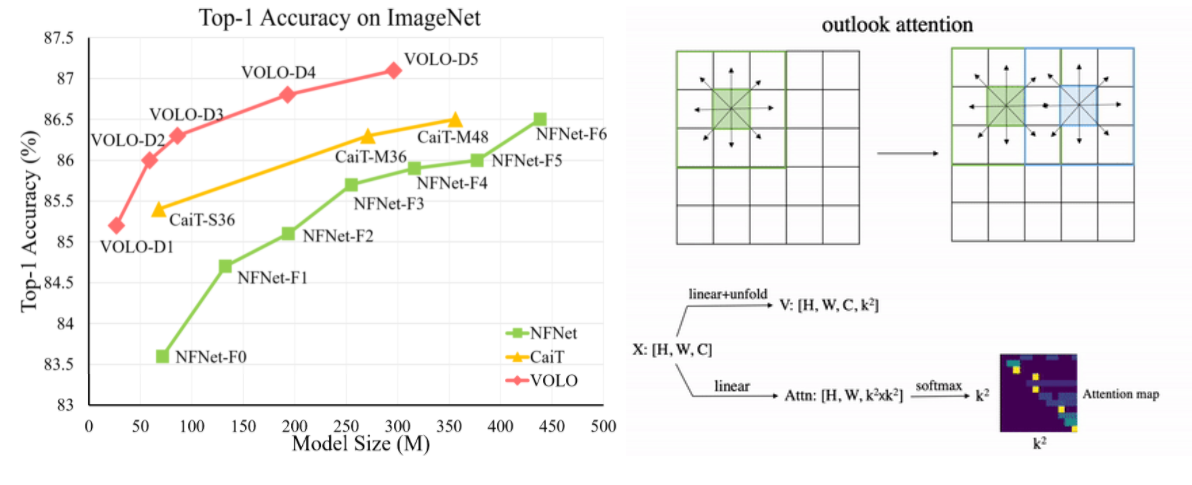
Vision Outlooker (VOLO) is a variation of the Vision Transformer architecture. Designed to reduce reliance on additional training data, VOLO reached a record 87.1% on ImageNet without pre-training. The code is publicly available.
Why is it needed
For years, convolutional neural networks (CNNs) have dominated the image classification task. On the other hand, the newer Vision Transformer (ViT) architecture, based on the attention mechanism, performed better when relying on pre-training. However, the performance of transformers without additional training data is still inferior to modern convolutional networks. The authors strive to close the performance gap and demonstrate that attention-based models can outperform CNNs.
How it works
The authors found that ViT inefficiently encodes fine-level features into semantic tokens early in the architecture. This factor limits the performance of transformers on the popular ImageNet dataset. The Vision Outlooker (VOLO) architecture attempts to address this problem. In VOLO, the outlook attention replaces self-attention.
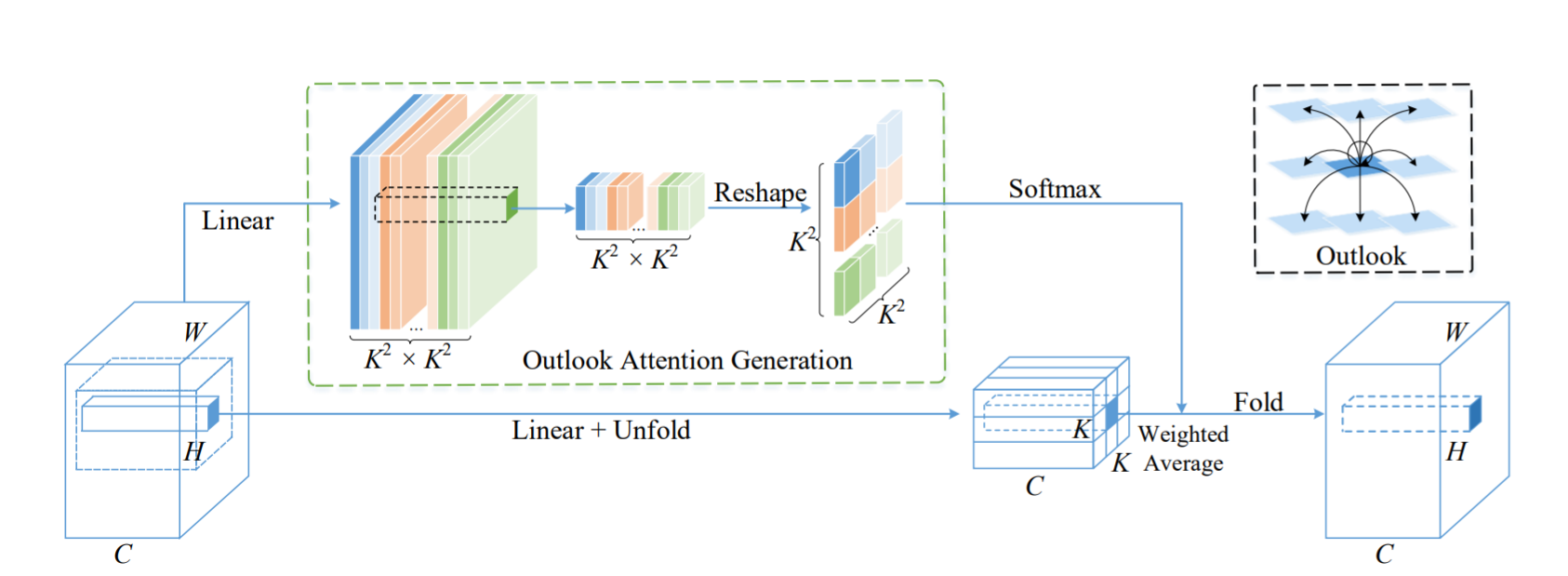
Unlike self-attention that focuses on global dependency modeling at a coarse level, the outlook attention aims to encode finer-level features into tokens. The main advantages of the proposed outlook attention mechanism:
- explores feature space more efficiently than convolution.
- tags fine-level tokens locally, which preserves positional information in the image.
- computes an attention map with lower computational costs compared to self-attention, without using a dot product.
The VOLO architecture works in two stages. During the first stage, it applies a sequence of Outlooker modules that include outlook attention. During the second stage, it applies a sequence of transformers in order to aggregate the image contents.
Results
VOLO reaches 87.1% in terms of top-1 accuracy in the classification task on ImageNet. It is the first model to exceed 87% accuracy without additional training data. In addition, the pretrained VOLO model transfers to other tasks such as semantic image segmentation. The model achieved 84.3% mIoU on the urban landscape dataset and 54.3% mIoU on the ADE20K dataset.
Read more about VOLO in the arXiv article.
The code is available in the Github repository.