The Mistral AI team has unveiled the remarkable Mistral 7B – an open-source language model with a staggering 7.3 billion parameters, surpassing the significantly larger Llama 2 13B model in all benchmarks. Notably, Mistral 7B achieves comparable results to Code Llama 2 in code generation and correction tasks, even though it wasn’t specifically fine-tuned for these tasks. This impressive feat is attributed to the grouped-query attention mechanism and the sliding window attention during training on long sequences.
Furthermore, let’s delve into the details of this model.
More About the Model
Noteworthy Features of Mistral 7B
- Mistral 7B is distributed under the Apache 2.0 license, allowing unrestricted use and easy fine-tuning for specific tasks. You can run it locally, deploy it on cloud platforms like AWS, GCP, Azure, or utilize it on HuggingFace.
- No censorship here! Mistral 7B is ready to answer all questions and engage in discussions on any topic. There are no security policies or restrictions on responsible usage.
Flash Attention
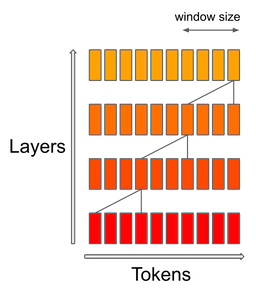
Mistral 7B employs a mechanism called Sliding Window Attention (SWA), where each layer references the previous 4,096 hidden states. The key improvement lies in its linear computational complexity of O(sliding_window.seq_len). In practice, the changes introduced in FlashAttention and xFormers provide a 2x speed boost for sequence lengths of 16k with a 4k window.
The Sliding Window Attention mechanism uses transformer layers to reference past states beyond the window size. Token i on layer k references tokens [i-sliding_window, i] on layer k-1. These tokens, in turn, reference tokens [i-2*sliding_window, i]. The upper layers have access to information further back in the past than implied by the attention structure.
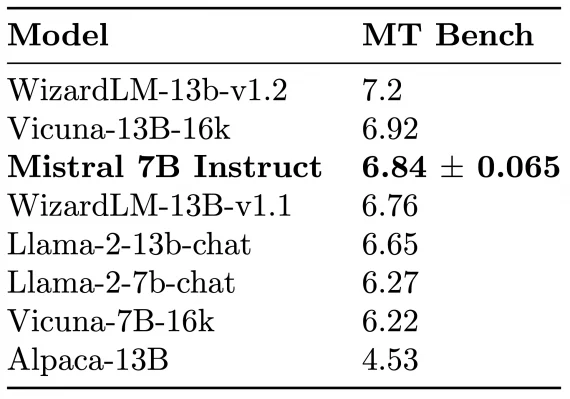
To showcase the fine-tuning capabilities, the team fine-tuned Mistral 7B Chat, and it surpassed Llama 2 13B Chat and Alpaca 13B in the MT-Bench test:
How to Use the Model
Developers have three options for utilizing Mistral 7B:
- Download the model and run inference code locally;
- Deploy the model on cloud services – AWS, Microsoft Azure, Google Cloud using skypilot;
- Access it on HuggingFace.
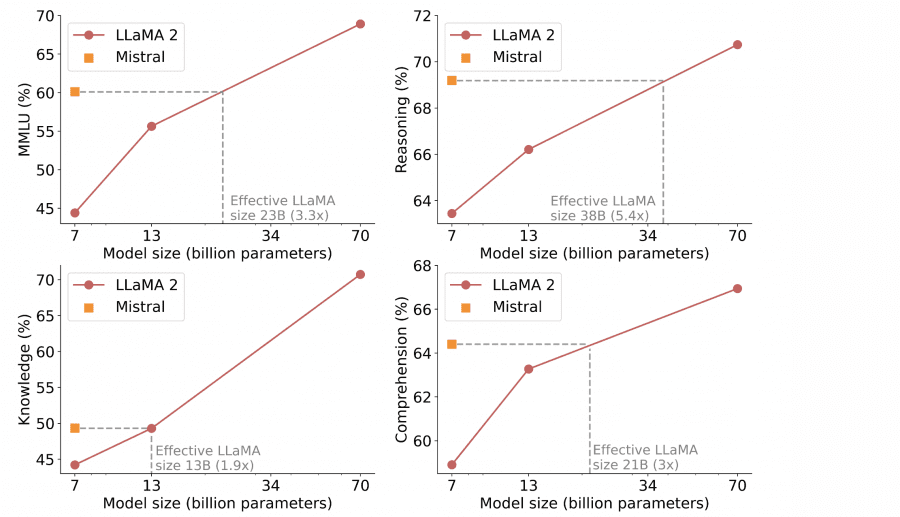
Mistral 7B Results
The performance of the Mistral 7B model and various Llama models was assessed across benchmark groups:
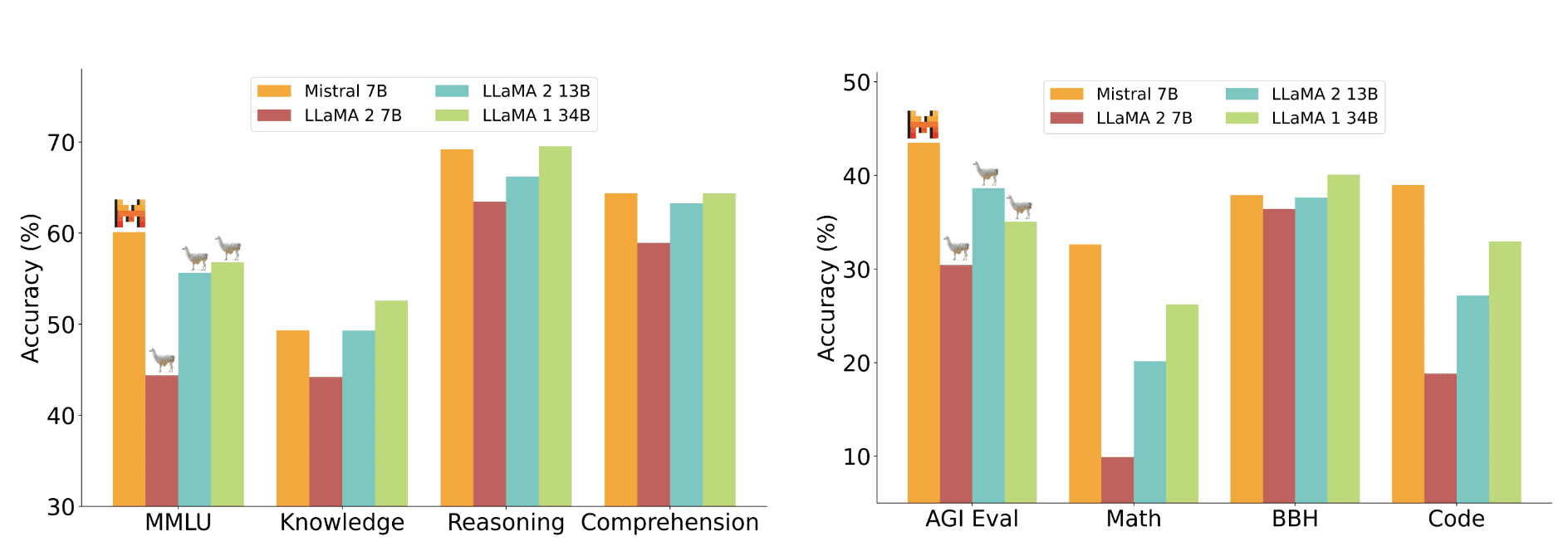
Mistral 7B significantly outperforms Llama 2 13B in all metrics and is on par with Llama 34B (since Llama 2 34B was not publicly released, it was compared to Llama 34B).
The table presents results for each benchmark individually:












