
Generative Adversarial Networks are one of the most promising recent developments in the area of Deep Learning. GANs are generative models that have recently become very popular among the machine learning community. In a sense, Generative Adversarial Networks are able to generate completely new data samples that keep the characteristics of some specific domain. Therefore, this kind of models have attracted a lot of interest and have numerous applications.

Throughout time, GANs have proved that given enough modeling power they can model high-dimensional data distributions and provide a generative model. For example, they can model realistic images distributions and generate novel images that resemble the training set. This powerful family of models in deep learning has been brought by an innovative combination of deep neural networks and game theory (GANs, Ian Goodfellow, 2014). Generative Adversarial Networks consist of two networks: Generator (a network generating samples from a latent code) and Discriminator (a network who has to asses the generated sample). The ultimate goal is to be able to generate samples from a distribution almost indistinguishable from the training set distribution.
There are two key things to keep in mind when it comes to Generative Adversarial Networks: quality of the generated data sample (in terms of how realistic it is w.r.t. the training data) and variational capabilities. The goal of the generative process is to maximize both of them. Several problems have arisen in the way of achieving this goal and they have been addressed in different ways. However, the conventional wisdom is that there should always be the trade-off between the data quality and the variation. Intuitively, this can be explained in a way that: constraining the modeled distribution to preserve the quality squeezes the distribution in the space that results with the constrained variation of the generated data samples.
The difficulty of the task of generation grows with the dimensionality of the data distribution. Talking about images (where GANs are mostly used), generating high-resolution images with GAN network represents a difficult task. First because of the lack of ability to capture small details (which is easily noticeable in high-resolution images) and second, the long and unstable training process.
Novel Concept
Researchers at NVIDIA and Aalto University, have addressed both of this issues with an innovative concept called “Progressive Growing of GANs”. The idea is simple: evolving both neural networks in the GAN network (the Generator and the Discriminator) by adding new layers through the training process. Along the main idea, they introduce a few other improvements in the training of GANs towards the problem of generating realistic high-resolution images.
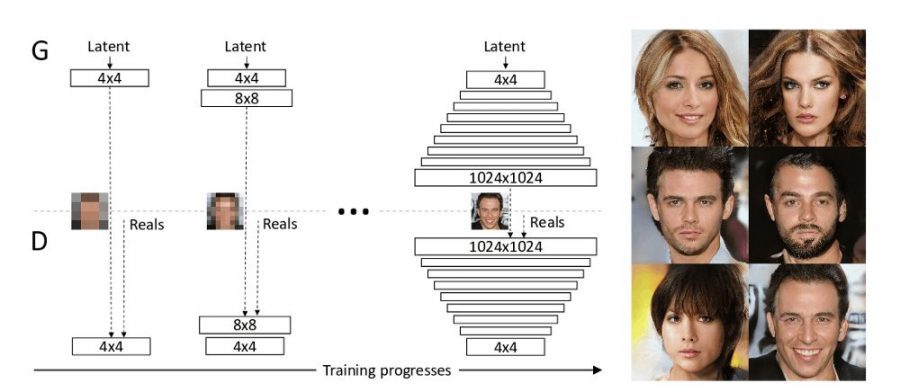
Evolving GANs Throughout Training
The idea behind growing the network(s) during training time is to allow the model to discover and learn large-scale structures in the image distribution and then slowly move towards discovering finer details. This guarantees faster and more stable training at first place, as well as better quality in the resulting images. The improved quality comes mostly from the nature of generative models (especially GANs) where the mapping from a latent code to a realistic output image is somehow very complex. Thus, learning the mapping gradually is easier than learning it at once or learning it with a hierarchy of models. In the proposed work, the authors use mirrored Generator and Discriminator networks, starting with very low spatial resolution at the beginning (as small as 4×4) and progressively growing the network to a high-resolution (of 1024×1024 in the case).
Normalization in Generator and Discriminator
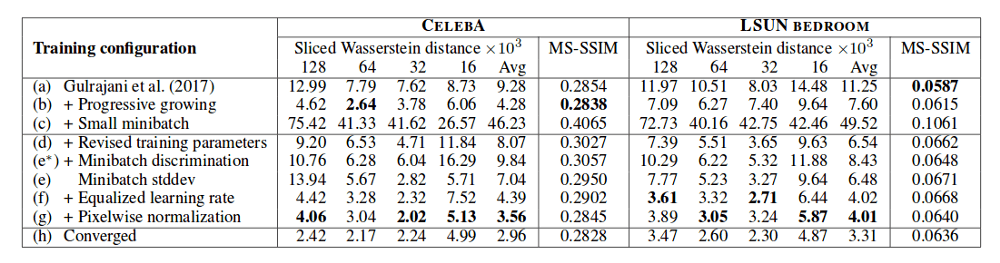
Tofurther improve generated image quality, the variation and the stability and speed of the learning process the authors shift the focus to data normalization in both networks (generator and discriminator). They discover that the unhealthy competition between the two networks (Generator and Discriminator) in GANs represents a problem in the learning process and therefore they propose constraining the competition and the signal magnitude in the networks to obtain more stable and faster learning. To achieve this, two exciting ideas were introduced: novel weight initialization and pixel-wise feature vector normalization.Not only the network is evolving through training time but also the weights magnitude. Interestingly, their approach seems to improve results by making things dynamic. When it comes to weight initialization, what they have done is to initialize the weights with trivial normal distribution with zero mean and variance of 1 and explicitly scale the weights at runtime. This is the constraining in magnitudes mentioned before, and it improves the learning when the optimizer is scale-invariant (like RMSProp, ADAM, etc.)
To constrain the competition among the networks, the authors propose pixel-wise feature vector normalization which is, in fact, normalizing the feature vector in each pixel to the unit length. This is done as usual, after each convolutional layer in the generator network.
The proposed method and the improvements were assessed mainly using CELEBA dataset which contains 30 000 high-resolution images (1024×1024) of faces of celebrities. The details are important and easily noticeable, and that’s why this dataset is pretty well suited for evaluation of this new concept. The results show higher perceptual quality and vastly more variation than existing methods. Also, the stability and speed of the learning process were confirmed when training using high-resolution images like the ones from CELEBA. As an additional contribution, a higher-quality version of the CELEBA dataset called CELEBA-HQ was constructed and will be published by the authors.

This new concept of progressive growth of generative model shows promising results, and we may expect to see many applications and improvements coming from it. Still, there is a long way to true photorealism and generation of high-quality images that are perceptually indistinguishable from real ones.







