
Researchers from Adept have introduced the open-source language model Persimmon-8B with a 16k token context, which is four times larger than the most compact Llama 2 and text-davinci-002 used in GPT-3.5. The extended context allows the model to handle longer prompts, thereby addressing more complex and diverse tasks. Persimmon-8B requires three times less training data compared to Llama-2-7B and operates on a single Nvidia A100 GPU. The model is distributed under the open-source Apache license, permitting the copying, modification, and commercial use of its source code. The source code for the chat and base models is available on Github.
Architecture and Model Training
Persimmon-8B is a standard decoder-transformer with architectural modifications. Using the ReLU activation function often results in 90% of the output activations being zeros, providing interesting optimization opportunities. Additionally, researchers preferred Rotary Positional Encoding from the rotary positional encoding library Alibi and added layer normalization to the Q (query) and K (key) embeddings before utilizing them in the attention mechanism.
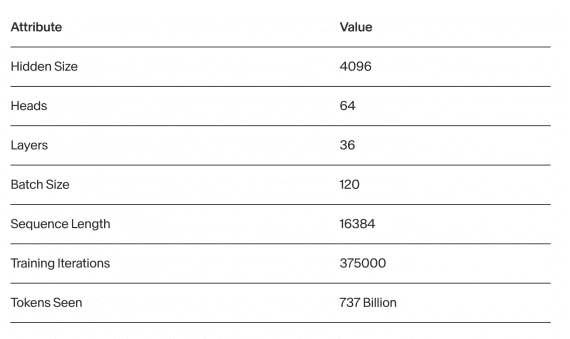
The model was trained on sequences of 16k tokens using a dataset containing 737 billion tokens, comprising approximately 75% text and 25% code. Typically, models are trained on contexts no longer than 4k tokens with subsequent context expansion. Training on such a lengthy sequence throughout the training process became feasible thanks to the development of an improved version of FlashAttention and adjustments to the basic rotary calculation mechanisms.
Persimmon-8B Results
Researchers compared the Persimmon-8B model with the most performant models of similar sizes — LLama 2 and MPT 7B Instruct. The fine-tuned Persimmon-8B-FT model outperformed them on benchmarks like MMLU, Winogrande, Arc Easy, Arc Challenge, and HumanEval:
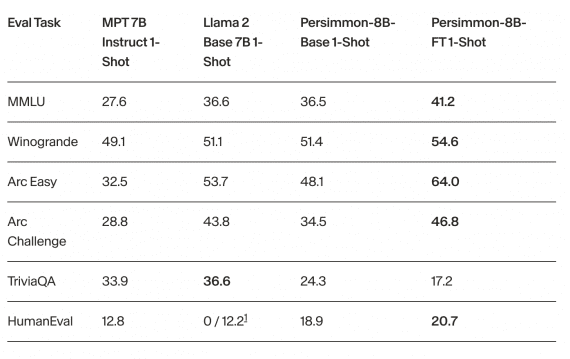
The base model Persimmon-8B-Base demonstrated performance comparable to Llama 2 despite using three times less training data.











