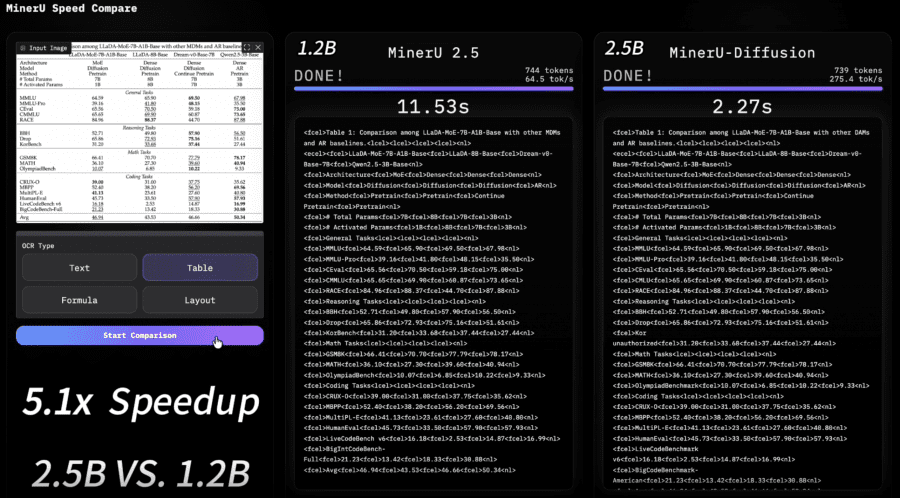
A team from Shanghai Artificial Intelligence Laboratory and Peking University published MinerU-Diffusion — a document OCR framework that abandons classical autoregressive generation in favor of diffusion-based decoding. The project is fully open-source: code is available on GitHub, and model weights on Hugging Face. Decoding speed increased 3.2× while maintaining accuracy comparable to the best autoregressive (AR) competitors.
MinerU-Diffusion is the third generation in the MinerU lineup: we wrote about MinerU2.5 in September 2025 — back then the team showed that a 1.2B model outperforms Gemini 2.5 Pro on document parsing benchmarks. After MinerU2.5’s release, the tool received several framework-level updates. In versions 2.6–2.7 (October 2025 – February 2026), the team added a hybrid backend combining pipeline and VLM, MLX acceleration support for Apple Silicon with 100–200% speed gains, updated OCR models to ppocr-v5 with 40%+ accuracy improvement for Cyrillic and Arabic, and simplified installation to a single command. MinerU-Diffusion is not another framework update — it is a standalone research contribution with a fundamentally different decoding approach.
The Drawbacks of Autoregressive OCR
Most modern OCR solutions are built on Vision-Language Model (VLM) architecture: a visual encoder converts an image into tokens, then an autoregressive (AR) decoder generates text token by token — left to right. This works, but the approach has a fundamental flaw. When a model generates tokens one by one, each next token depends on all previous ones. For a long document this is slow: latency grows linearly with output length. Worse, the model begins to rely not only on the image, but also on language patterns — meaning it “guesses” the text rather than reading it literally. When the semantic structure of a document is disrupted, AR decoders lose accuracy sharply, precisely because of this dependence on language priors.
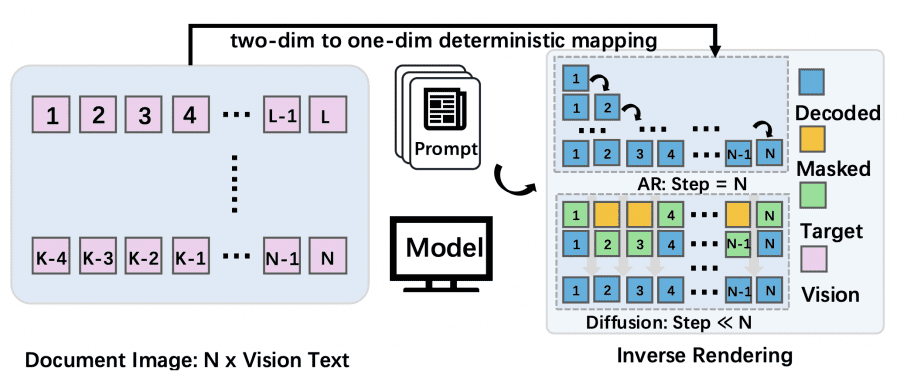
The authors reformulate OCR as inverse rendering. A document is two-dimensional: each element occupies a specific position on the page. To feed it into a language model, all elements must be flattened into a single token sequence. AR models treat this order as mandatory and generate text strictly left to right. But the choice of order is simply an engineering decision made during data preparation — it has nothing to do with the nature of the document itself. MinerU-Diffusion exploits this: since the order is arbitrary, tokens can be recovered in parallel rather than one at a time.
How Diffusion Decoding Works
MinerU-Diffusion replaces autoregression with a Diffusion Language Model (DLM) using discrete masking. The idea is straightforward: at the start, the entire output text is a set of [MASK] tokens. At each denoising step, the model looks at the document image and in parallel recovers the masked tokens, gradually revealing the text.
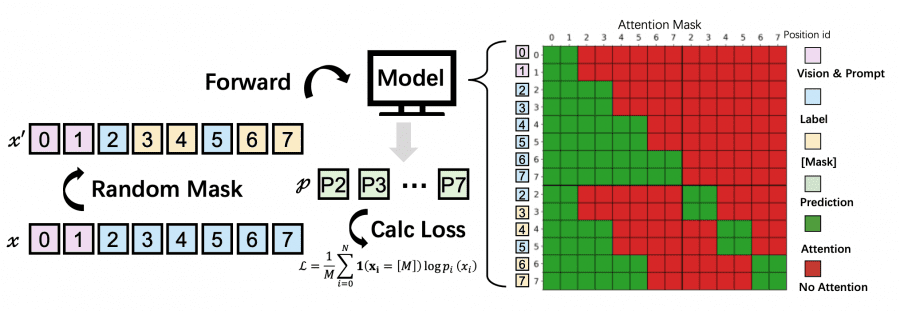
But simply applying full self-attention to the entire sequence is a bad idea: the quadratic complexity O(L²) kills performance on long documents. Instead, the authors introduce a Block Diffusion Decoder (Block-Attn). The sequence is divided into B blocks. Within a block, tokens can attend to any other token in the block (bidirectional attention). Across blocks — only causal attention: each block sees all previous blocks but not the following ones. This yields O(BL’²) instead of O(L²), and also allows KV-pair caching — just like in AR models.
Smart Parallelism Control: Dynamic Confidence Threshold
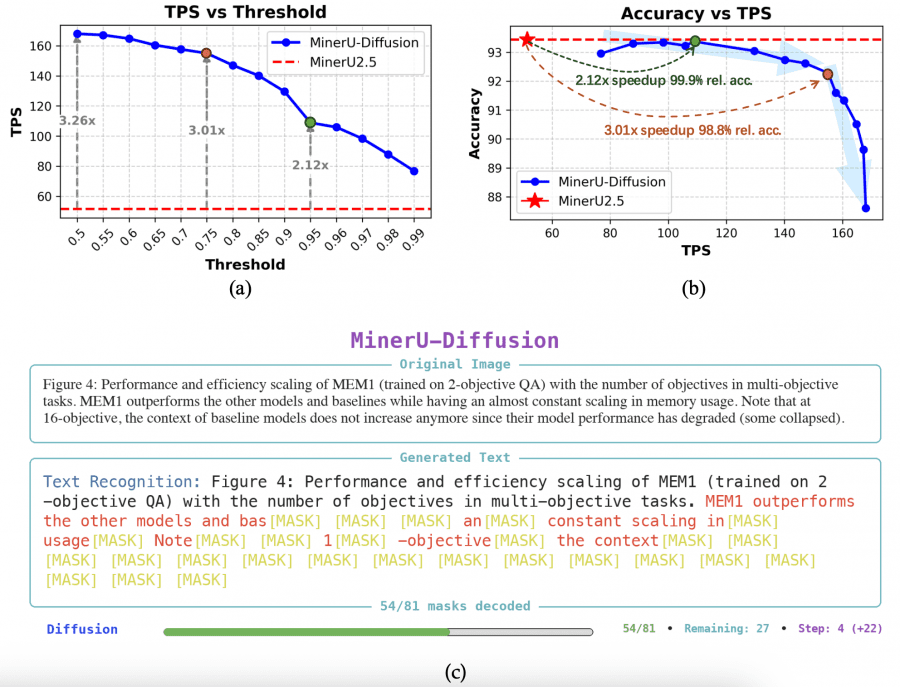
At each denoising step, the model outputs a probability for each token. If the probability exceeds threshold τ — the token is “confirmed” and no longer updated. If it falls below — it remains masked until the next step. The threshold τ directly controls the speed/accuracy trade-off. At τ = 0.5, almost all tokens are confirmed immediately — maximum speed, but higher risk of errors. At τ = 0.99, the model behaves almost like an autoregressive one — slow but reliable. At τ = 0.95, the model achieves 2.1× speedup at 99.9% relative accuracy compared to MinerU2.5. At τ = 0.6 — peak 3.2× speedup at accuracy above 90%.
Two-Stage Training with Uncertainty Awareness
Diffusion models are harder to train than AR: masking scatters the training signal, and the model uses data less efficiently. The authors address this through two-stage curriculum learning. In the first stage, the model is trained on a broad dataset of ~6.9 million document examples (Dbase). The goal is to learn general layout and recognition patterns. In the second stage, “hard” examples are selected — those where the model gave inconsistent answers across multiple consecutive runs. Inconsistency is measured using metrics: PageIoU for layout, CDM for formulas, TEDS for tables. These examples are annotated with human involvement, and the model is fine-tuned on them.

Semantic Shuffle: Testing for Hallucinations
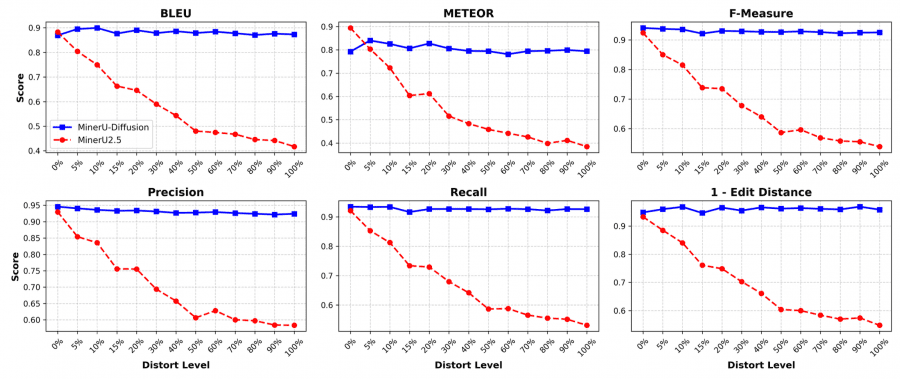
To test whether the model actually reads the image or simply guesses text from language patterns, the authors devised a dedicated benchmark. They take 112 English documents, shuffle the words in random order, and render the result into new images while preserving the original formatting. If the model relies on the visual signal — it should reproduce the nonsense just as accurately as meaningful text. If it relies on language priors — it will start “correcting” the text and lose accuracy.
AR decoders, as the degree of shuffling increases, sharply lose quality across all metrics. MinerU-Diffusion remains nearly stable — BLEU, METEOR, F-Measure, and edit distance barely change at any level of distortion.
Results
Speed in OCR tasks is measured in TPS (tokens per second). MinerU2.5 delivers ~52 TPS. MinerU-Diffusion at threshold τ = 0.95 achieves 108.9 TPS — 2.1× faster at virtually the same accuracy. At peak speed (τ = 0.6) — 164.8 TPS, i.e. 3.2× faster. For comparison: PaddleOCR-VL delivers 40.77 TPS, static decoding with 32 steps — only 21.86 TPS.
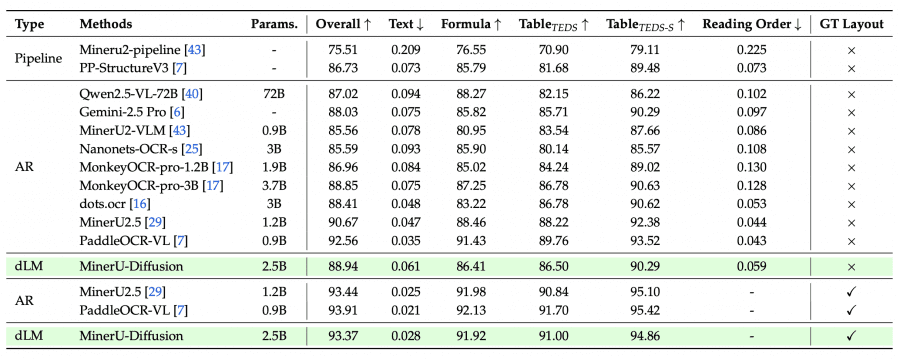
MinerU2.5 is a 1.2B AR model with a two-stage strategy: first layout analysis on a downscaled image, then fragment recognition at native resolution. It scores 90.67 Overall on OmniDocBench without a layout hint and 93.44 with one. MinerU-Diffusion is a 2.5B diffusion model with the same tasks but a fundamentally different decoder. Without a layout hint it scores 88.94 Overall — slightly below MinerU2.5. With a hint — 93.37, virtually on par. At equal accuracy MinerU-Diffusion runs 2.1× faster, and at peak speed — 3.2× faster. The trade-off is a model twice the size (2.5B vs. 1.2B).
On formulas: MinerU-Diffusion scores 91.6 on CPE (complex printed expressions) — worse than MinerU2.5 (96.6). On tables: TEDS-S 88.66 on OCRBench v2 vs. 90.62 for MinerU2.5. The gap is small, and the authors note that the main bottleneck is layout detection quality, not recognition itself.
Edit distance is a metric that counts how many operations (insert, delete, or replace a character) are needed to turn the recognized text into the reference text. The lower the value, the more accurate the recognition: 0.0 means a perfect match, 1.0 means a complete mismatch.
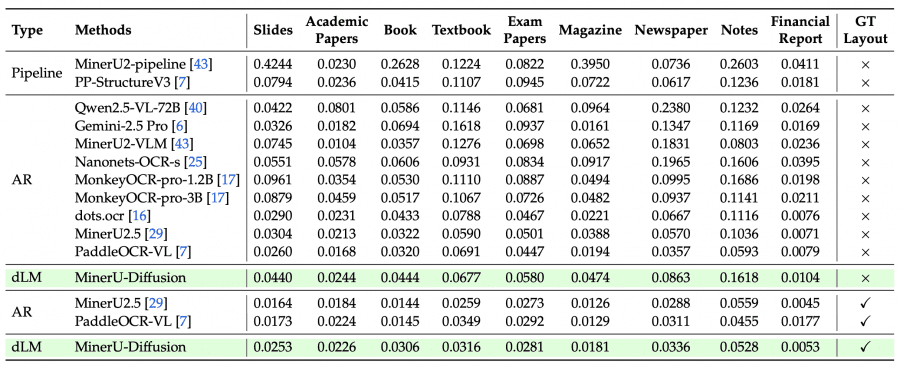
The per-page-type breakdown reveals a more detailed picture. MinerU-Diffusion excels on financial reports — 0.0053 with GT Layout, the best result among all models. Strong results on textbooks (0.0316) and exam papers (0.0281). Weakest performance on handwritten notes (0.1618 without GT Layout) and slides (0.0440): these are where non-standard layouts require precise layout detection, which remains the main bottleneck.
Summary
MinerU-Diffusion is the first diffusion VLM to compete with the best autoregressive models on real OCR benchmarks while being significantly faster. Compared to MinerU2.5, the new model is larger and marginally behind in absolute accuracy figures, but more robust to semantic disruptions in documents — as confirmed by Semantic Shuffle — and faster under high load. The authors consider the diffusion approach fundamentally better suited for OCR: text in a document is a deterministic mapping of visual content, not probabilistic language generation.