
Google AI has introduced a set of neural networks and benchmarks for them, which allow robots to be trained to move one-, two-and three-dimensional deformable objects. The code opens up opportunities to increase the level of automation in production.
The difficulties that arise when manipulating a deformable object are the inability to fully set its configuration. For example, to describe the location of a rigid cube in three-dimensional space, it is enough to specify the position of a fixed point relative to its center, but in an object such as a fabric, the position of all its points changes relative to each other. Even if there is an accurate description of the state of the deformed object, the problem of reconstructing its dynamics remains. This makes it difficult to predict the future state of a deformable object after an action has already been applied to it, which is often important for multi-stage planning algorithms.
The article presents the open-source benchmark DeformableRavens, which includes 12 tasks related to the manipulation of one-dimensional (cables), two-dimensional (fabrics) and three-dimensional (bags) objects. In addition, the code contains a set of neural networks that allow manipulating the image of the object and the final goal. In particular, the models allow you to rearrange cables, smooth fabric, and put an object in a bag (Fig. 1). When performing tasks, the position of objects is set randomly to evaluate the effectiveness of neural networks in different conditions. Thus, the code makes it possible to train robots in complex spatial relationships between objects.
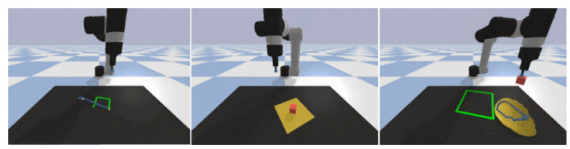
The neural networks presented in the code are developed on the basis of the previously presented models of Transporter Networks, which allow performing actions on solid objects. The modification of Transporter Networks for working with deformable objects was to add to the input data, in addition to the image of the current position of the object, a photo of the purpose of movement, that is, the desired final state of the object. Then the features are combined based on the element-by-element multiplication to determine the sequential actions that need to be performed on the object in order to transfer it from the initial state to the final one.
Google plans to improve the efficiency of neural networks by increasing the speed of calculating the sequence of actions of the robot, as well as adding the ability to modify these sequences in real time, so that the robot can immediately correct its mistakes.


