
In the Android app, you can play a card game with a neural network. An iterative approach to training, in which the neural network plays against its own replica, trained at the previous stage, has significantly increased its performance.
Grünober Suchen (“Queen of Spades”) is an 8-trick card game designed for 4 players and played with a deck of 32 cards. Each player receives 8 cards. The first player tricks by placing the card face up on the table. The other players take turns laying out the 1st card. If possible, they must follow the suit of the first card, if not – they can play any card. The round is won by the player who plays the ace of the card corresponding to the first card. The player who wins all the tricks gets +3 points, all the others get -1 point. If a player lays out the Queen of Spades and wins in the last trick, he gets -3 points, and everyone else gets +1 point. Otherwise, the player who laid out the queen of spades gets -1 point; the player who won in the last trick gets -1 point, and the other two players get +1 point each.
The peculiarity of a neural network is that it learns independently, without human participation. At first, without having a trained model, the simulated players choose cards randomly, from the options allowed by the rules. To make the game fair, each player only knows his own cards, but can count the cards that are dropped. The output data is the rating of each of the cards that can be matched, calculated based on the available input data before each turn. After training, the model understands which card is most likely to lead to a win.
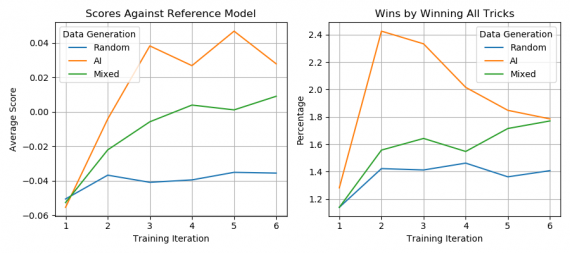
The most effective training strategy turned out to be iterative, in which the neural network moves not against players who lay out random cards, but against its own replica, trained at the previous stage (Fig. 1). In addition, the complexity of the game can be controlled by reducing the number of opponent cards tracked by the neural network and introducing artificial noise in the neural network actions.
The Android app is available here.


