architectural changes or fundamentally new task types are needed.
Importantly, both in-domain and out-of-domain scores improve together, indicating genuine generalization rather than memorization. A gap of around 15% between them persists, and closing it is the next major challenge for researchers.
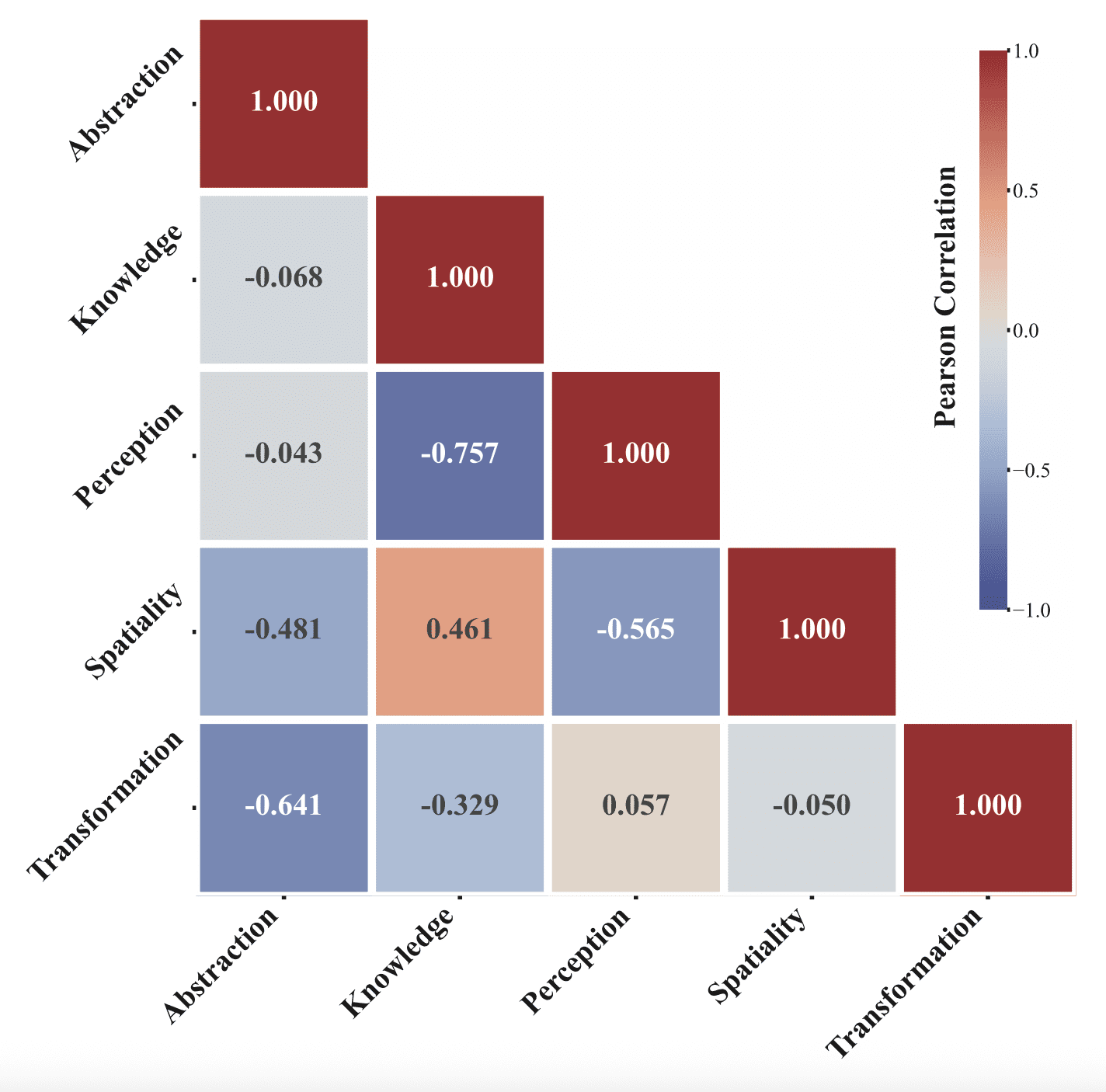
Interesting Patterns in Model Capabilities
The authors discovered a non-trivial structure in which cognitive capabilities tend to develop together. After removing the general “model strength” factor (stronger models score higher across the board), it turned out that Knowledge and Spatiality correlate strongly (ρ = 0.461). This connects to neuroscience. The brain has a hippocampus — a region responsible for spatial navigation. It contains two types of neurons: place cells, which fire when you are at a specific location, and grid cells, which create something like an internal coordinate map of the world. The Nobel Prize for their discovery was awarded in 2014. But the same hippocampus turns out to be necessary not just for navigation — patients with hippocampal damage are worse at acquiring abstract concepts and facts. In other words, spatial thinking and knowledge acquisition in the brain rely on the same structure. The authors found a similar pattern in video models: those that perform better on spatial tasks tend to perform better on knowledge tasks as well.
Knowledge and Perception, on the other hand, correlate negatively (ρ = −0.757): models that are good at “knowing facts” are worse at processing sensory information directly.
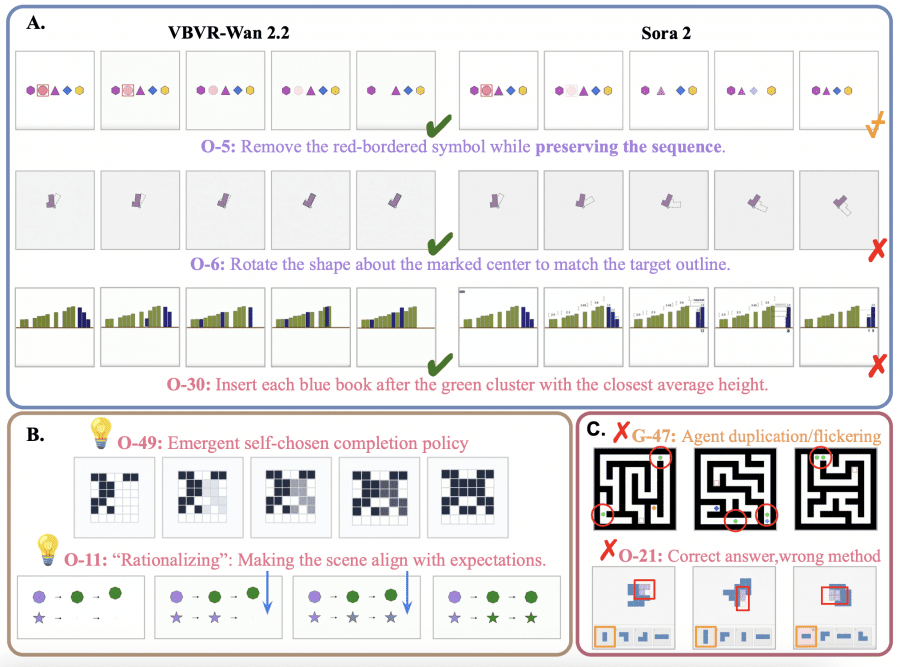
The Main Takeaway: Controllability Is the Foundation of Reasoning
After fine-tuning, VBVR-Wan2.2 learned to do “exactly what was asked” — delete a symbol without extra changes, rotate an object around the correct pivot rather than together with its bounding box. Sora 2 on the same tasks added unnecessary operations or lost control of the scene. This suggests that controllability — the ability to follow constraints precisely — is a prerequisite for verifiable reasoning, not an optional extra feature.
VBVR is not just a dataset, it is infrastructure: task generators can be extended, new task types can be added through a standardized template, and the benchmark will evolve alongside the field. All of this makes it a benchmark that will not become obsolete the moment it is published.






