Researchers from Shanghai University of Engineering Science and Peking University presented 3D-R1 — a new foundation model that significantly improves reasoning capabilities in three-dimensional vision-language models (VLM). The model demonstrates an average performance improvement of 10% across various 3D benchmarks, confirming its effectiveness in understanding and analyzing three-dimensional scenes. The model’s code is available on Github, and the dataset is published on HuggingFace.
Architecture and Approach
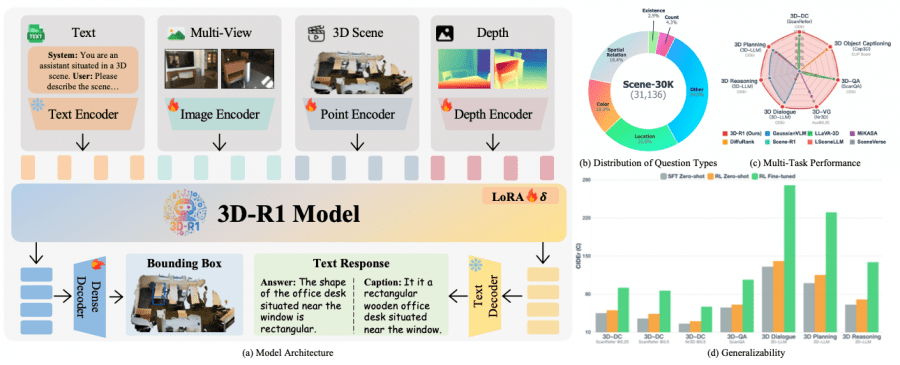
3D-R1 uses a two-stage training approach. In the first stage, a high-quality synthetic dataset Scene-30K with Chain-of-Thought reasoning is created, which serves as cold-start initialization for the model. The dataset contains 30,000 complex reasoning examples generated using Gemini 2.5 Pro based on existing 3D-VL datasets.
A key architectural feature is unified encoding that combines:
- Text encoder for natural language processing;
- Multi-view image encoder based on SigLIP-2 for image analysis;
- Point cloud encoder based on Point Transformer v3 for working with 3D data;
- Depth encoder using Depth-Anything v2 for depth understanding.
Reinforcement Learning through GRPO
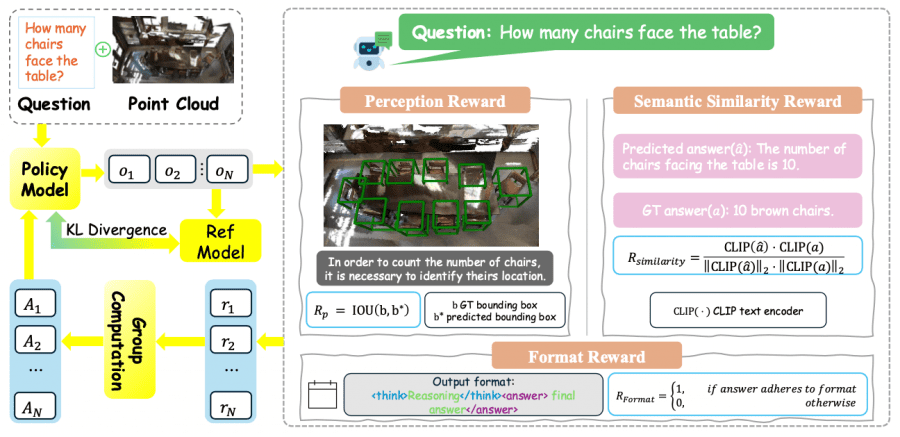
In the second stage, 3D-R1 applies Group Relative Policy Optimization (GRPO) to improve reasoning capabilities. The model uses three reward functions:
Format reward, controls the structural correctness of output data, checking compliance with the format <think>reasoning</think> <answer>final answer</answer>.
Perception reward, focuses on spatial perception accuracy, evaluating the intersection of predicted and ground truth bounding boxes through IoU metric.
Semantic similarity reward, uses pre-trained text CLIP encoder to evaluate semantic correspondence between predicted and true answers through cosine similarity.
Dynamic View Selection
3D-R1 uses an innovative dynamic view selection strategy that automatically selects the most informative 2D viewpoints from a 3D scene. The algorithm uses three complementary evaluation functions:
- Text-to-3D score evaluates viewpoint relevance to textual context;
- Image-to-3D score analyzes spatial information coverage;
- CLIP score provides cross-modal alignment.
Adaptive weighting of these components allows the model to dynamically select optimal viewpoints for each specific scenario.
Experimental Results

Experiments on seven key 3D benchmarks demonstrate significant improvements. On the three-dimensional dense captioning task, 3D-R1 achieves 91.85 CIDEr@0.25 on ScanRefer, surpassing the previous best result by 6.43 points. On question answering tasks, the model shows 106.45 CIDEr on the ScanQA validation set.
Particularly impressive are the results on three-dimensional object localization tasks, where 3D-R1 achieves 68.80 Acc@0.25 on Nr3D and 65.85 Acc@0.25 on ScanRefer. On three-dimensional reasoning tasks, the model demonstrates 138.67 CIDEr on SQA3D, significantly surpassing existing methods.
Component Synergy
Detailed component analysis confirms the importance of each model element. Reinforcement learning with three reward functions increases ScanQA CIDEr performance from 97.95 to 106.45. Dynamic view selection shows advantages over fixed strategies, improving CLIP R@1 from 30.18 to 32.23 on three-dimensional object captioning tasks.
Incremental addition of modalities demonstrates the contribution of each component: text and images create basic functionality, the depth encoder adds geometric understanding, and the point cloud encoder is critically important for complex spatial reasoning.
Practical Applications
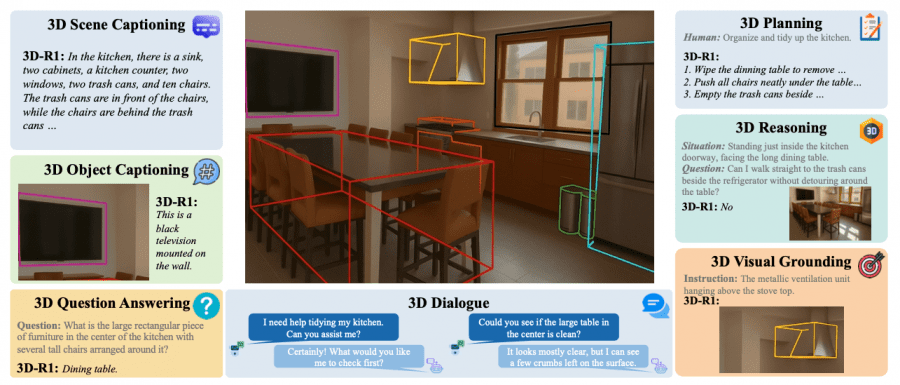
3D-R1 supports a wide range of three-dimensional scene understanding tasks: from basic object description to complex dialogue and action planning. The model can generate detailed scene descriptions, answer spatial questions, localize objects based on textual descriptions, and even plan action sequences for space reorganization.
The model demonstrates particularly strong results on tasks requiring understanding of spatial relationships and multi-step reasoning. This makes 3D-R1 a promising solution for applications in robotics and augmented reality.
Conclusion
3D-R1 represents a significant step forward in the development of three-dimensional vision-language models, combining structured training with reasoning chains, reinforcement learning with multiple reward functions, and adaptive perception strategies. A comprehensive approach to optimizing architecture, data, algorithms, and inference methods opens new possibilities for creating accessible and efficient artificial intelligence in the field of three-dimensional scene understanding.