
Researchers from ByteDance and POSTECH introduced TA-TiTok (Text-Aware Transformer-based 1-Dimensional Tokenizer), a novel approach to making text-to-image AI models more accessible and efficient. Their work demonstrates through MaskGen models how high-quality text-to-image generation can be achieved using only public data, challenging the assumption that private datasets are necessary for state-of-the-art performance. Model code and weights are published on Github.
TA-TiTok Technical Details
TA-TiTok is the tokenizer – it handles converting images into compact token representations. Its main purpose is to efficiently transform images into sequences of tokens that can be processed by generative models. The paper demonstrates it offers three key improvements over previous tokenizers: one-stage training, support for both discrete and continuous tokens, and text-aware processing during de-tokenization.
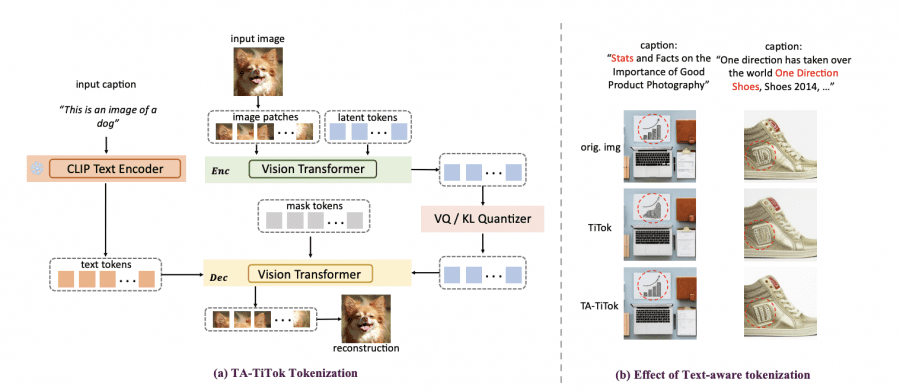
The research team introduced three fundamental enhancements to the original TiTok framework:
- Streamlined Training Process. The system replaces traditional two-stage training with an efficient single-stage procedure, significantly reducing computational overhead while maintaining model quality.
- Dual Token Support TA-TiTok implements both discrete (VQ) and continuous (KL) token formats:
- Vector Quantized (VQ) variant enables direct mapping to codebook entries
- Key-Loss (KL) variant allows for continuous latent space representation This flexibility allows the system to optimize for different use cases and performance requirements.
- Text-Aware Processing By integrating CLIP’s text encoder during the de-tokenization phase, TA-TiTok achieves improved semantic alignment between generated images and text descriptions. This integration enables more accurate text-to-image correspondence.
MaskGen Model
MaskGen is the generative model that uses TA-TiTok’s tokenization to actually perform text-to-image generation. It takes the tokens produced by TA-TiTok along with text input and creates new images. MaskGen comes in different sizes (MaskGen-L at 568M parameters and MaskGen-XL at 1.1B parameters) and can work with both discrete and continuous tokens from TA-TiTok.
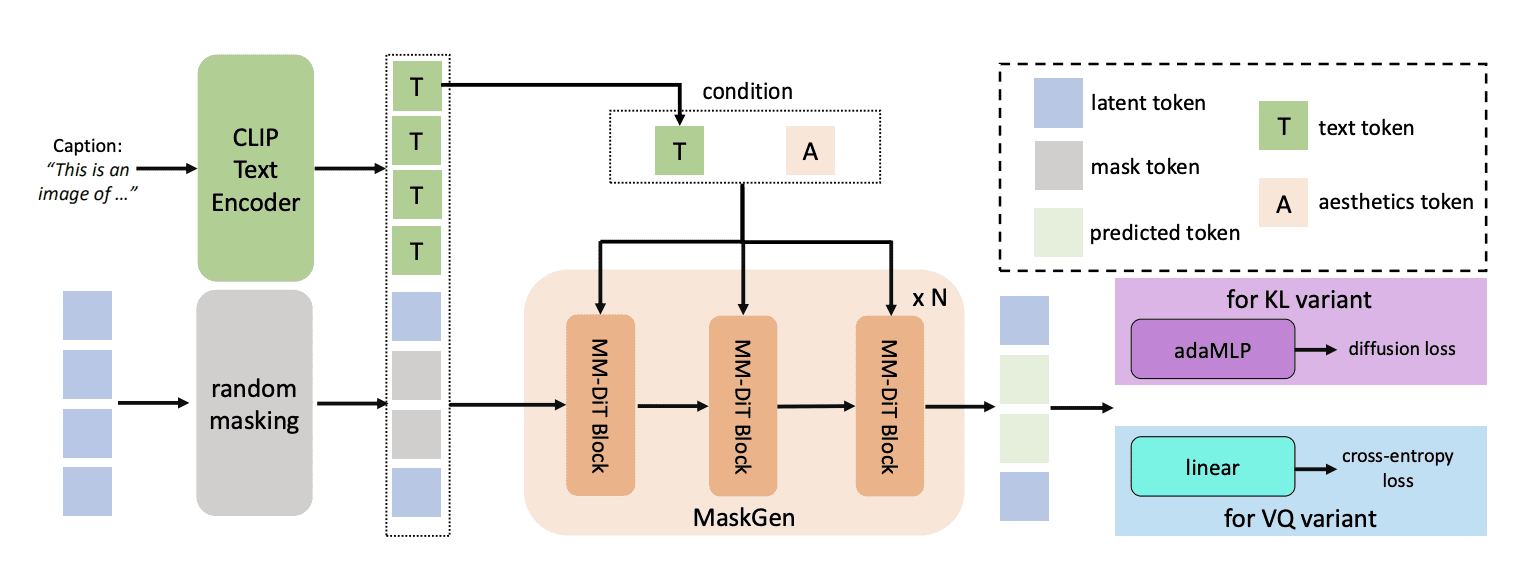
Open Data Implementation
The system is trained exclusively on publicly available datasets: DataComp, CC12M, LAION-aesthetic, JourneyDB, DALLE3-1M.
The researchers applied specific filtering criteria to ensure data quality, including resolution requirements and aesthetic score thresholds.
Quantifiable Performance
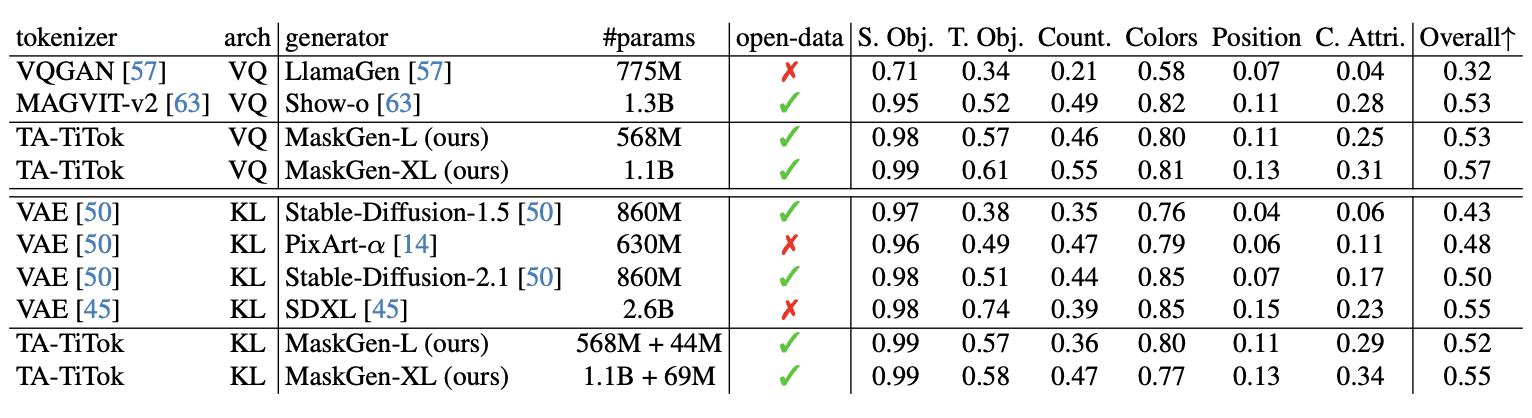
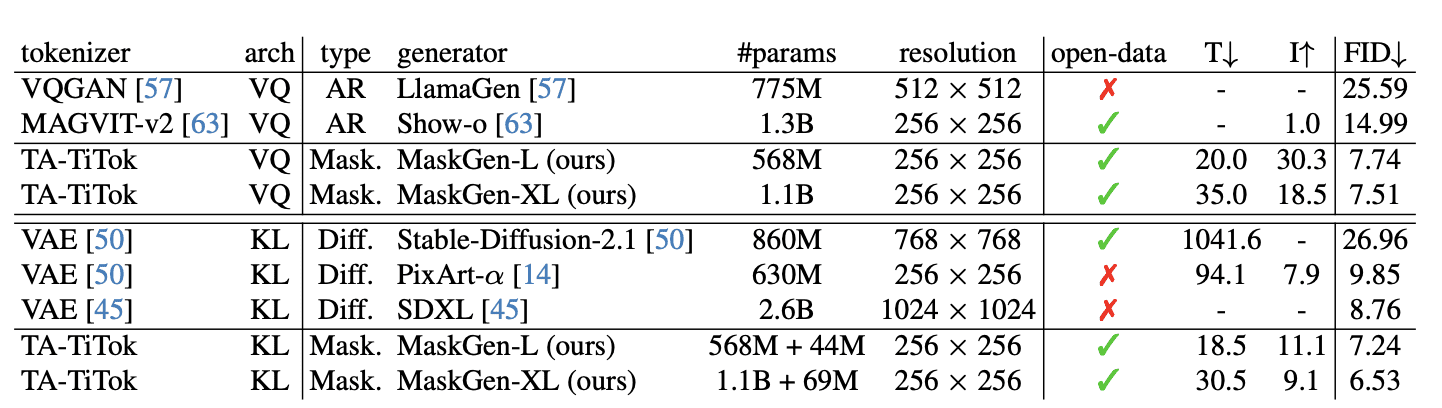
The researchers provide specific performance metrics:
- MaskGen-L (568M parameters) achieves a FID score of 7.74 on MJHQ-30K, outperforming Show-o (14.99) while offering 30.3x faster inference
- The system requires only 2% of the training time compared to SD-2.1 while achieving better performance
- MaskGen-XL (1.1B parameters) achieves FID scores of 7.51 and 6.53 on MJHQ-30K using discrete and continuous tokens respectively
Computing Requirements
The paper specifies exact computational needs:
- Training times: 20.0 8-A100 days for MaskGen-L and 35.0 8-A100 days for MaskGen-XL (Table 5)
- Batch sizes: 4096 for discrete tokens and 2048 for continuous tokens (Table 8, p.10)
- Learning rates and optimization parameters are fully detailed for reproduction
The researchers commit to releasing both training code and model weights to promote broader access to text-to-image technology (p.9). This represents one of the first open-weight, open-data masked generative models achieving performance comparable to state-of-the-art systems.








