
Researchers from Berkeley Artificial Intelligence Research (BAIR) have developed a method that allows robots to imitate human demonstrations by learning from videos.
The method, called AVID combines robotic reinforcement learning and generative adversarial networks to teach a robot how to perform a task directly from human demonstrations. Researchers from BAIR took an interesting approach where they train a GAN network to convert human demonstration into a video of a robot performing a task, and afterward a RL agent is trained using such videos.
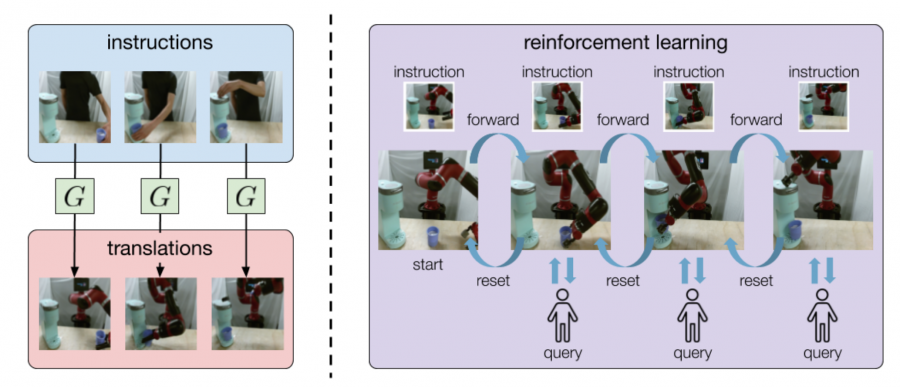
In their paper, named “AVID: Learning Multi-Stage Tasks via Pixel-Level Translation of Human Videos”, researchers describe their method which consists of two main stages: a translation stage and a learning stage. In the first one, a CycleGAN network is trained to perform frame-wise translation of a demonstration video into a new video where a robot (or robot hand, in particular) is performing the task. In the second stage, the robot attempts to perform the given task by automatically resetting and retrying until it has been signaled that the task is finished. The task completion confirmation is provided by a human via a keypress, therefore the robot is learning and performing the task until the instruction classifier signals success.
Researchers regard the proposed approach as “automated visual instruction-following with demonstrations”. In their settings, reinforcement learning is applied with the support of instruction images, obtained by the translation of the demonstration. According to them, the method is capable of learning complex tasks requiring only 20 minutes of human demonstrations and about 180 minutes of robot learning by interaction with the environment.
The method was evaluated and compared to existing methods in terms of two pre-defined tasks: operating a coffee machine and cup retrieval. The evaluations showed that the method outperforms all other methods that use human demonstrations.
More details about the proposed method can be read in the paper published on arxiv or at BAIR’s official blog post.





