A group of researchers from the Harbin Institute of Technology, the University of Adelaide and the Hafei University of Technology, has proposed a novel state-of-the-art method in scene text recognition based on the transformer.
In recent years, Transformers are a type of networks that have been gaining popularity. They have proven to be very successful, especially in Natural Language Processing (NLP) tasks, and many state-of-the-art methods rely on Transformer models or similar architectures.
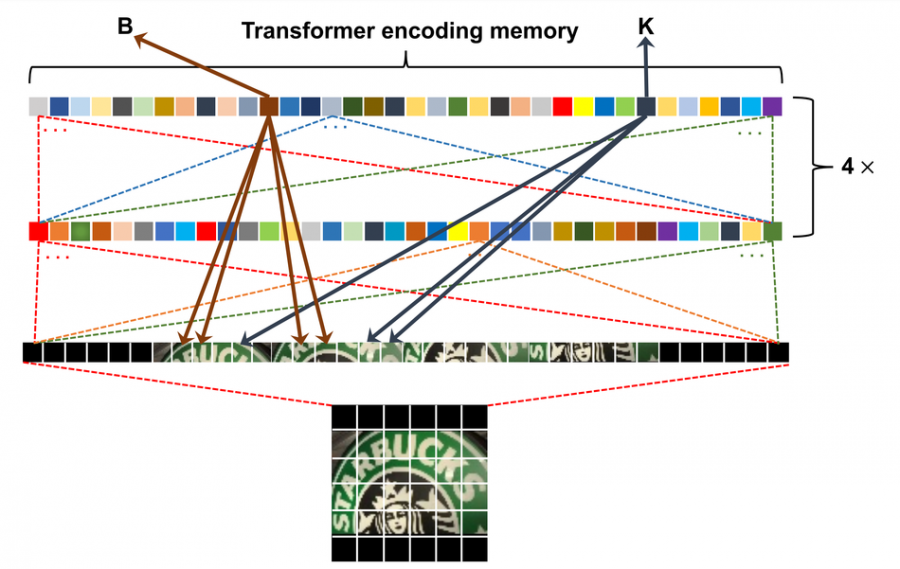
In their new paper, “Scene Text Recognition via Transformer”, researchers use Transformer to solve the problem of optical character recognition (OCR) and Scene Text Recognition. The proposed method decouples the problem into two sub-problems and consequently, it has two modules that solve these sub-problems: a feature extraction module and a transformer module. Convolutional feature maps as word embeddings are used as input to the transformer, and in this way, the method leverages the potential of the powerful attention mechanism of transformers.
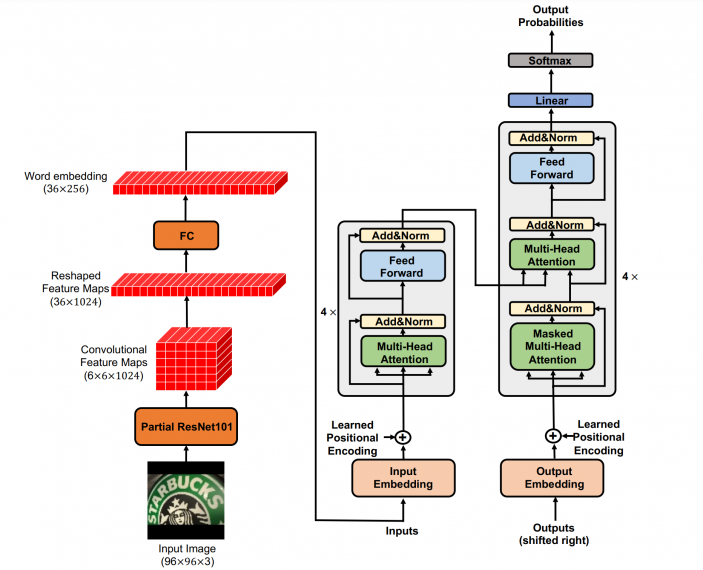
Researchers conducted extensive experiments on 5 datasets: IIIT5K-Words, Street View Text, ICDAR 2015, SVT-Perspective and CUTE80. According to them, the method outperforms existing methods and it outperforms the current state-of-the-art method on the CUTE benchmark dataset by more than 10%.
The implementation of the method was open-sourced and is available here. More in detail about the Transformer OCR model can be read in the pre-print paper.


