Researchers from Xiaohongshu introduced DeepEyesV2 — an agentic multimodal model based on Qwen2.5-VL-7B that can not only understand text and images but also actively use external tools: execute Python code and search for information on the internet. Unlike existing models that work either only with images or only with search, DeepEyesV2 combines both approaches into a single reasoning loop.
The project is fully open-source. Researchers published the trained model weights on HuggingFace, training code under Apache license in the GitHub repository, and fully released the training datasets: Cold Start data and RL dataset. The experiments also tested models based on Qwen2.5-VL-32B, demonstrating the applicability of the approach to larger models.
The Problem with Existing Approaches
Current multimodal large language models (MLLMs) understand images and text well but remain passive. They cannot independently invoke tools for working with images or obtaining up-to-date information from the internet.
For example, if you ask a model to identify a flower species in a photo, a simple model will try to answer based on its knowledge and often make mistakes. DeepEyes (previous version) learned to crop the relevant area for detailed analysis but couldn’t verify the answer through search. MMSearch-R1 can search the internet but works poorly with fine details. DeepEyesV2, however, first crops the flower area, then finds similar images through search, verifies information with a text query — and only then provides an accurate answer.
How DeepEyesV2 Works
DeepEyesV2 works cyclically: the model decides when and which tools to invoke, receives results, and integrates them into the reasoning process.
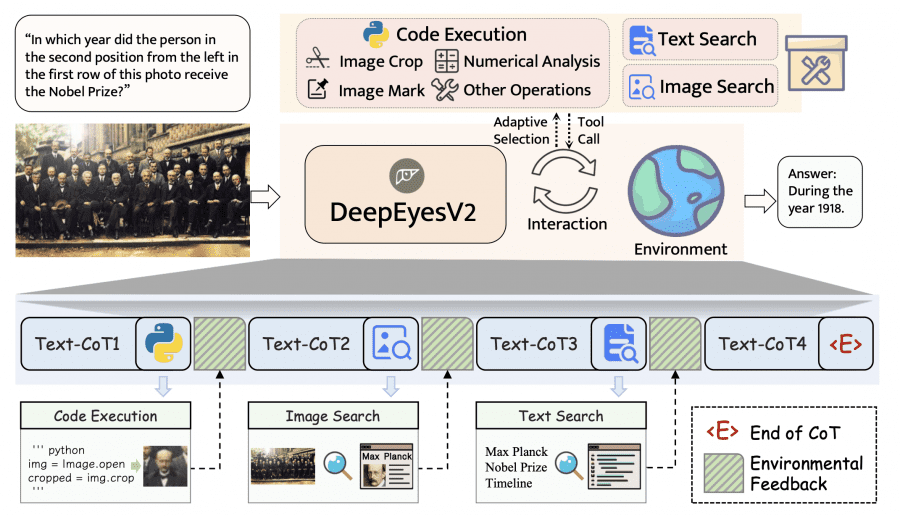
Available tools include Python code execution for working with images and data (cropping, numerical analysis, marking), image search via SerpAPI (top-5 visually similar results), and text search (top-5 relevant web pages).
Why Direct Reinforcement Learning Doesn’t Work
Researchers first tried to train the Qwen2.5-VL model directly through reinforcement learning (RL). The result was unexpected: in early stages, the model generated buggy code, then gradually abandoned tools and only produced short reasoning chains.
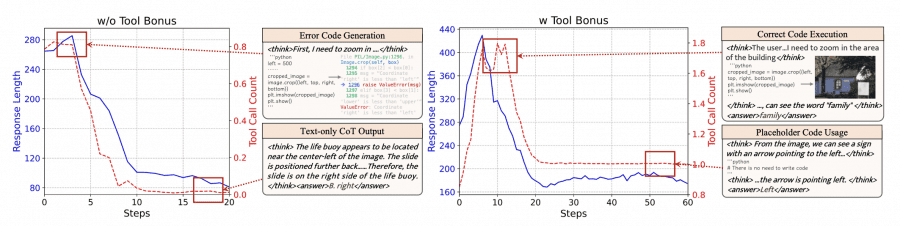
After adding a bonus for tool usage, the model began generating a single block of non-executable comments for each query — a classic example of reward hacking. This experiment showed: existing models cannot reliably learn to use complex tools through direct RL. They need preliminary preparation — a cold start.
Two-Stage Training
Stage 1: Cold Start
Researchers collected a dataset covering perception, reasoning, and search tasks. The dataset underwent strict filtering: only questions with which the base model succeeds in at most 2 out of 8 attempts were retained, and tool utility was verified.
Data was divided into two subsets. Examples solved with tools were reserved for RL. More difficult examples were used for cold start, generating detailed trajectories for them using advanced models (Gemini 2.5 Pro, GPT-4o, Claude Sonnet 4). After supervised fine-tuning, the model acquired basic tool-use patterns.
Stage 2: Reinforcement Learning
After cold start, RL was applied for further improvement. The reward function included accuracy reward and format violation penalty. Importantly, complex techniques were not used — only two simple metrics.
According to DeepEyesV2 documentation, training requires significant computational resources.
Minimum requirements for 7B version:
- Minimum 32 GPUs (4 nodes with 8 GPUs each);
- Minimum 1200 GB CPU RAM per node;
Reason for high RAM requirements: high-resolution images consume large amounts of memory.
For 32B version:
- Minimum 64 GPUs (8 nodes with 8 GPUs each);
- Same RAM requirements (1200 GB per node).
RealX-Bench: A New Benchmark
Existing benchmarks evaluate models on isolated capabilities, but real-world tasks require them to work together. Researchers created RealX-Bench — a benchmark for evaluating coordinated perception, search, and reasoning.
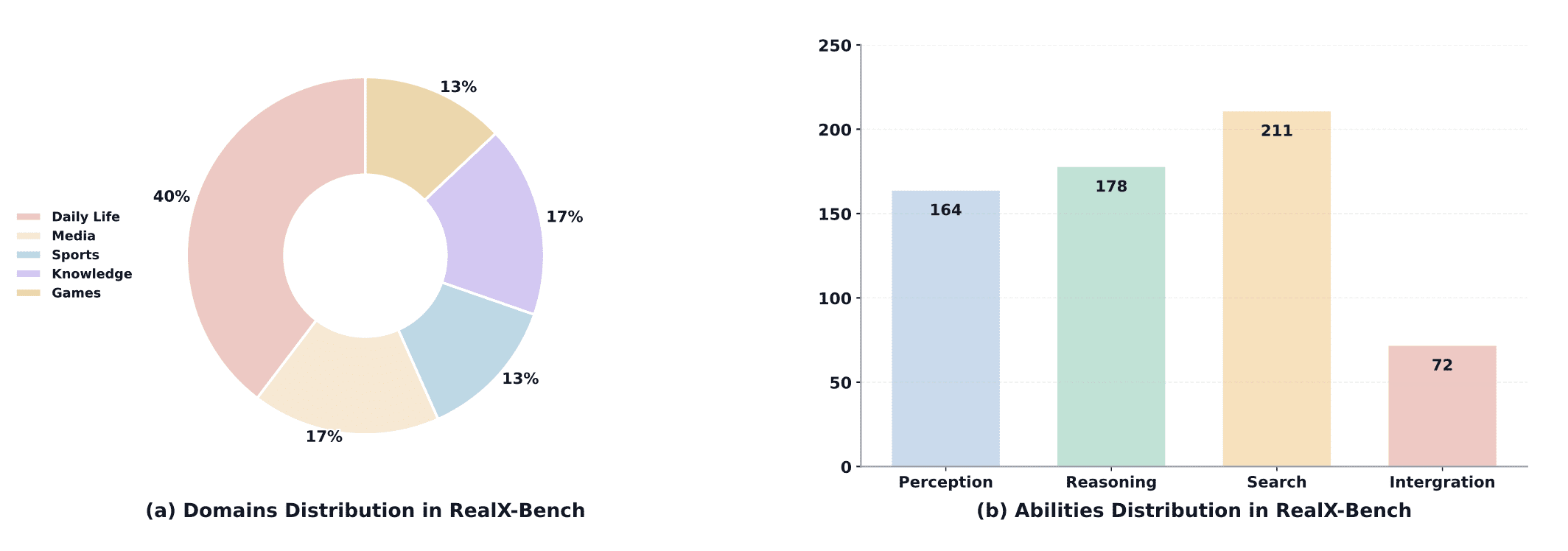
RealX-Bench contains 300 question-answer pairs from five real-world domains. By difficulty level: 164 questions require perception, 178 — reasoning, 211 — search. 72 questions (24%) are simultaneously challenging across all three aspects. Even the best model (Gemini 2.5 Pro) achieves only 46.0% accuracy, far from human-level performance (70.0%).
Experimental Results
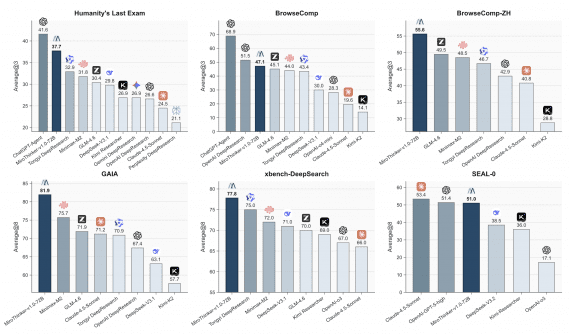
DeepEyesV2 showed impressive results across three benchmark categories.
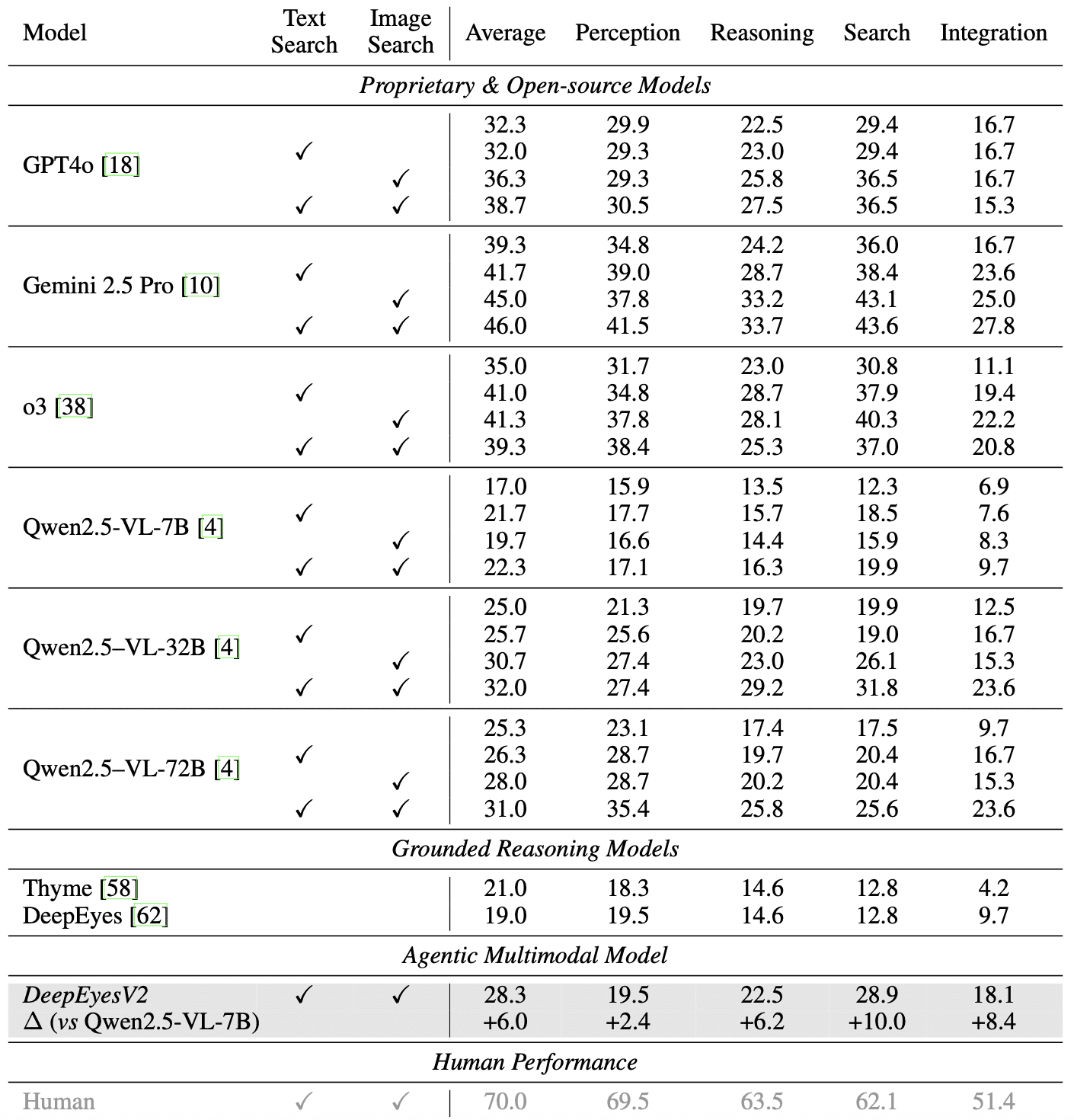
RealX-Bench: 28.3% average accuracy (+6.0 pp above base model). On the subset integrating all three capabilities: 18.1% vs 6.9% (+8.4 pp):
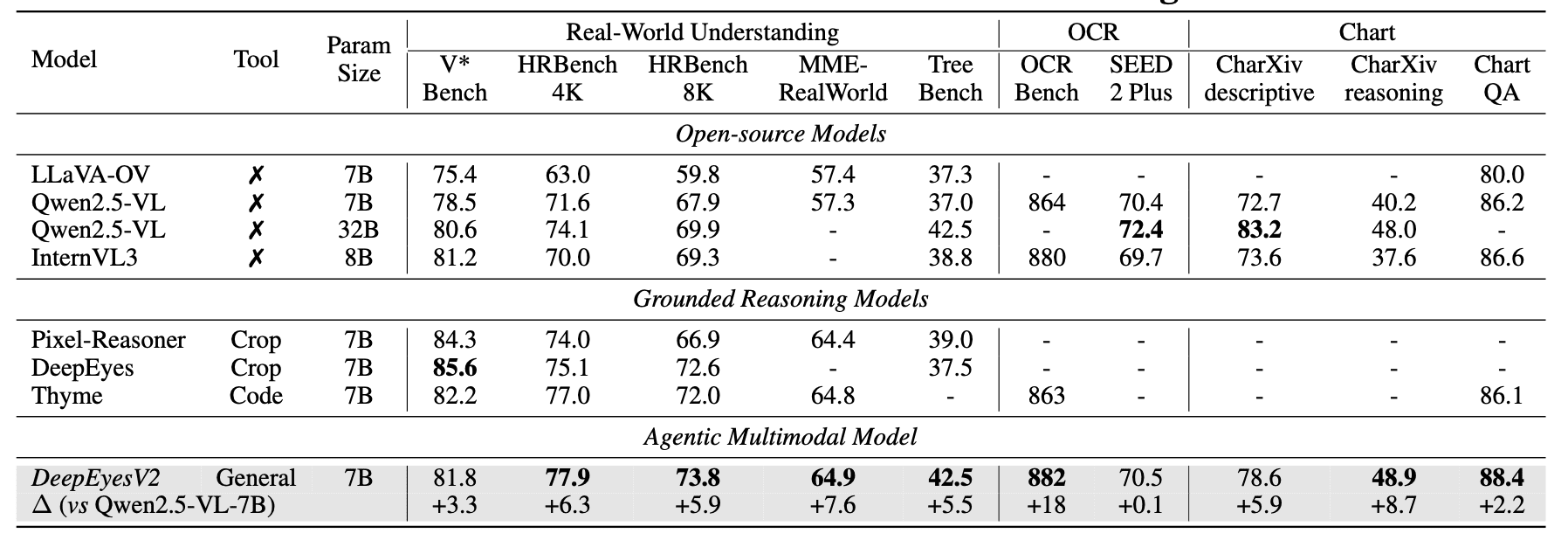
Real-world understanding. Improvements from +0.1 to +8.7 percentage points on V*Bench, HRBench, MME-RealWorld and other benchmarks. On some benchmarks, DeepEyesV2 (7B) even surpasses Qwen2.5-VL-32B:
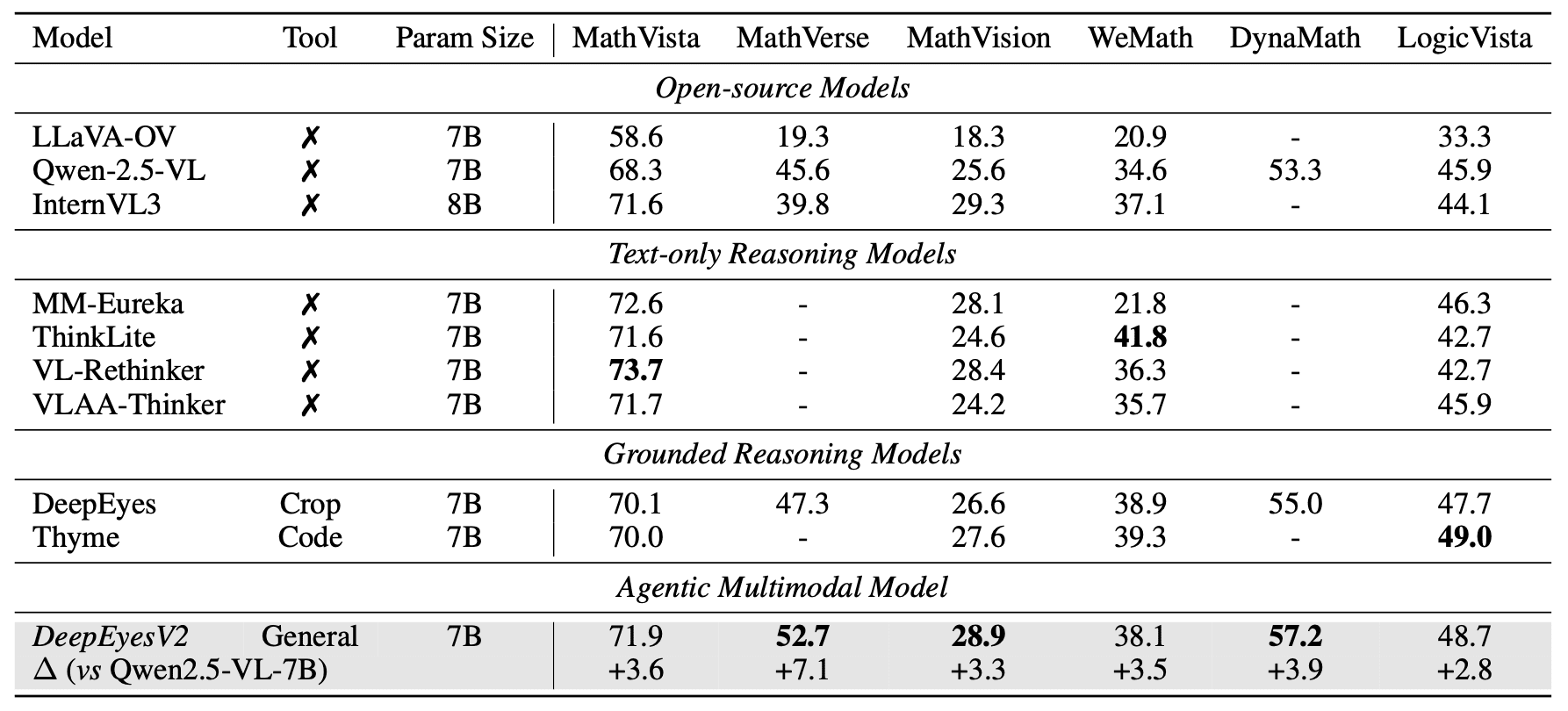
Mathematical reasoning. On MathVerse, +7.1 pp improvement (to 52.7%), surpassing both general models and specialized reasoning models:
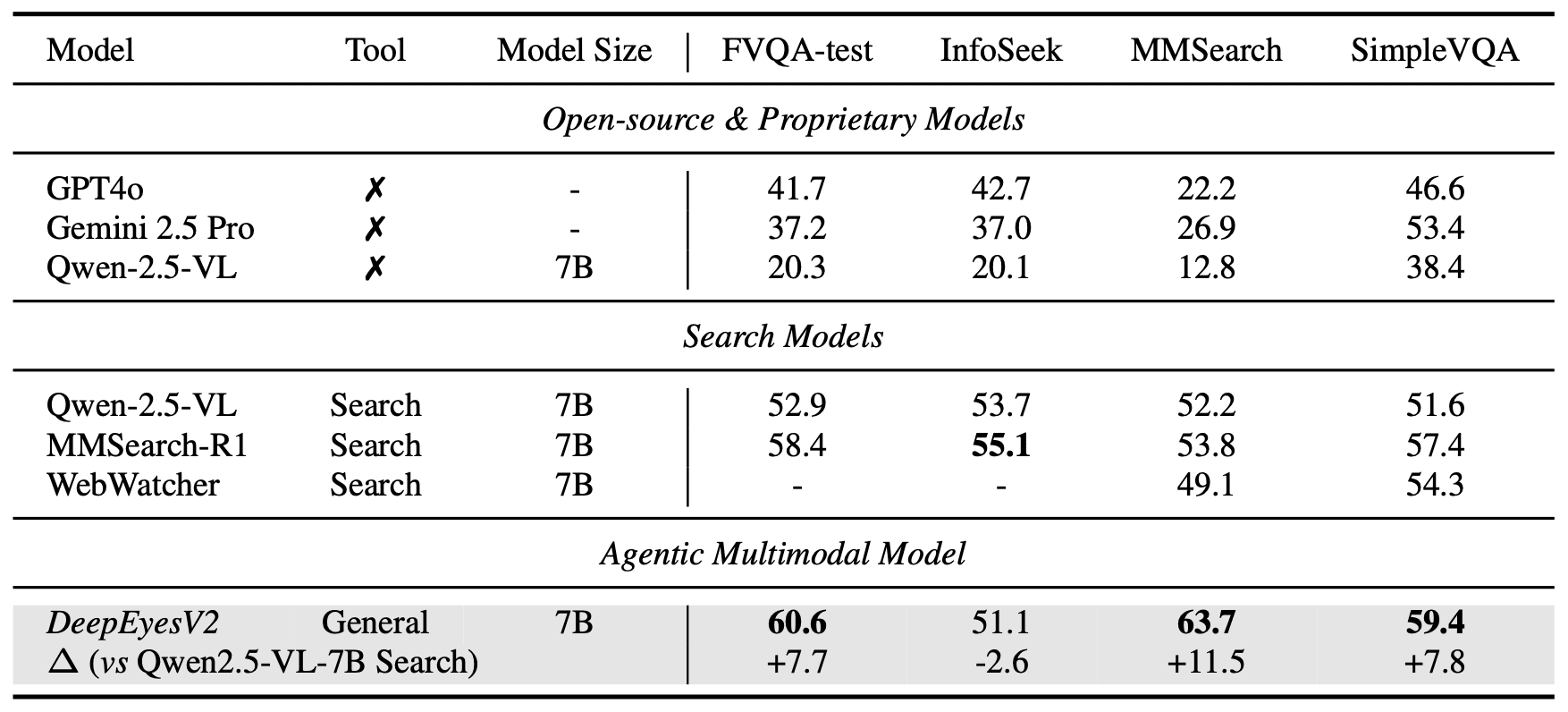
Information retrieval. On MMSearch 63.7% (+11.5 pp), significantly ahead of specialized MMSearch-R1 (53.8%):
Model Behavior Analysis
DeepEyesV2 demonstrates clear adaptive patterns. For perception tasks, it uses image cropping; for mathematical tasks — computations; for search tasks — search tools. After RL, the model begins integrating different tool types, for example, combining cropping with search.
Before RL, the model over-relied on tools. After RL, the invocation frequency decreased, but the model learned adaptive reasoning: it solves simple tasks directly but uses tools when beneficial.
Data analysis showed that data diversity is critically important: combining perception data, reasoning data, and long chain-of-thought data yields the best results.
Main research conclusion: despite excellent results on academic tests, agentic models are still far from real-world performance levels. RealX-Bench provides concrete metrics for tracking progress. The dataset will be expanded and the methodology adapted for improving models.