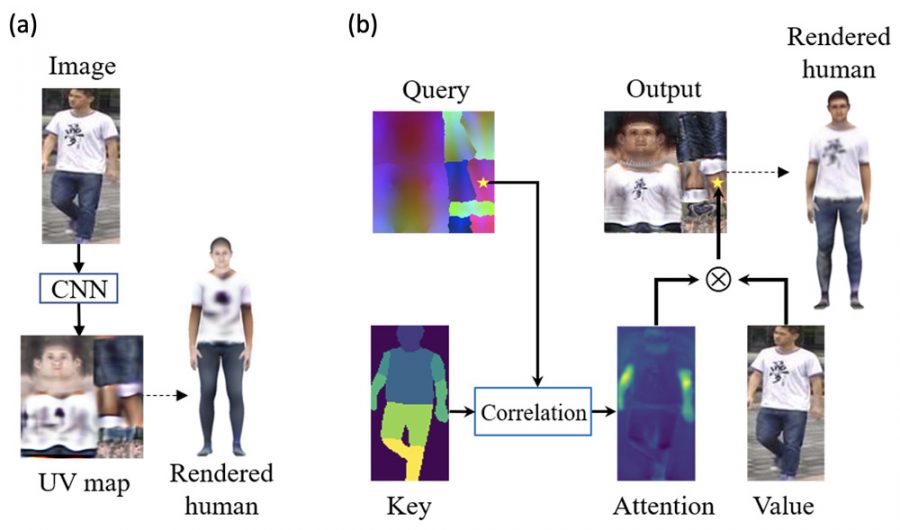
Texformer is a framework for evaluating 3D poses from a single image using a transformer architecture. Texformer’s pose recovery accuracy is higher than that of state-of-the-art models based on convolutional neural networks.
The architecture of the model is shown in the figure below. The attention module consists of three elements:
- The request is a color map calculated in advance, obtained by projecting the coordinates of a standard three-dimensional human surface onto UV space.
- the value is the input image and its two-dimensional coordinates;
- the key is the input image and a two-dimensional segmentation map.
The query, value and key are entered into three convolutional neural networks for transformation in the feature space. Then these features are fed into a transformer to generate output features, which are processed in another convolutional neural network that generates an RGB UV map, texture and mask. The final output UV map is obtained by superimposing an RGB map and texture using a mask.


