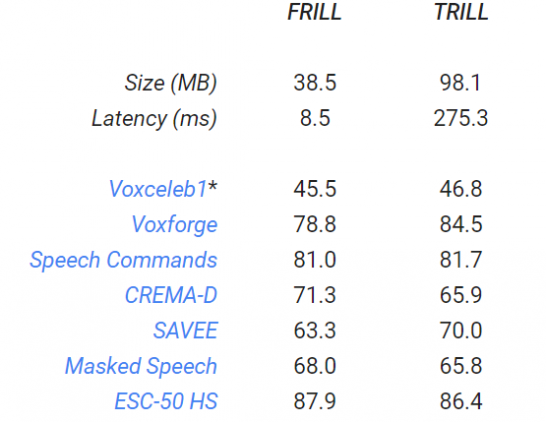
Google AI introduced FRILL — an improved version of the TRILL speech representation model released last year. FRILL is 32 times faster and takes up 2.5 times less space than TRILL, which allows it to be used on mobile devices.
Representation learning is a machine learning method in which a model is trained to recognize characteristic features in data that can be applied to a wide range of tasks from natural language processing to image analysis and classification. For example, you can use TRILL to determine a person’s age or the language they speak. However, the use of TRILL on mobile devices is also hampered by its insufficient performance. FRILL is 40% the size of TRELL and runs 32 times faster on a mobile phone with an average accuracy reduction of less than 2%. This makes it possible to generate speech representations on smartphones, resulting in better personalization, better user experience, and more privacy.
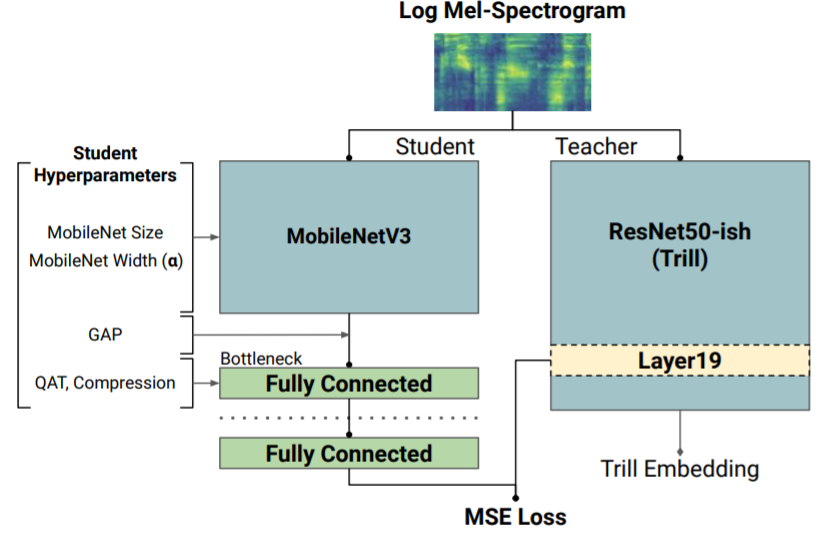
The TRILL architecture is based on a modified version of ResNet50, an architecture that is computationally expensive. Therefore, when developing FRILL, Google conducted a large-scale analysis of the effectiveness of existing low-resource architectures based on the non-semantic speech standard (NOSS) and two new tasks-determining whether a speaker is wearing a mask, and isolating talking people from the surrounding noise. The MobileNetV3 architecture coped with these tasks with the best accuracy/performance ratio and formed the basis of FRILL. To date, FRILL is the most efficient speech representation model among models with a delay time of less than 10 ms. As shown in the figure below, the model has comparable test results to TRILL, but the FRILL delay time (8.5 ms) is 32 times less than the TRILL delay time (275.3 ms):