Researchers from Beijing University present FLM-101B, an open-source large language model (LLM) with 101 billion parameters trained from scratch with a budget of only $100K. Training LLMs at large scales like 100B+ parameters usually requires massive computational resources, making it inaccessible for many researchers. FLM-101B demonstrates the feasibility of training 100B+ LLMs at a fraction of typical costs through a novel growth strategy. This has the potential to accelerate research progress in this domain. The model code is available on HuggingFace.
FLM-101B was trained on a cluster of 24 DGX-A800 GPU (8×80G) servers. The authors leverage techniques like loss prediction across scales, mixed precision with bfloat16, and improvements over their prior work FreeLM. This enables stable training even at the 100B scale.
Model Architecture and Training Data
FLM-101B is based on the decoder-only GPT architecture, which has shown strong performance on language tasks. It incorporates two key modifications – the FreeLM objectives (language modeling + teacher objectives) and extrapolatable position embeddings (xPos) for better long sequence modeling. The hidden state size is 10,240, number of layers is 80, context window is 2,048, and number of attention heads is 80. AdamW is used with linear LR decay, weight decay, gradient clipping, and other optimized settings.
Following the growth strategy, the model was trained sequentially at 16B, 51B and finally 101B parameters. Training the model using the new approach took 21 days, which is 72% faster compared to training a 101B model from scratch (76 days).
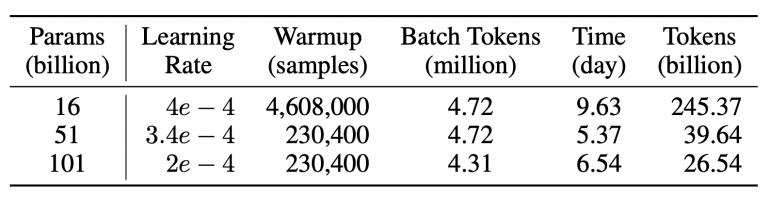
Each size inherits knowledge from the previous. The model was pre-trained on a mix of English (53.5%) and Chinese (46.5%) textual data. Additionally, some instructional data was used to improve comprehension skills. The two FreeLM objectives are unified into a single causal language modeling objective using special tokens. This improves training stability at scale.
Proposed Approach
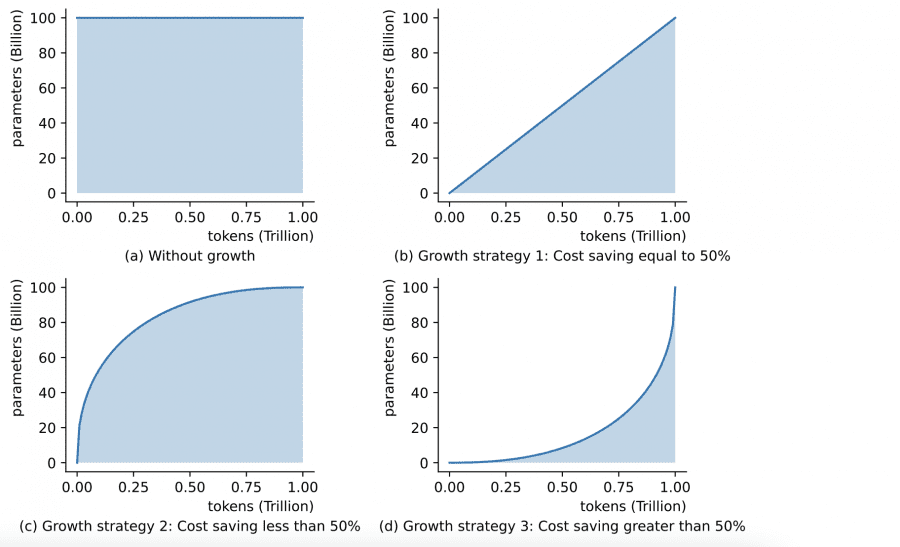
The key idea is to start from a small model and grow it progressively to larger sizes during training. Specific techniques used include function-preserving growth for stability and knowledge inheritance, as well as cost-effective schedules to maximize data usage.
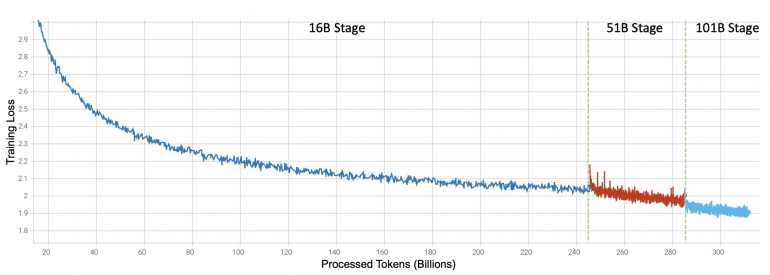
Here are some key ways the researchers address the computation challenges in training large language models like FLM-101B:
- Growth Strategy: As discussed earlier, the growth strategy significantly reduces training costs by starting from a smaller model and progressively growing it. This avoids training the full 100B model from scratch.
- Efficient Parallelism: The authors use a combination of data, tensor, and pipeline model parallelism strategies to maximize throughput on their multi-GPU cluster. This enables efficient scaling.
- Mixed Precision: Mixed precision training with bfloat16 reduces memory usage and training time compared to regular float32. This further improves efficiency.
- Loss Prediction: By predicting training loss across different scales, the authors find optimal hyperparameters for stability. This saves enormous trial-and-error costs.
- Checkpoint Activation: Activating only parts of the model during training lowers activation costs. The authors use this to estimate the computational expenses of baseline models.
The techniques presented could potentially benefit the broader research community.
FLM-101B Results
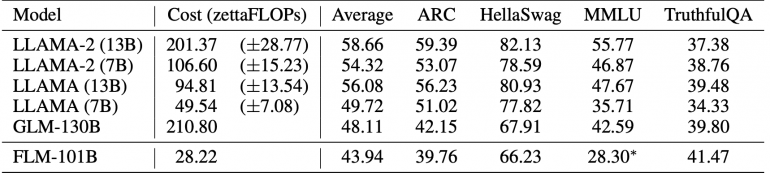
Despite the low training cost, FLM-101B achieves competitive results compared to models like GPT-3, LLAMA 2 and GLM-130B on mainstream knowledge-based benchmarks. The additional IQ-test inspired evaluations also showcase FLM-101B’s reasoning skills.
Knowledge Benchmarks:
- On OpenAI’s TruthfulQA, FLM-101B achieves the best accuracy of 41.47% among baselines, outperforming GLM-130B by 2 points. This evaluates factual knowledge.
- For ARC and HellaSwag which test commonsense reasoning, FLM-101B is comparable to GLM-130B despite using much less English data. The authors expect further improvements with more data.
- On professional knowledge benchmarks like SuperGLUE and MMLU, FLM-101B lags behind models that use in-domain training data. But a knowledge-enhanced version achieves new SOTA.
IQ-Test Inspired Benchmarks:
- On symbolic mapping tests like SuperGLUE-IQ and CLUE-IQ, FLM-101B achieves close to SOTA results compared to GPT-3 and GLM-130B.
- For rule understanding, the proposed model outperforms GLM-130B significantly in counting and string replacement.
- On pattern mining tests, FLM-101B surpasses GLM-130B by 11% on average and is comparable to GPT-3.
- In anti-interference tests, FLM-101B demonstrates strong robustness, ranking 2nd behind GPT-3.
In summary, FLM-101B shows highly competitive performance relative to its training cost on both mainstream and IQ-test inspired benchmarks. The results validate the effectiveness of the proposed training methodology.






