
Würstchen is an open text-to-image model that generates images faster than diffusion models like Stable Diffusion while consuming significantly less memory, achieving comparable results. The approach is based on a pipeline of three models: a text-conditional diffusion model, an image encoder/decoder, and VQGAN. Model training costs have been reduced by 16 times compared to Stable Diffusion 1.4. This achievement was made possible by adding a compression stage, reducing 512×512 images by 42 times to a resolution of 12×12. You can try the model demo on Huggingface, and the open-source code is available on Github.
More About the Method
The method consists of three stages:
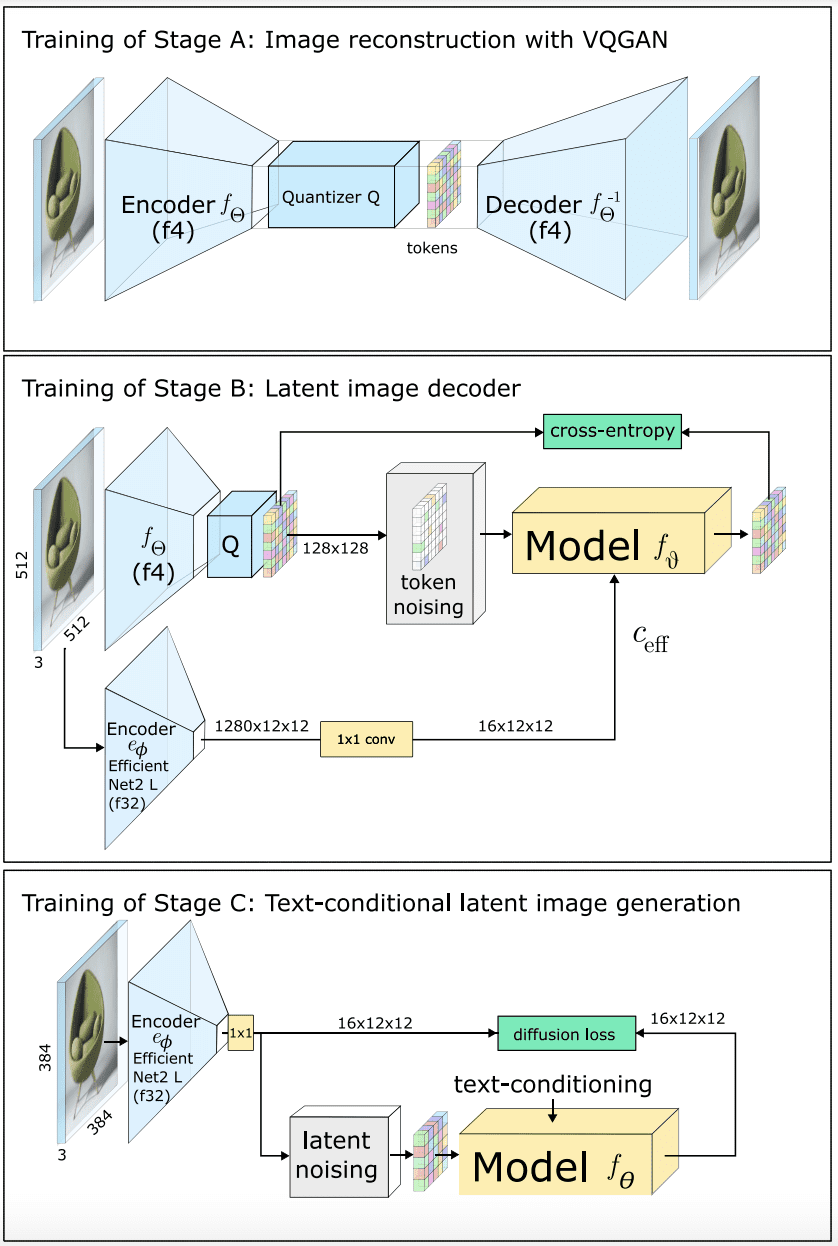
In the first stage, the EfficientNet model generates a highly compressed image using a text-conditional latent diffusion model (Stage C). This representation is then transformed into an enlarged and quantized latent space by a secondary model responsible for this reconstruction (Stage B). In the third stage, using VQGAN, tokens composing the latent image at this intermediate resolution are decoded to obtain the output image (Stage A). Training this architecture is done in reverse order, starting from Stage A and progressing to Stage B and Stage C.
Results of Würstchen
Comparison of the zero-shot Fréchet Inception Distance (FID) metric with other state-of-the-art text-to-image generation methods at image resolutions of 256×256 and 512×512:
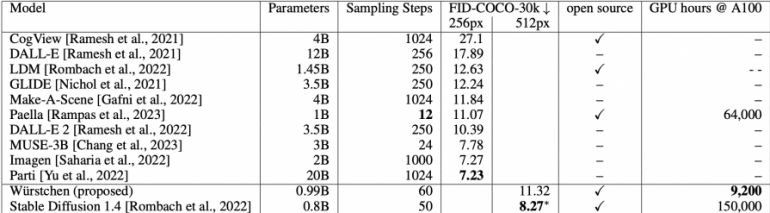
The most resource-intensive training stage (Stage C) required only 9,200 hours of GPU work, compared to 150,000 hours for Stable Diffusion 1.4.











