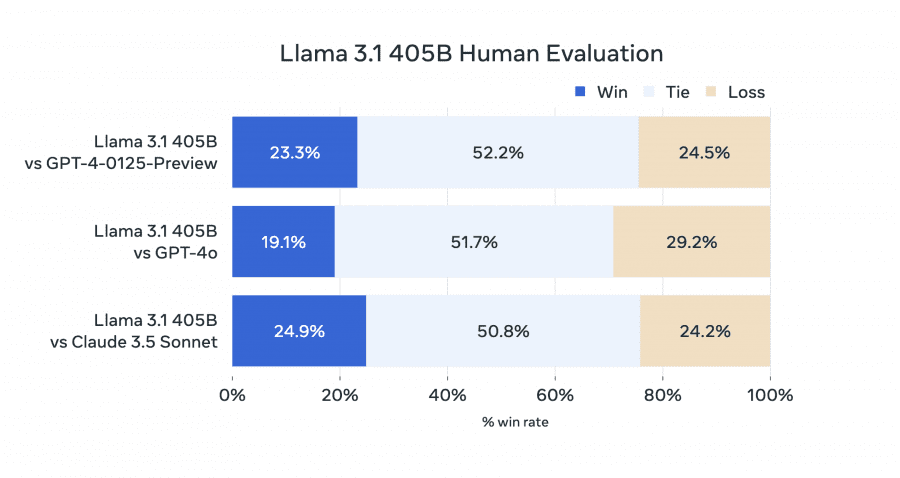
LLAMA 3,1 models has been officially released, including the massive 405 billion-parameter LLaMA 3.1 405B model. Expanded context length to 128K, support for eight languages, and the introduction of LLaMA 3.1 405B — the first frontier-level open-source AI model.
New Model Description and Architecture Notes
LLaMA 3.1 features several enhancements:
- Expanded Context Length: The context length has been extended to 128,000 tokens, allowing for more extensive and complex inputs, maintaining coherence over longer passages of text.
- Language Support: The model now supports eight languages, enhancing its versatility in multilingual applications.
- Frontier-Level Model: The flagship model, LLaMA 3.1 405B, features 405 billion parameters, making it the largest and most capable openly available foundation model. This scale allows for unmatched flexibility, control, and state-of-the-art capabilities, rivaling the best closed-source models.
Specific LLaMA 3.1 Models and Capabilities
- LLaMA 3.1 Base: Designed for general language understanding and generation tasks.
- LLaMA 3.1 Fine-Tuned: Tailored for specialized tasks in domains like legal, medical, or technical fields, significantly improving performance in these areas.
- LLaMA 3.1 Zero-Shot: Optimized for zero-shot learning, performing effectively on tasks it wasn’t explicitly trained on.
- LLaMA 3.1 Multi-Modal: Integrates text and image processing capabilities, extending its functionality to multi-modal data analysis.
Comparison to LLaMA 3
LLaMA 3.1 represents a significant upgrade over LLaMA 3. The context length has been extended to 128,000 tokens, compared to 12,000 tokens in LLaMA 3, improving the model’s ability to handle longer and more complex inputs. Studies show that increased context length can enhance performance in tasks requiring long-term dependency management (source).
Model Evaluations
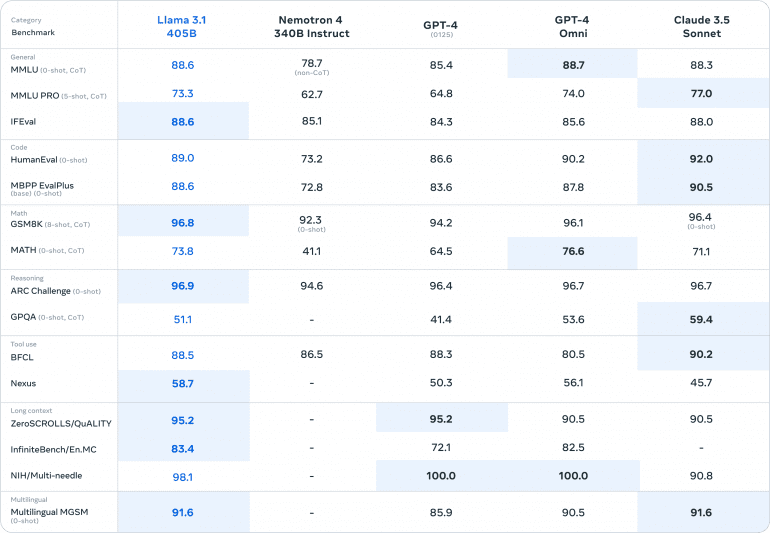
LLaMA 3.1 405B demonstrates outstanding performance across a wide range of benchmarks, outperforming other state-of-the-art models in various tasks
General
- MMLU (0-shot, CoT): LLaMA 3.1 scores 88.6, leading over Nemotron 4 (78.7), GPT-4 (85.4), GPT-4 Omni (88.7), and Claude 3.5 Sonnet (88.3).
- MMLU PRO (5-shot, CoT): LLaMA 3.1 scores 73.3, significantly higher than Nemotron 4 (62.7), GPT-4 (64.8), and GPT-4 Omni (74.0), but slightly lower than Claude 3.5 Sonnet (77.0).
- IFEval: LLaMA 3.1 achieves 88.6, surpassing Nemotron 4 (85.1), GPT-4 (84.3), and GPT-4 Omni (85.6), and closely matching Claude 3.5 Sonnet (88.0).
Code
- HumanEval (0-shot): LLaMA 3.1 scores 89.0, outperforming Nemotron 4 (73.2), GPT-4 (86.6), GPT-4 Omni (90.2), and Claude 3.5 Sonnet (92.0).
- MBPP EvalPlus (base) (0-shot): LLaMA 3.1 achieves 88.6, ahead of Nemotron 4 (72.8), GPT-4 (83.6), GPT-4 Omni (87.8), and closely behind Claude 3.5 Sonnet (90.5).
Training and Technical Enhancements
Training LLaMA 3.1 405B on over 15 trillion tokens involved:
- Optimized Training Stack: Leveraging over 16,000 H100 GPUs for efficient training.
- Quantization: Models were quantized from 16-bit to 8-bit numerics, reducing compute requirements and enabling single-node operation.
- Iterative Post-Training: Combining supervised fine-tuning and direct preference optimization to enhance performance across capabilities.
Pricing
Competitive pricing has been set for LLaMA 3.1, aiming to make this advanced AI technology accessible to a broad range of users. When comparing API request pricing:
- LLaMA 3.1: Priced around $0.01 per 1,000 tokens for standard usage.
- Gemini (Google DeepMind): Approximately $0.015 per 1,000 tokens.
- Sonnet (Claude): Costs about $0.012 per 1,000 tokens.
- GPT-4 (OpenAI): Around $0.03 per 1,000 tokens for standard access.
Building with LLaMA 3.1 405B
For the average developer, using a model at the scale of the 405B is challenging due to its significant compute requirements. The LLaMA ecosystem supports various advanced workflows, including synthetic data generation, model distillation, and retrieval-augmented generation, with partner solutions from AWS, NVIDIA, and Databricks.
Conclusion
LLaMA 3.1 represents a major leap forward in open-source AI, offering unprecedented capabilities and accessibility. With its expanded context length, multilingual support, and powerful 405B model, LLaMA 3.1 is set to drive innovation and open new possibilities for developers worldwide. The community is encouraged to explore and build with these advanced tools, contributing to a broader, more inclusive AI ecosystem.