The improved neural network training strategy has allowed IBM to significantly increase the efficiency of the speech-to-text tool. The service works with eight languages and provides a record high speed of telephone calls processing.
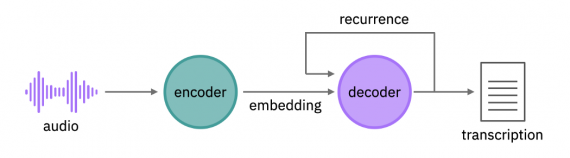
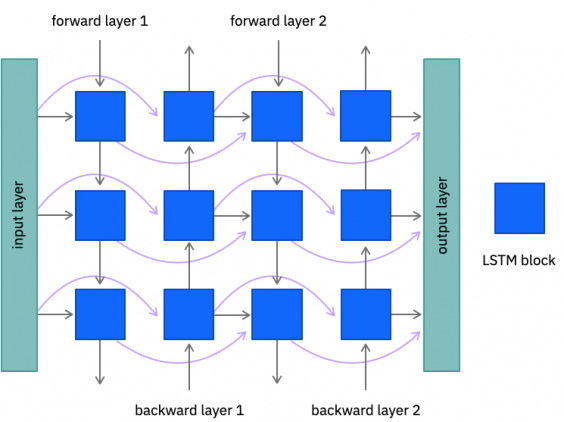
The model consists of an encoder and a decoder (Fig. 1). The encoder performs an acoustic embedding, that is, it generates a multidimensional representation of sound that can be used for classification tasks. A recurrent neural network extract features from an audio signal at various levels of abstraction. Neural networks are bidirectional, which allows us to better predict the correct transcription. It works as follows: the app “listens” to the audio recording twice, and the second time it listens, it can more accurately recognize the spoken words. The decoder then makes a prediction for each character based on the audio embedding and the previously recognized characters. Thus, the model predicts a word based on its sound and neighboring words.
The app works with a speech in eight languages, with a low latency mode available for six of them, which allows Watson Speech to Text to work as a part of a phone assistant. In this mode, speech recognition in English has become 19% more accurate compared to the previous generation engine, and for other languages, the recognition quality has increased up to 57%. Moreover, the model can recognize words that were not used in training, automatically format numbers and dates, replace obscene speech, and remove confidential data from the transcript.
In addition to telephone assistants, the IBM tool can be used for the automatic processing of customer calls, namely, identifying patterns or statistical analysis of the reasons for calls, and transcribing the conversation in real-time, which will allow the operator to quickly offer relevant information. The Watson Speech to Text service is available in the IBM Cloud.








