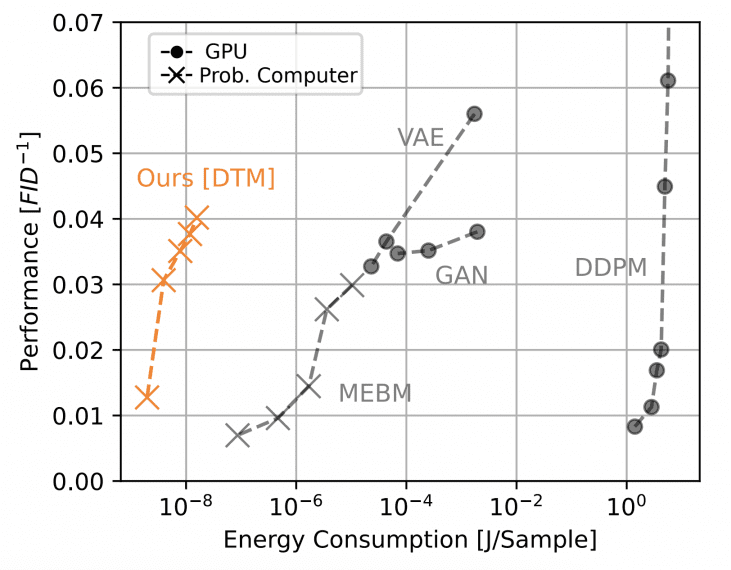
Researchers from Extropic Corporation presented an efficient hardware architecture for probabilistic computing based on Denoising Thermodynamic Models (DTM). Analysis shows that devices based on this architecture could achieve performance parity with GPUs on a simple image generation benchmark while consuming approximately 10,000 times less energy. DTMs represent a sequential composition of Energy-Based Models (EBMs) implemented at the hardware level through transistor-based random number generators.
Denoising Thermodynamic Computer Architecture
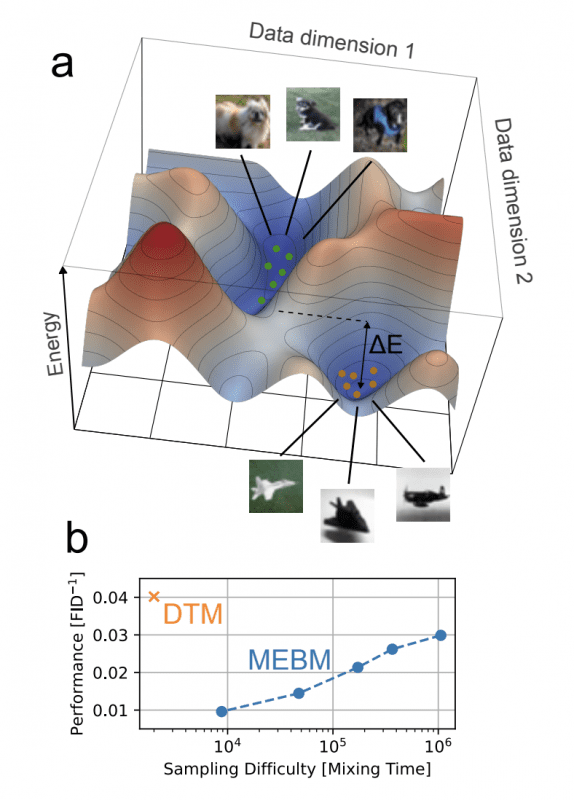
Traditional approaches to probabilistic computing used monolithic EBMs for direct modeling of data distributions. This created a fundamental problem called the mixing-expressivity tradeoff: the more accurately a model describes complex data, the harder it becomes to generate samples from it.
The reason lies in the structure of the energy landscape—a function that assigns an “energy” value to each possible data variant. Data similar to the training set receives low energy (valleys in the landscape), while dissimilar data receives high energy (mountains).
For example, if a model is trained on photographs from the Fashion-MNIST dataset containing clothing images:
- Low energy (valley): clear image of a boot, dress, or t-shirt
- High energy (mountain): random noise, blurry blob, unreadable pixels
For complex data, the landscape contains multiple isolated valleys—called modes. Each mode corresponds to a separate data category: one mode for shoe images, another for dresses, a third for t-shirts. The generation algorithm must “travel” across this landscape, but the probability of transitioning between modes through an energy barrier of height ΔE is exponentially small: P ∝ e^(-ΔE).
To transition from generating boots to generating dresses, the algorithm needs to pass through a region of data dissimilar to the training set (climb the mountain between modes), which happens extremely rarely. As a result, the algorithm gets stuck in one category for thousands of iterations, making training unstable and generation energy-intensive.
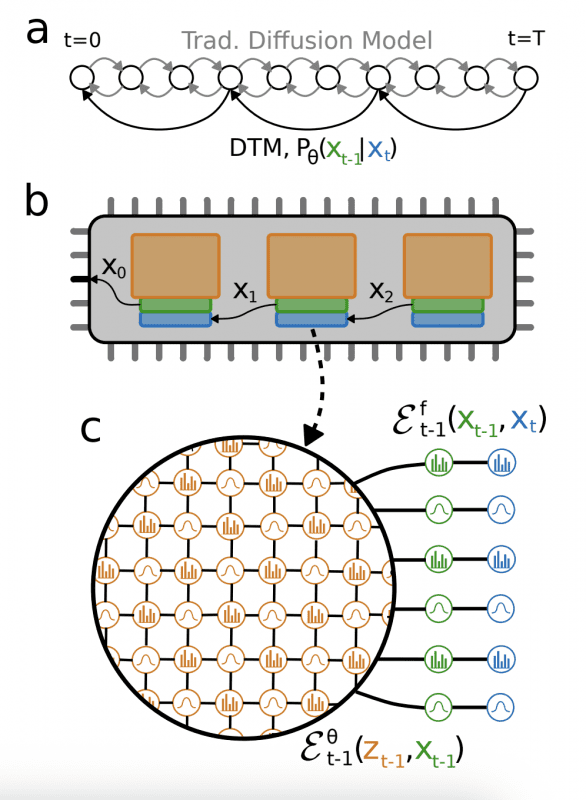
DTMs solve this problem through decomposition: instead of one EBM with a complex multimodal landscape, a chain of simple EBMs with gentle landscapes is used, across which the sampling algorithm moves efficiently. Each EBM performs a small transformation—one step of gradual noise removal, and the sequential composition of transformations models the complete data distribution without accumulating complexity in a single model.
The DTCA (Denoising Thermodynamic Computer Architecture) is built on a simple principle: the process of adding noise to data is implemented through local connections between sequential states. Each hardware EBM in the chain is responsible for one denoising step—it receives a noisy image and restores a slightly less noisy version.
The energy function of each EBM consists of two components. The first is a fixed part that connects the current state with the previous one (implements the noising process). The second is a trainable part that learns to recognize data structure. Critically, the fixed part requires only simple pairwise interactions between neighboring variables—each pixel is directly connected only to the corresponding pixel in the previous step. Such locality is ideal for hardware implementation: long wires to connect distant chip elements are not required, which minimizes energy consumption and simplifies manufacturing.
Transistor-Based Random Number Generator
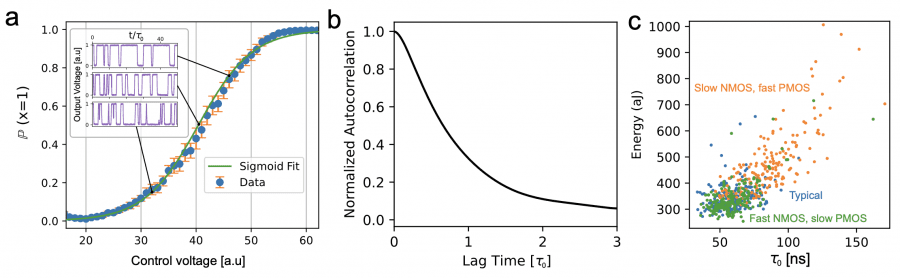
The main innovation is a fully transistor-based random number generator that uses current fluctuations in transistors operating in the subthreshold regime. Experimental measurements show that the generator produces random bits at a rate of about 10 million bits per second, consuming approximately 350 attojoules per bit. The output characteristic of the generator—the probability of getting one or zero—is described by a sigmoid function of the control voltage. This feature allows direct implementation of the Gibbs sampling algorithm for Boltzmann machines: by changing the voltage, one can control the switching probability of each bit, which is required for conditional state updates in the probabilistic model.
Using transistors exclusively eliminates uncertainty in communication costs between different technologies and enables principled forecasting of device performance. The energy consumption model is built on measurements of real circuits, physical models, and simulations, accounting for contributions from the RNG, biasing circuit, clock signal, and inter-cell communications.
Results and Comparative Analysis
Experimental results on the Fashion-MNIST dataset demonstrate the superiority of DTMs over monolithic EBMs. An 8-layer DTM achieves a generation quality of FID 28.5 (the lower the Fréchet Inception Distance metric, the more realistic the images). Each layer uses a Boltzmann machine with a 70×70 node grid, where each node is connected to 12 neighbors according to the G12 pattern—meaning connections to nearest neighbors and several distant connections to capture more complex dependencies.
The energy consumption for generating one image is approximately 1.6 trillion nanojoules, which is four orders of magnitude less than the most efficient GPU solution.
For training stabilization, an Adaptive Correlation Penalty (ACP) is applied—a mechanism that dynamically regulates model complexity based on how quickly the generation algorithm moves across the energy landscape. ACP tracks autocorrelation—the degree of similarity between successive samples: if the algorithm gets stuck and generates similar variants, autocorrelation is high. The mechanism maintains autocorrelation below a specified threshold (e.g., 0.03), automatically finding a balance between model expressivity and generation speed.
Physical modeling shows that a 6×6 millimeter chip can accommodate about one million computational cells, significantly exceeding the requirements of experimental models (the largest DTM used approximately 50 thousand cells). Further scaling of probabilistic computing is envisioned through hybrid thermodynamic-deterministic architectures: a small classical neural network converts color images into a binary representation compatible with DTM, after which the probabilistic computer performs the main generation work.
Experiments on the CIFAR-10 dataset showed that to achieve the same quality, the classical part of the hybrid model can be 10 times smaller than the generator in a traditional Generative Adversarial Network (GAN).


