Researchers from Google Research, have proposed a new, state-of-the-art method for text generation. In their novel paper, “Encode, Tag, Realize: High-precision Text Editing”, they introduce a novel sequence-to-sequence model that overcomes several of the common shortcomings of existing models, including faster inference.
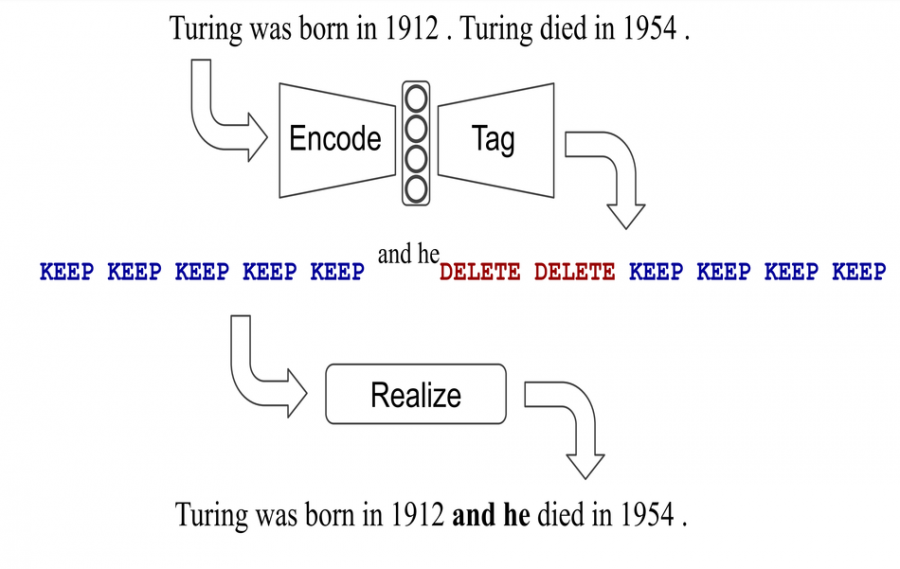
The new model was named LaserTagger and addresses challenges such as hallucination in text generation, slow inference and the requirement for large amounts of training data. It was designed to work in a slightly different manner, where instead of generating text from scratch, LaserTagger produces text as output by tagging words with some edit operations that are applied to the input during a “realization” step. According to researchers, in this way, the model will be more robust and much more precise.

There are four types of edit operations that LaserTagger predicts: Keep, Delete, Keep-AddX / Delete-AddX. So, instead of predicting text, the proposed method is predicting a sequence of these 4 edit operations that are applied to the input sequence. To achieve this, researchers combined BERT with an autoregressive Transformer decoder.
The method was evaluated on 4 text-related tasks: sentence fusion, sentence splitting, abstractive summarization, and grammar correction. Evaluations showed that it achieves state-of-the-art results on three of these tasks and performs comparably well with existing sequence-to-sequence models (seq2seq) trained with a large number of samples. However, LaserTagger achieves two times faster inference and outperforms these methods when the number of training samples is limited.
The implementation of the method was open-sourced and it’s available on Github. More about the method can be read in the paper or in the official blog post.


