Chain-of-Experts (CoE) – a novel approach fundamentally changing how sparse language models process information, delivering better performance with significantly less memory. This breakthrough addresses key limitations in current Mixture-of-Experts (MoE) architectures while creating new pathways for efficient AI scaling. Applying CoE to the DeepSeekV2-Lite architecture allowed achieving the same performance with fewer parameters leading to memory savings of up to 42%, or improving performance with the same parameter count by reducing validation loss from 1.20 to 1.12. The code has been open-sourced and is available on Github.
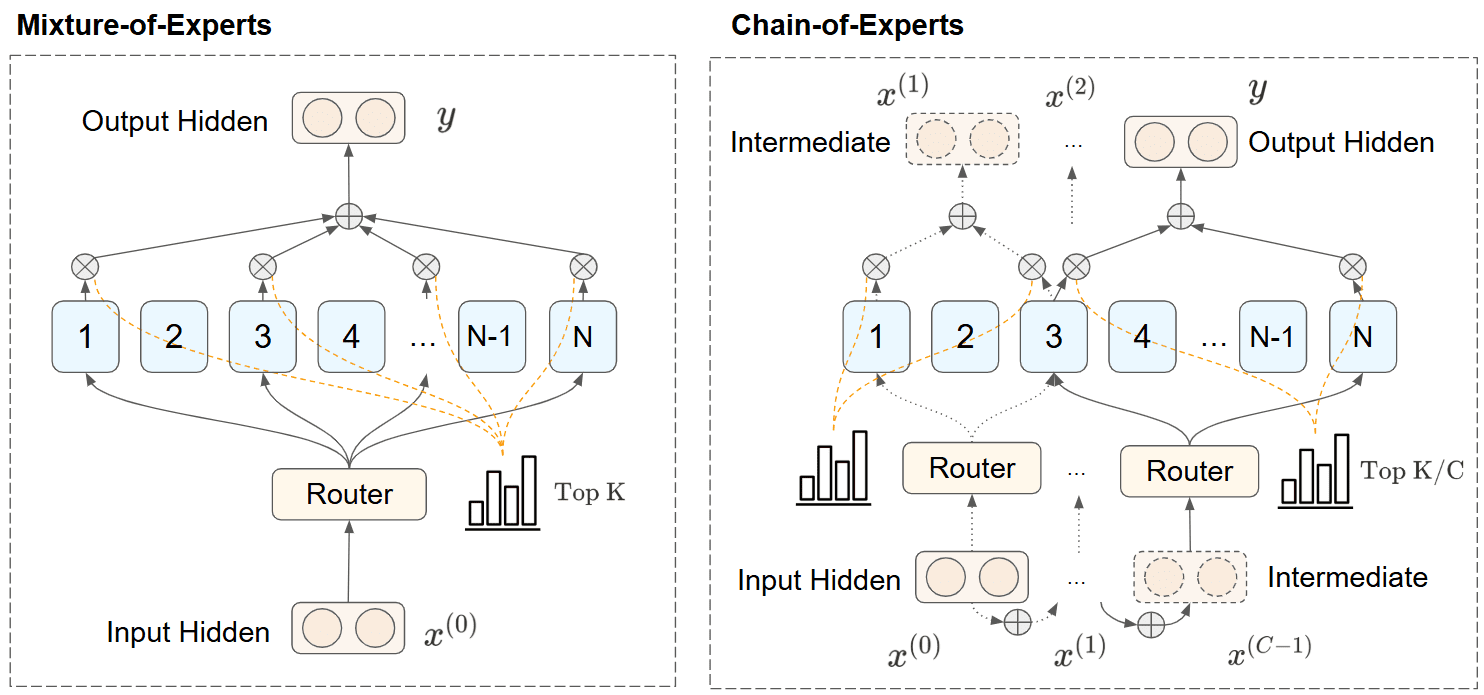
Traditional MoE models have struggled with two critical limitations – experts process information independently with minimal communication, and the sparse activation patterns demand substantial GPU resources. CoE introduces a solution that addresses both issues through sequential expert processing.
Key Achievements
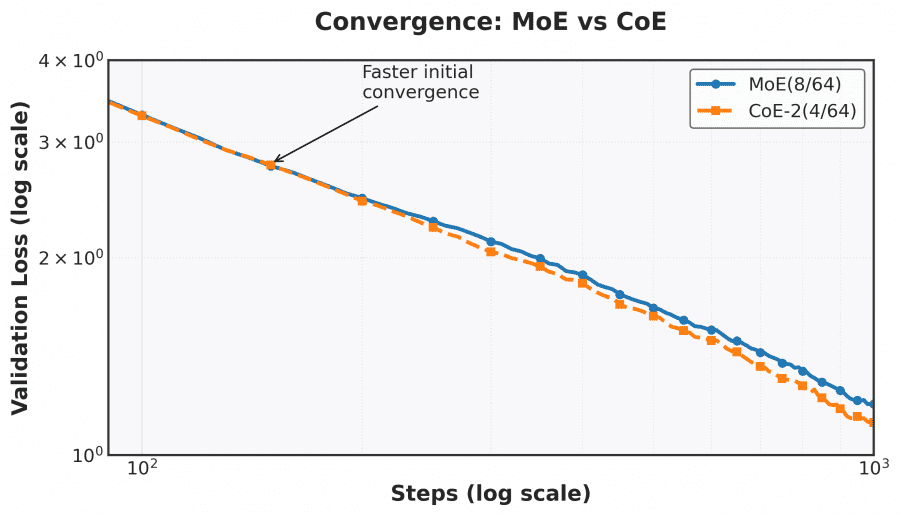
- Performance gains: 2× iterations reduces Math validation loss from 1.20 to 1.12
- Memory efficiency: 17.6-42% lower memory requirements with equivalent performance
- Scaling superiority: CoE outperforms both layer scaling and expert selection count expansion
- Combinatorial explosion: 823× increase in possible expert combinations
How it works
CoE implements an iterative mechanism where experts process tokens on outputs from other experts:
- Instead of parallel processing, experts work sequentially, forming dependencies between experts
- Each iteration’s expert selection is determined by the output of the previous iteration
- Information accumulates during iterations, achieving explicit expert communication
The formal representation can be described as:
x(0)=xx^{(0)} = x x(t)=∑i=1Ngt,i⋅Ei(x(t−1))+Ir⋅x(t−1),t=1,2,...,Cx^{(t)} = sum_{i=1}^{N} g_{t,i} cdot text{E}_i(x^{(t-1)}) + mathbb{I}_r cdot x^{(t-1)}, quad t = 1, 2, ..., C y=x(C)y = x^{(C)}
Experiments reveal that independent gating mechanisms and inner residual connections are critical for CoE’s success. The independent gating allows experts to process different types of information at different stages, while inner residuals effectively increase model depth.