
A group of researchers from Tencent AI Labs, has developed and open-sourced a new method for high-fidelity 3D model reconstruction of humans by using RGB-D selfie images.
The method works in a way that it takes selfie images taken from different direction as inputs from which it tries to render a full 3D scan of a human head. In fact, the system can be deployed on a smartphone and users can simply rotate their head while the phone is capturing a video, or a sequence of images of the person’s head. This video is fed into the system containing RGB-D information captured in a temporal manner.
From the input video, the first stage of the proposed method is basically filtering the frames and looking for high-quality frames which can be actually used for the reconstruction. The selection of “good” frames is also a two-stage process where in the first stage, a so-called “coarse screening” is applied, and the method uses landmark detection coupled with grouping in order to group the frames based on the pose. During the second stage, in the “frame selection” process these groups are assesed based on the data quality.
Using the few selected frames, an initial 3DMM model is fitted using the detected landmarks from the first stage. Then, to this result, a differentiable renderer is applied with multi-view constraints coming from the fact that images are RGB-D. The method regresses the 3DMM parameters along with lightning parameters and poses. The last step is creating high-resolution albedo and normal maps used for synthesizing the final 3D face model.
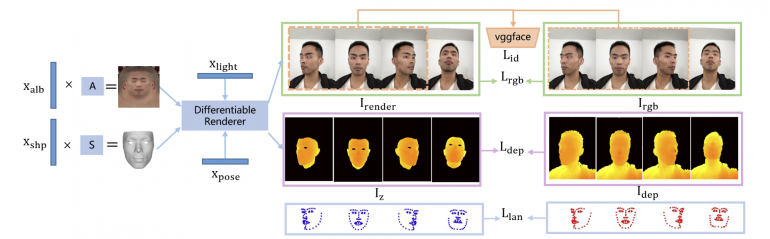
To train the proposed model, researchers collected a large dataset of more than 40 000 images. The photos were taken as selfies by 30 subject participants, all of them from Asia. Researchers conducted extensive experiments to quantitatively and qualitatively assess the reconstruction from the novel method. The conclusions were that the system is able to render high-fidelity and high-quality digital humans, and that the method is at consumer-level accuracy.
The implementation of the proposed method was open-sourced and it is available on Github. The paper was published on arxiv.


