MiniMax has open-sourced its latest MiniMax-01 series, introducing two models that push the boundaries of context length and attention mechanisms: MiniMax-Text-01 for language processing and MiniMax-VL-01 for visual-language tasks. The complete weights of both MiniMax-Text-01 and MiniMax-VL-01 models are available on Github.
Key technical breakthroughs include:
- Maintains consistent high performance (0.910-0.963) across context lengths up to 4M tokens
- Comprehensive optimization of MoE All-to-all communication and sequence handling
- Enhanced kernel implementation for linear attention during inference
- Integration with Mixture of Experts (MoE) architecture for improved efficiency
- Near-linear complexity scaling for processing extended inputs
Minimax-01 Architecture
The MiniMax-01 series represents a significant departure from traditional Transformer architectures by implementing a novel Lightning Attention mechanism at scale. At its core, the architecture features 456 billion total parameters with 45.9 billion parameters activated per inference. The system employs a hybrid attention structure, utilizing 7 Lightning Attention layers (linear attention) and 1 traditional SoftMax attention layer per 8-layer block.
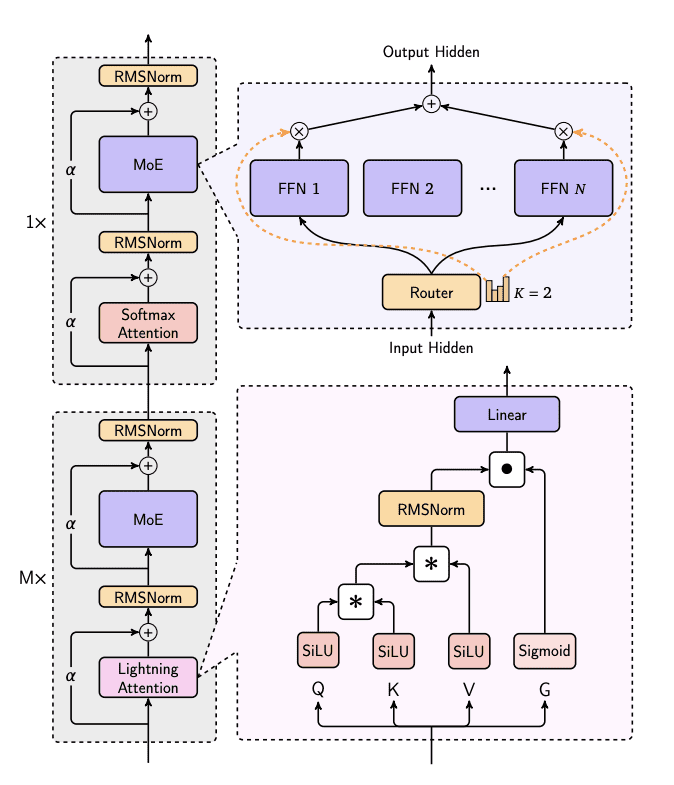
The MiniMax-Text-01 architecture employs a repeating block structure with two key components: attention layers and MoE (Mixture of Experts) processing. Each block integrates RMSNorm layers with residual connections (α), alternating between Lightning Attention and SoftMax Attention mechanisms. The Lightning Attention processes inputs through SiLU-activated Q/K/V transformations and a Sigmoid gate, while the MoE component uses a Router to distribute inputs across N Feed-Forward Networks with top-2 routing. This design enables efficient processing of long sequences while maintaining model performance through balanced attention and expert routing mechanisms.
Performance Benchmarks
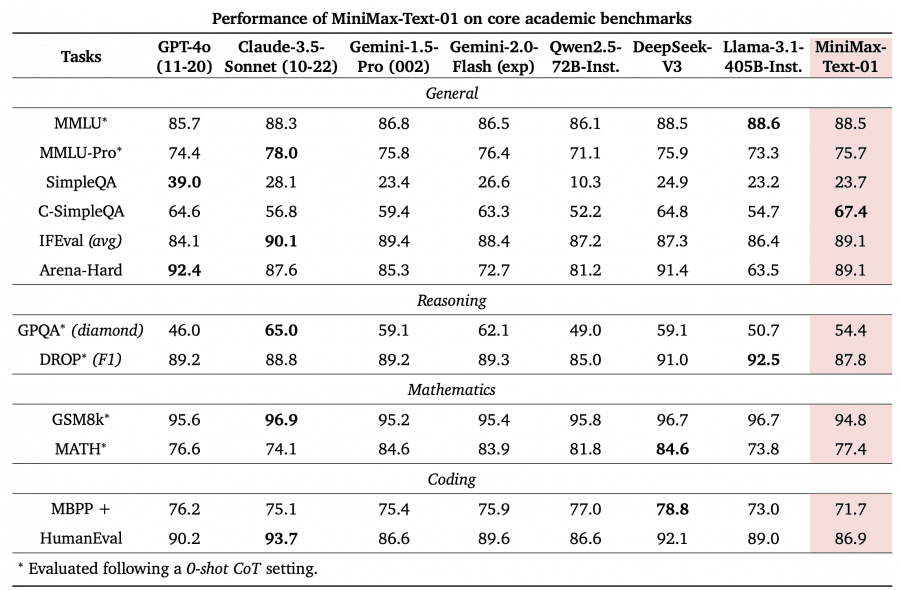
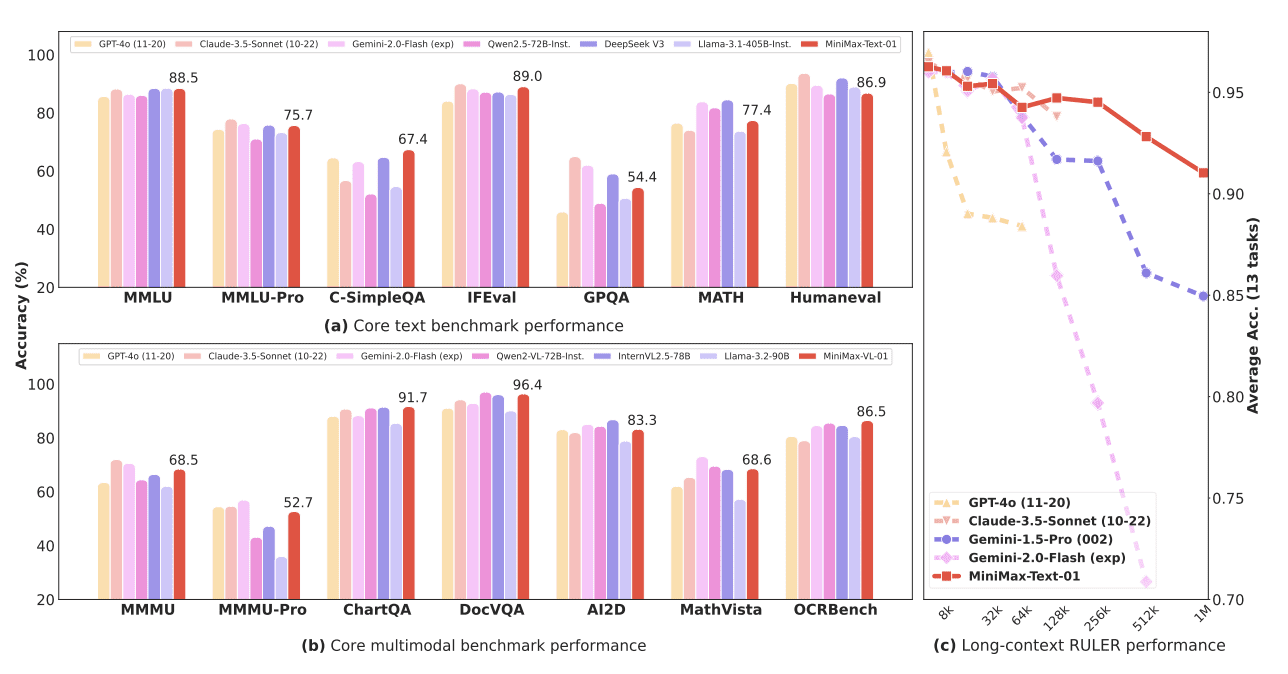
The model demonstrates exceptional capabilities across standard benchmarks, matching leading models in text and multi-modal understanding. Perhaps most notably, it achieves 100% accuracy in the 4-million-token Needle-In-A-Haystack retrieval task, while showing minimal performance degradation with increasing input length.
Minimax-01 Performance Across Context Lengths
The MiniMax-Text-01 demonstrates exceptional performance scaling across varying context lengths, particularly excelling in longer sequences. In Ruler benchmark tests, it maintains consistently high performance scores from 4k to 1M tokens:
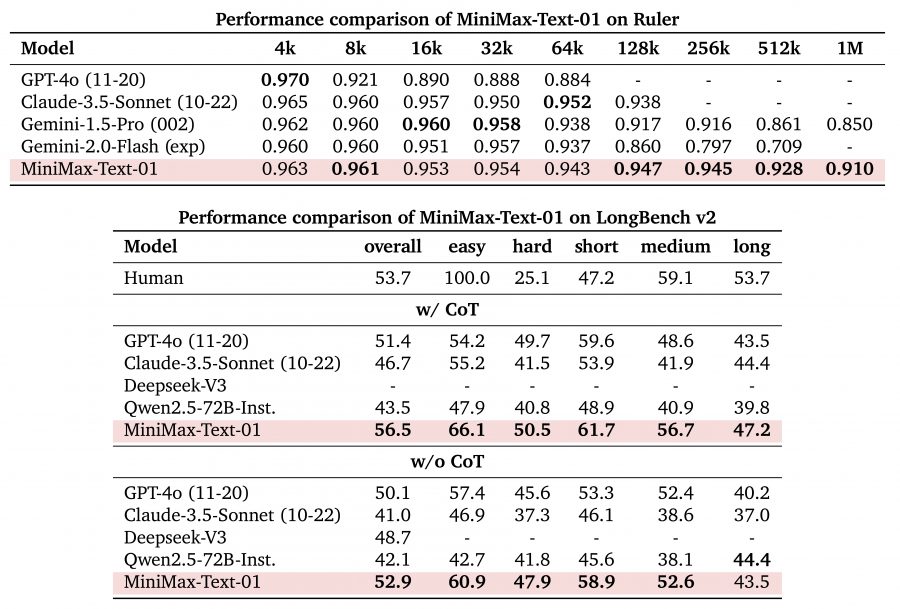
Short to medium contexts (4k-64k): Maintains scores above 0.94, matching or exceeding top models like GPT-4o and Claude-3.5-Sonnet
Extended contexts (128k-1M): Shows remarkable stability with scores between 0.947-0.910, significantly outperforming competitors like Gemini-2.0-Flash which drops to 0.709 at 512k
LongBench Performance
The model demonstrates superior capabilities on the LongBench v2 benchmark, both with and without Chain of Thought (CoT):
- Overall performance: Achieves 56.5 (w/ CoT) and 52.9 (w/o CoT), surpassing all compared models including GPT-4o
- Task-specific strengths: Particularly excels in ‘easy’ (66.1) and ‘short’ (61.7) categories with CoT
- Consistent performance: Maintains strong scores across all test categories, showing balanced capabilities across different task types
These benchmark results validate MiniMax-Text-01’s architecture design, particularly highlighting its ability to maintain high performance across increasingly longer context windows, a crucial advancement for practical AI applications.
Accessibility and Pricing
For developers and organizations looking to implement MiniMax-01, the following options are available:
- API access through the MiniMax Open Platform
- Competitive pricing structure: $0.2 per million input tokens
- Visual-language processing capabilities via MiniMax-VL-01
- Regular updates for both code and multi-modal features
The release of MiniMax-01 marks a crucial step forward in AI development, particularly for AI Agents where extended context handling is essential. The model’s architecture provides a robust foundation for managing complex, long-context interactions in both single-agent memory systems and multi-agent communication scenarios.




